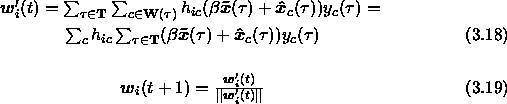The linear reconstruction mapping in equation 3.8 can be
used to derive the learning rule as explained in
section 2.1. The parameters of the network are the
weight vectors ![]() and the learning can be derived by
gradient descent of the quadratic reconstruction error. The outputs
of the network approximately minimise the same error function and
therefore the derivatives of the outputs can be ignored as in
equation 2.2.
and the learning can be derived by
gradient descent of the quadratic reconstruction error. The outputs
of the network approximately minimise the same error function and
therefore the derivatives of the outputs can be ignored as in
equation 2.2.
We would like our network to learn sparse codes but, as has been noted
before, linear reconstruction does not promote sparsity in any way.
We know that the system will give the best reconstruction for input
when all the neurons participate in the representation. If all the
correlations ![]() between the weight
vectors were negative or zero then the neurons would have no
competition and they all could participate in the representation.
Therefore, if we only minimised the linear reconstruction error
defined by equation 3.8, the correlations between weight
vectors would decrease until all competition would vanish. Then
between the weight
vectors were negative or zero then the neurons would have no
competition and they all could participate in the representation.
Therefore, if we only minimised the linear reconstruction error
defined by equation 3.8, the correlations between weight
vectors would decrease until all competition would vanish. Then ![]() would automatically mean
would automatically mean ![]() , and the code would not be
sparse at all.
, and the code would not be
sparse at all.
In order to learn sparse codes, we have to make a minor, biologically plausible addition to the learning rule. The result will be a combination of gradient descent of reconstruction error and use of neighbourhoods as in SOM [Kohonen, 1995]. If we only minimised the linear reconstruction error, the weight vectors would be pulled away from each other. The use of neighbourhoods introduces an opposing force which tries to turn the vectors more parallel. Those directions where input density is large get more weight vectors, and the resolution of the representation will be proportionally sharper. This result is qualitatively similar to that with SOM algorithm [Ritter and Schulten, 1986]. (For more information about SOM see the Master's Thesis of Jaakko Hollmén).
We shall first derive the first part of the learning rule by using
gradient descent. In order to do this, we have to find the gradient
of the quadratic reconstruction error ![]() with respect to the weight vectors
with respect to the weight vectors ![]() , which are the
parameters of the network.
, which are the
parameters of the network.
![]()
Here the reconstruction error ![]() . The last step follows from equation 2.2 as
explained in the beginning of this section. The standard gradient
descent learning rule would be
. The last step follows from equation 2.2 as
explained in the beginning of this section. The standard gradient
descent learning rule would be
Here ![]() is the learning rate governing the length of steps
taken in the descending direction of the gradient.
is the learning rate governing the length of steps
taken in the descending direction of the gradient.
The second part of the learning rule will look a bit similar to SOM
learning rule [Kohonen, 1995]. SOM is a vector quantisation
algorithm and is derived using the restriction that exactly one of the
outputs is one and the rest are zero. The main difference between SOM
and most other VQ algorithms is the use of neighbourhoods in adaptation.
In addition to adapting the winning neuron, also its neighbours are
adapted. In SOM algorithm, the learning rule for the model vectors
![]() is
is
![]()
The amount of adaptation due to the cooperation is governed by the
neighbourhood function
![]() . The reconstruction of input for each neuron in
SOM is
. The reconstruction of input for each neuron in
SOM is ![]() . There is also only one winner
c and thus
. There is also only one winner
c and thus ![]() .
Therefore the learning rule could also be written
.
Therefore the learning rule could also be written
Here the weight vector is adapted in the direction of reconstruction
error ![]() plus the direction of the reconstruction
plus the direction of the reconstruction
![]() . In our case there can be many winners and for each
of them the reconstruction
. In our case there can be many winners and for each
of them the reconstruction ![]() is
different.
is
different.
We can combine the use of neighbourhoods in equation 3.16 and the reconstruction error minimisation in equation 3.14 and sum the adaptations over all winners.
![]()
We have introduced a coefficient ![]() , which can be used to
regulate the ratio between adaptation due to the reconstruction error
minimisation and adaptation due to the cooperation in the
neighbourhood. The weight vectors have to be normalised after each
adaptation. Due to the normalisation we can drop away the term
, which can be used to
regulate the ratio between adaptation due to the reconstruction error
minimisation and adaptation due to the cooperation in the
neighbourhood. The weight vectors have to be normalised after each
adaptation. Due to the normalisation we can drop away the term
![]() . It has the same direction as
. It has the same direction as ![]() and
therefore normalisation cancels its affect anyway.
and
therefore normalisation cancels its affect anyway.
The determination of winning ratios in equation 3.6
required knowledge of the correlations ![]() between weight
vectors. It would be quite a heavy operation to compute the
correlations after each input, and therefore we shall use the batch
version of the adaptation algorithm. The adaptations are summed over
a set
between weight
vectors. It would be quite a heavy operation to compute the
correlations after each input, and therefore we shall use the batch
version of the adaptation algorithm. The adaptations are summed over
a set ![]() of indices in the batch. Also the normalisation of
weight vectors can be done after each batch. When using the batch
version of the learning rule, the learning rate parameter
of indices in the batch. Also the normalisation of
weight vectors can be done after each batch. When using the batch
version of the learning rule, the learning rate parameter ![]() can
be dropped away.
can
be dropped away.
Here we supposed that the neighbourhood function ![]() does not
change in time. As can be seen from the equation, the use of batch
version enables us to move the summation over the neighbourhoods
outside the batch, and therefore it needs to be done only once after
each batch. On the other hand, writing the summations in this order
prevents us from adapting only the set of winners and their
neighbours. If the batch is sufficiently long, there are so many
winners, however, that this order is computationally more efficient.
does not
change in time. As can be seen from the equation, the use of batch
version enables us to move the summation over the neighbourhoods
outside the batch, and therefore it needs to be done only once after
each batch. On the other hand, writing the summations in this order
prevents us from adapting only the set of winners and their
neighbours. If the batch is sufficiently long, there are so many
winners, however, that this order is computationally more efficient.