


Next: Computational Performance
Up: Principal Component Analysis for
Previous: Variational Bayesian Learning
Collaborative filtering is the task of predicting preferences (or
producing personal recommendations) by using other people's
preferences. The Netflix problem [13] is such a task. It
consists of movie ratings given by 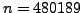 customers to
customers to 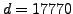 movies. There are
movies. There are
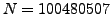 ratings from 1 to 5 given, and the
task is to predict 2817131 other ratings among the same group of
customers and movies. 1408395 of the ratings are reserved for
validation (or probing). Note that the 98.8% of the values are thus
missing. We tried to find
ratings from 1 to 5 given, and the
task is to predict 2817131 other ratings among the same group of
customers and movies. 1408395 of the ratings are reserved for
validation (or probing). Note that the 98.8% of the values are thus
missing. We tried to find 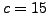 principal components from the data
using a number of methods.
principal components from the data
using a number of methods.![[*]](file:/usr/share/latex2html/icons/footnote.png) The mean rating was subtracted for each movie and robust estimation of
the mean was used for the movies with few ratings.
The mean rating was subtracted for each movie and robust estimation of
the mean was used for the movies with few ratings.
Figure 2:
Left: Learning curves for unregularized PCA
(Section 3)
applied to the Netflix data: Root mean
square error on the training data is plotted against computation
time in hours. Runs are given for two values of the speed-up
parameter 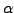 and marks are plotted after every 50 iterations.
For comparison, the training errors for the imputation algorithm and the
EM algorithm are shown. The time scale is linear below 1 and
logarithmic above 1.
Right: The root mean square error on the validation data
from the Netflix problem during runs of several algorithms: basic PCA
(Section 3) with two values of ,
regularized PCA (Section 4) and
VB (Section 4). VB1 has
and marks are plotted after every 50 iterations.
For comparison, the training errors for the imputation algorithm and the
EM algorithm are shown. The time scale is linear below 1 and
logarithmic above 1.
Right: The root mean square error on the validation data
from the Netflix problem during runs of several algorithms: basic PCA
(Section 3) with two values of ,
regularized PCA (Section 4) and
VB (Section 4). VB1 has 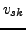 fixed to large values
while VB2 updates all the parameters.
The curves clearly reveal overlearning for unregularized PCA.
fixed to large values
while VB2 updates all the parameters.
The curves clearly reveal overlearning for unregularized PCA.
|
|
Subsections
Next: Computational Performance
Up: Principal Component Analysis for
Previous: Variational Bayesian Learning
Tapani Raiko
2007-07-16
![\includegraphics[width=.48\textwidth,trim=7mm 5mm 8mm 3mm,clip]{learningcurves_ecml.eps}](img85.png)
![\includegraphics[width=.48\textwidth,trim=7mm 5mm 8mm 3mm,clip]{lcprobe_ecml.eps}](img86.png)