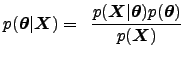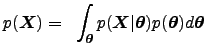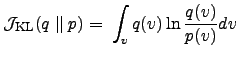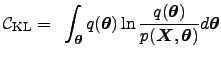Denote by
![]() the set of all model parameters and other unknown variables
that we wish to estimate from a
given data set
the set of all model parameters and other unknown variables
that we wish to estimate from a
given data set
![]() . The posterior probability density
. The posterior probability density
![]() of the parameters
of the parameters
![]() given the data
given the data
![]() is obtained from Bayes
rule1
is obtained from Bayes
rule1
Variational Bayesian learning
Barber98NNML,Hinton93COLT,Lappal-Miskin00,MacKay95Ens,MacKay03
is a fairly recently introduced Hinton93COLT,MacKay95Ens approximate fully Bayesian method,
which has become popular because of its good properties. Its key idea is
to approximate the exact posterior distribution
![]() by
another distribution
by
another distribution
![]() that is computationally
easier to handle. The approximating distribution is usually chosen to
be a product of several independent distributions, one for each parameter
or a set of similar parameters.
that is computationally
easier to handle. The approximating distribution is usually chosen to
be a product of several independent distributions, one for each parameter
or a set of similar parameters.
Variational Bayesian learning employs the Kullback-Leibler (KL) information
(divergence) between two probability distributions ![]() and
and ![]() .
The KL information is defined by the cost function Haykin98
.
The KL information is defined by the cost function Haykin98
The KL information is used to minimise the
misfit between the actual posterior pdf
![]() and its
parametric approximation
and its
parametric approximation
![]() . However, the exact KL information
. However, the exact KL information
![]() between these two densities does
not yet yield a practical cost function, because the normalising term
between these two densities does
not yet yield a practical cost function, because the normalising term
![]() needed in computing
needed in computing
![]() cannot usually be evaluated.
cannot usually be evaluated.
Therefore, the cost function used in variational Bayesian learning is defined Hinton93COLT,MacKay95Ens
In addition, the cost function
![]() provides a bound for the evidence
provides a bound for the evidence
![]() . Since
. Since
![]() is always nonnegative, it follows
directly from (4) that
is always nonnegative, it follows
directly from (4) that
It is worth noting that variational Bayesian ensemble learning can be derived from information-theoretic minimum description length coding as well Hinton93COLT. Further considerations on such arguments, helping to understand several common problems and certain aspects of learning, have been presented in a recent paper Honkela04TNN.
The dependency structure between the parameters in our method is the same as in
Bayesian networks Pearl88. Variables are seen as nodes of a graph. Each
variable is conditioned by its parents. The difficult part in the
cost function is the expectation
![]() which is
computed over the approximation
which is
computed over the approximation
![]() of the posterior pdf. The
logarithm splits the product of simple terms into a sum. If each of
the simple terms can be computed in constant time, the overall
computational complexity is linear.
of the posterior pdf. The
logarithm splits the product of simple terms into a sum. If each of
the simple terms can be computed in constant time, the overall
computational complexity is linear.
In general, the computation time is constant if the parents are
independent in the posterior pdf approximation
![]() . This condition
is satisfied if the joint distribution of the parents in
. This condition
is satisfied if the joint distribution of the parents in
![]() decouples into the product of the approximate distributions of the
parents. That is, each term in
decouples into the product of the approximate distributions of the
parents. That is, each term in
![]() depending on the parents depends
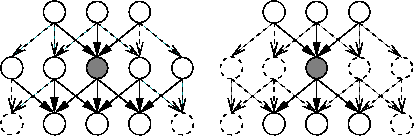
only on one parent. The independence requirement is violated if
any variable receives inputs from a latent variable through multiple paths
or from two latent variables which are dependent in
depending on the parents depends
only on one parent. The independence requirement is violated if
any variable receives inputs from a latent variable through multiple paths
or from two latent variables which are dependent in
![]() , having a
non-factorisable joint distribution there.
Figure 1 illustrates the flow of information
in the network in these two qualitatively different cases.
, having a
non-factorisable joint distribution there.
Figure 1 illustrates the flow of information
in the network in these two qualitatively different cases.
 |
Our choice for
![]() is a multivariate Gaussian density with a
diagonal covariance matrix. Even this crude approximation is adequate
for finding the region where the mass of the actual posterior density
is concentrated. The mean values of the components of the Gaussian
approximation provide reasonably good point estimates of the
corresponding parameters or variables, and the respective variances
measure the reliability of these estimates. However, occasionally the
diagonal Gaussian approximation can be too crude. This problem has
been considered in context with independent component analysis in
Ilin03ICA, giving means to remedy the situation.
is a multivariate Gaussian density with a
diagonal covariance matrix. Even this crude approximation is adequate
for finding the region where the mass of the actual posterior density
is concentrated. The mean values of the components of the Gaussian
approximation provide reasonably good point estimates of the
corresponding parameters or variables, and the respective variances
measure the reliability of these estimates. However, occasionally the
diagonal Gaussian approximation can be too crude. This problem has
been considered in context with independent component analysis in
Ilin03ICA, giving means to remedy the situation.
Taking into account posterior dependencies makes the posterior pdf
approximation
![]() more accurate, but also usually increases the
computational load significantly. We have earlier considered networks with
multiple computational paths in several papers,
for example Lappalainen00,Valpola02IJCNN,Valpola02NC,Valpola03IEICE.
The computational load of variational Bayesian learning then becomes roughly
quadratically proportional to the number of unknown variables in the
MLP network model used in Lappalainen00,Valpola03IEICE,Honkela05NIPS.
more accurate, but also usually increases the
computational load significantly. We have earlier considered networks with
multiple computational paths in several papers,
for example Lappalainen00,Valpola02IJCNN,Valpola02NC,Valpola03IEICE.
The computational load of variational Bayesian learning then becomes roughly
quadratically proportional to the number of unknown variables in the
MLP network model used in Lappalainen00,Valpola03IEICE,Honkela05NIPS.
The building blocks (nodes) introduced in this paper together with associated structural constraints provide effective means for combating the drawbacks mentioned above. Using them, updating at each node takes place locally with no multiple paths. As a result, the computational load scales linearly with the number of estimated quantities. The cost function and the learning formulas for the unknown quantities to be estimated can be evaluated automatically once a specific model has been selected, that is, after the connections between the blocks used in the model have been fixed. This is a very important advantage of the proposed block approach.