- ...
rule1
- The subscripts of all pdf's are assumed to be the same
as their arguments, and are omitted for keeping the notation simpler.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ...
probability2
- More accurately, one could show the dependence on
the chosen model
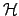 by conditioning all the pdf's in (1)
by :
by conditioning all the pdf's in (1)
by :
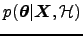 ,
,
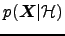 , etc. We have here dropped
also the dependence on out for notational simplicity. See
Valpola02NC for a somewhat more complete discussion
of Bayesian methods and ensemble learning.
, etc. We have here dropped
also the dependence on out for notational simplicity. See
Valpola02NC for a somewhat more complete discussion
of Bayesian methods and ensemble learning.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... form3
- Note that constants are dropped out since they do not depend on
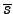 or
or
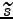 .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... dimensions4
- Higher
dimensional SOMs become quickly intractable due to exponential number
of parameters.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ...
nodes.5
- Note that delay node only rewires connections so it does not
affect the formulas.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.