Miquel Perello Nieto
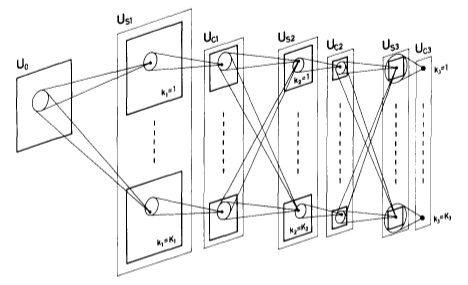
Figure : Schematic diagram illustrating the interconections between layers in the Neocognitron [K. Fukushima 1980]
Merging chrominance and luminance in early, medium and late fusion using Convolutional Neural Networks
The field of Machine Learning has received extensive attention in recent years. More particularly, computer vision problems have got abundant consideration as the use of images and pictures in our daily routines is growing.
The classification of images is one of the most important tasks that can be used to organize, store, retrieve, and explain pictures. In order to do that, researchers have been designing algorithms that automatically detect objects in images. During last decades, the common approach has been to create sets of features -- manually designed -- that could be exploited by image classification algorithms. More recently, researchers designed algorithms that automatically learn these sets of features, surpassing state-of-the-art performances.
However, learning optimal sets of features is computationally expensive and it can be relaxed by adding prior knowledge about the task, improving and accelerating the learning phase. Furthermore, with problems with a large feature space the complexity of the models need to be reduced to make it computationally tractable (e.g. the recognition of human actions in videos).
Consequently, we propose to use multimodal learning techniques to reduce the complexity of the learning phase in Artificial Neural Networks by incorporating prior knowledge about the connectivity of the network. Furthermore, we analyze state-of-the-art models for image classification and propose new architectures that can learn a locally optimal set of features in an easier and faster manner.
In this thesis, we demonstrate that merging the luminance and the chrominance part of the images using multimodal learning techniques can improve the acquisition of good visual sets of features. We compare the validation accuracy of several models and we demonstrate that our approach outperforms the basic model with statistically significant results.
Documents: Thesis pdf, Slides pdf


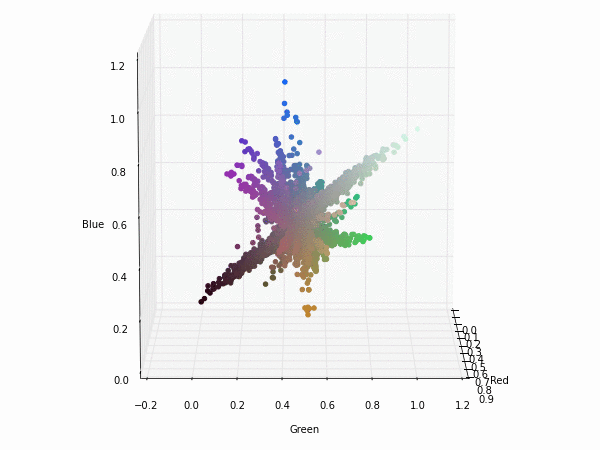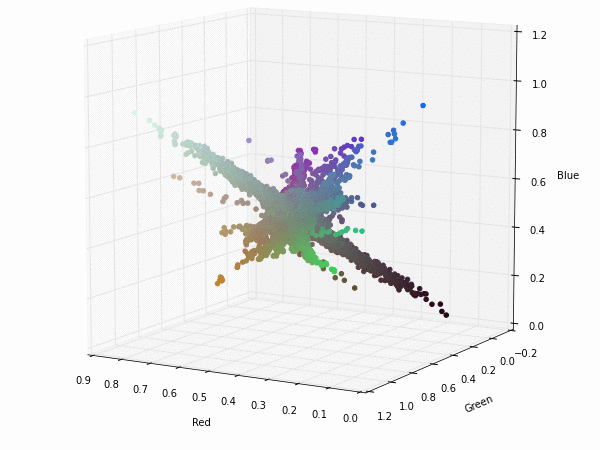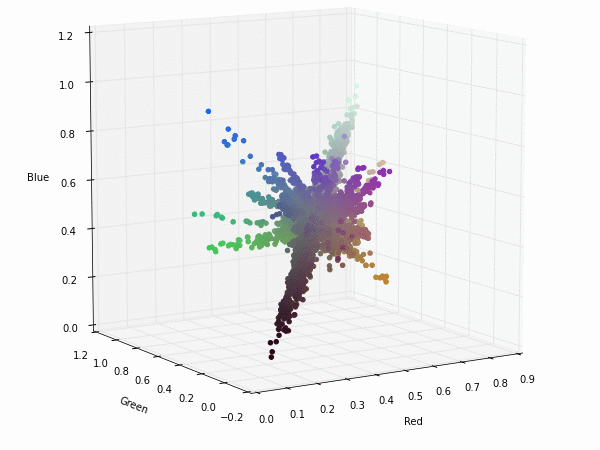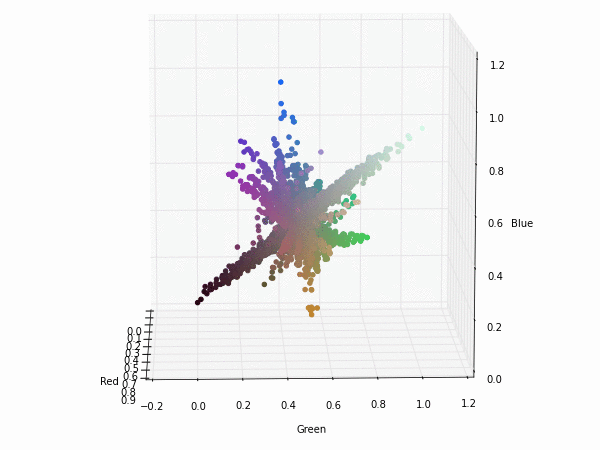
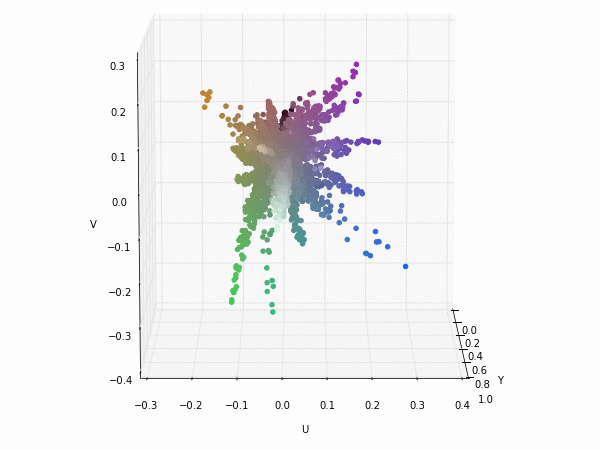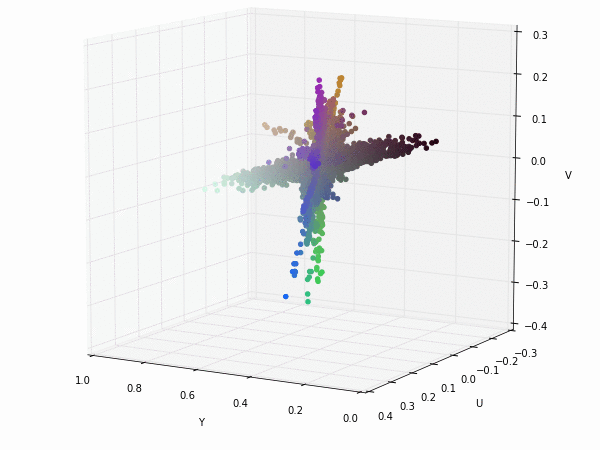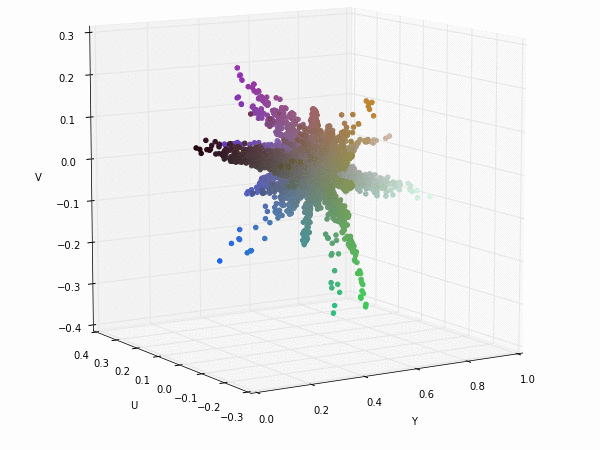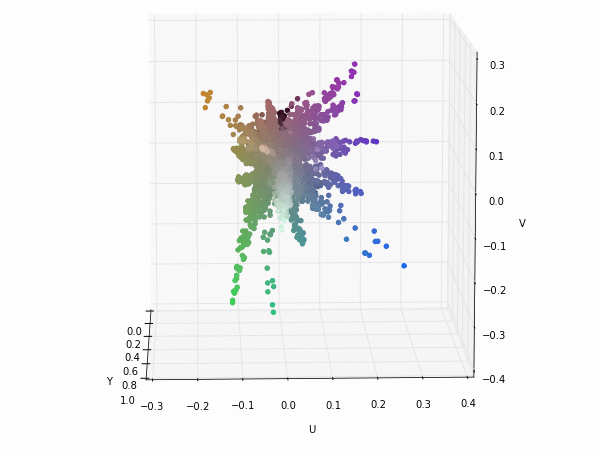
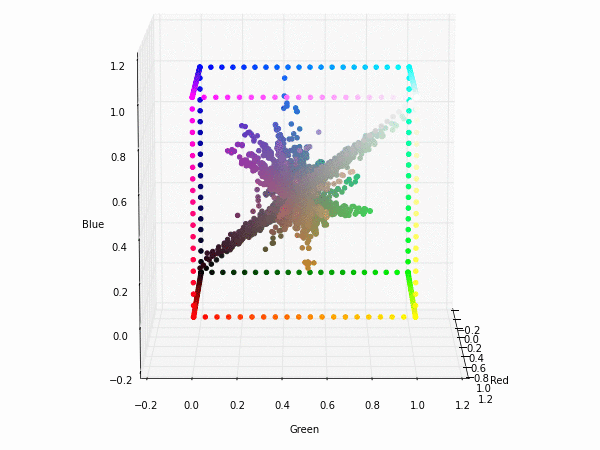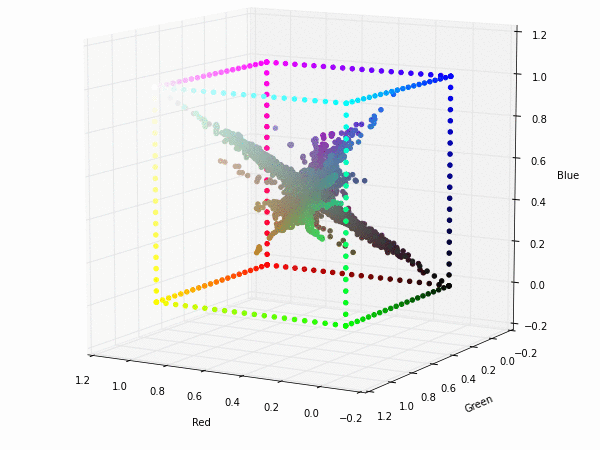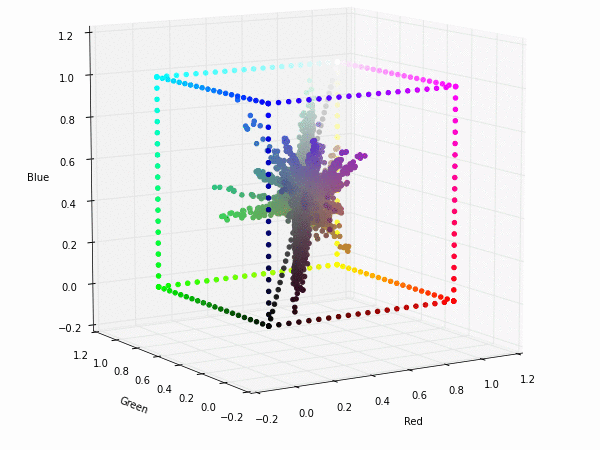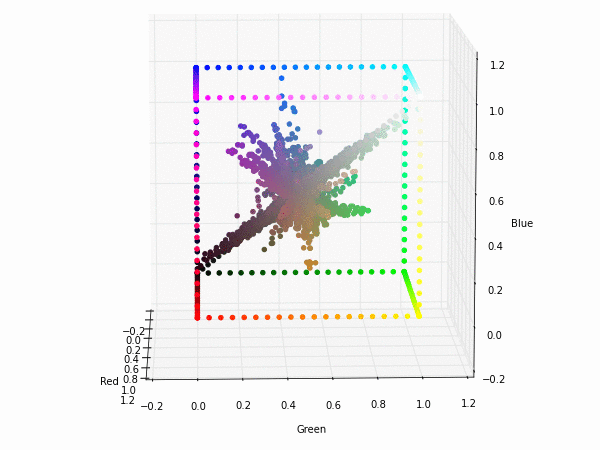
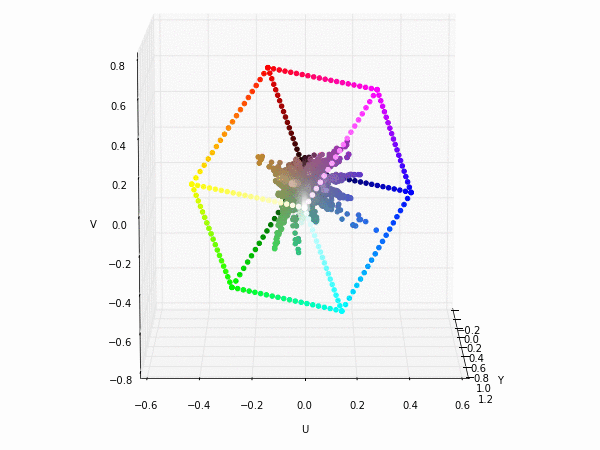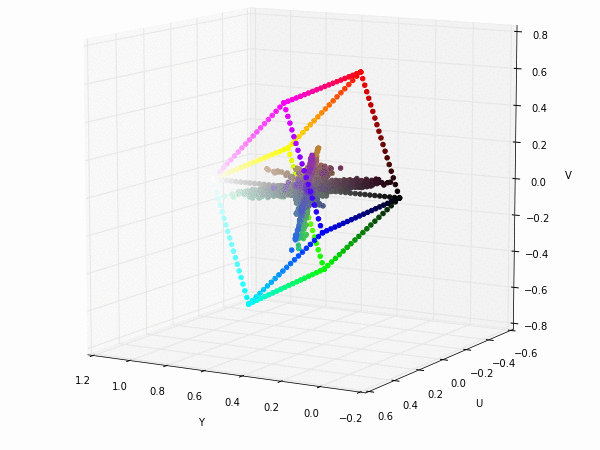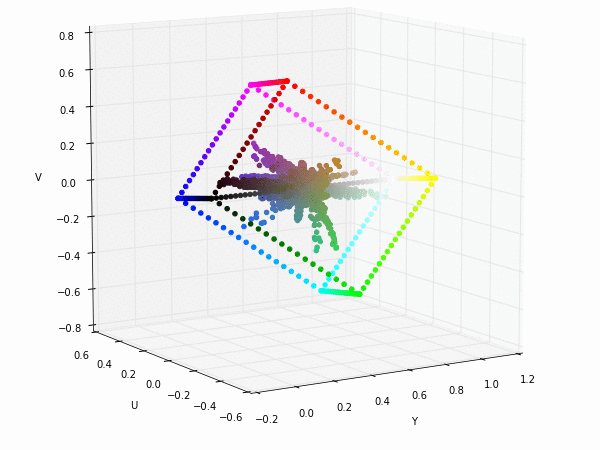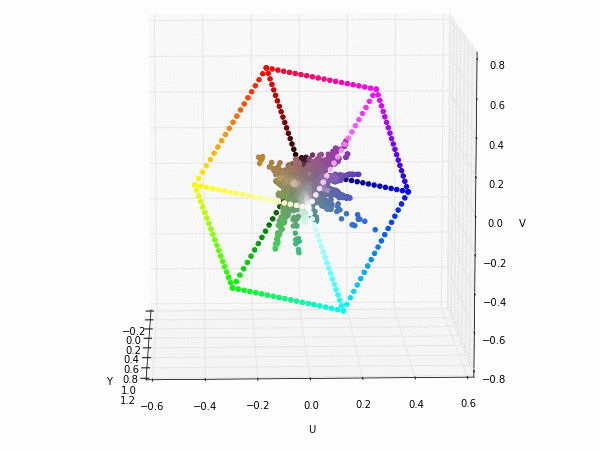
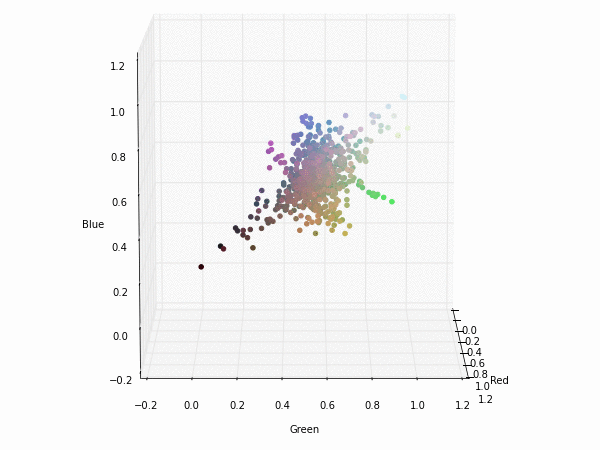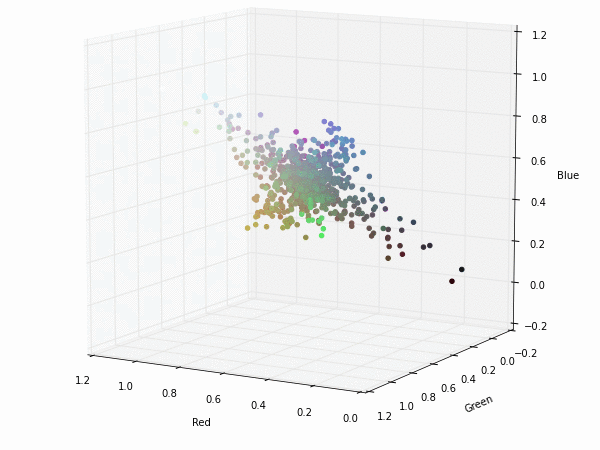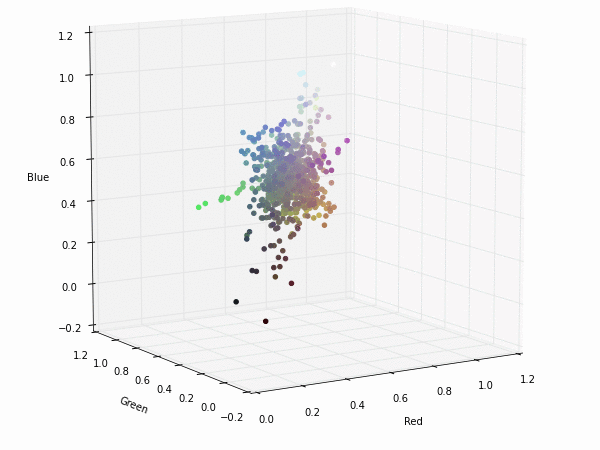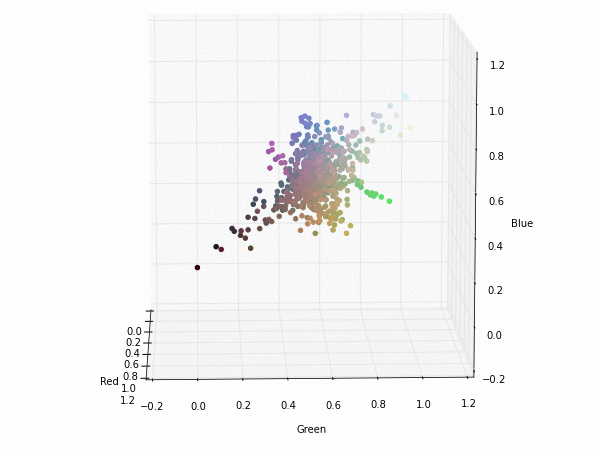
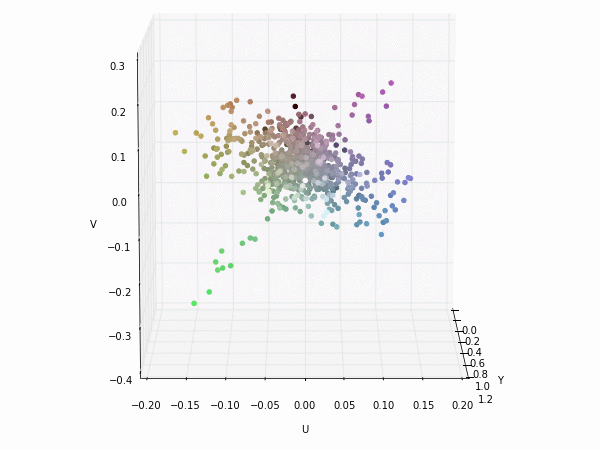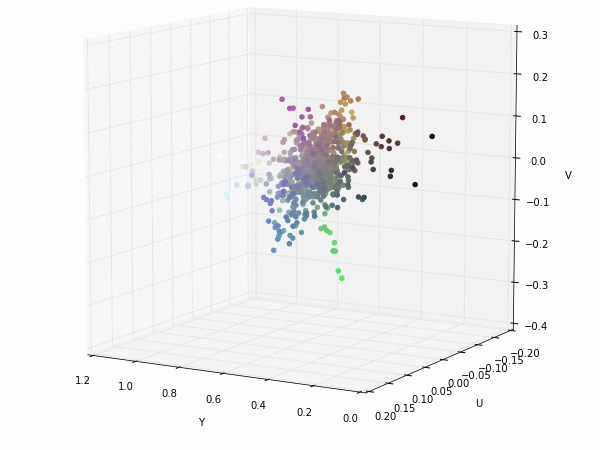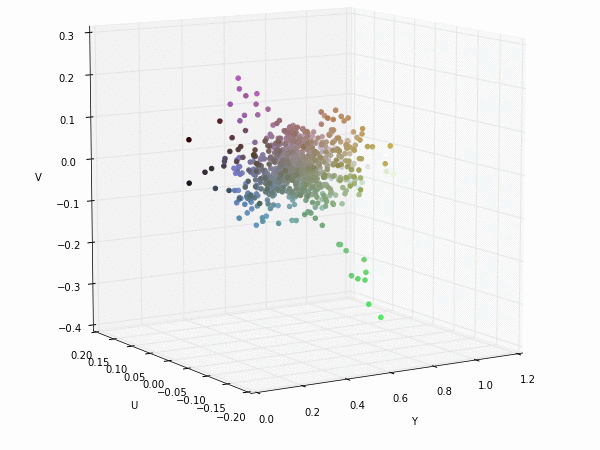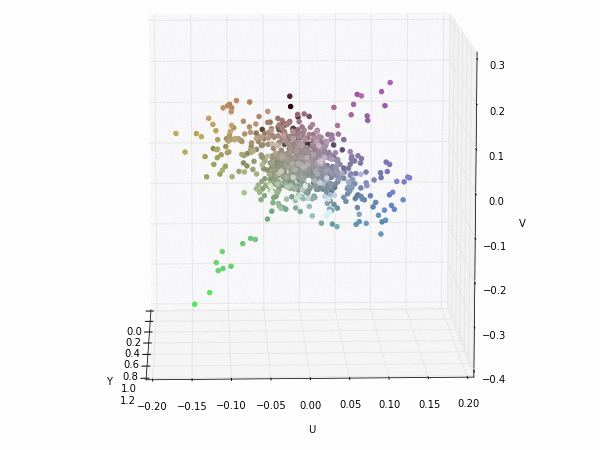
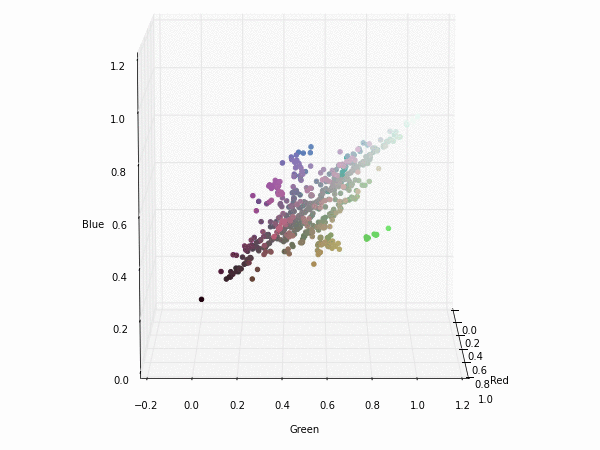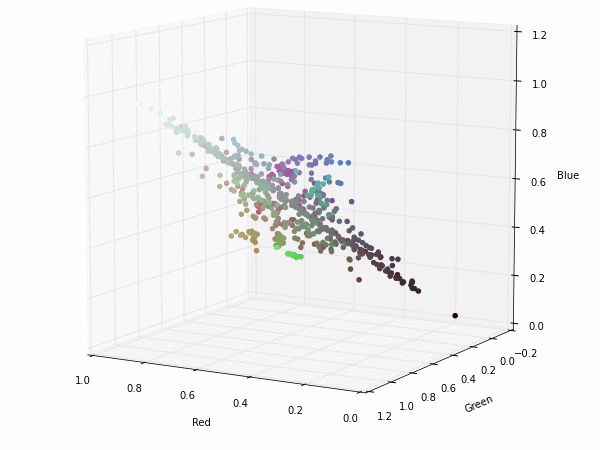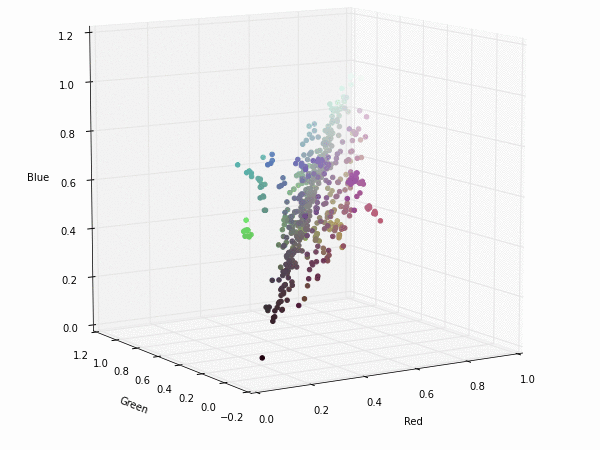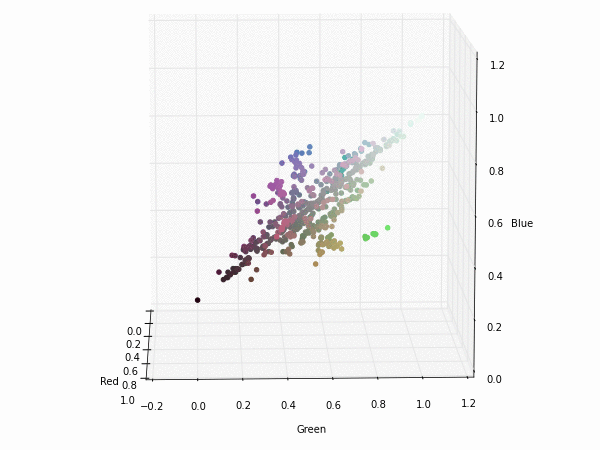
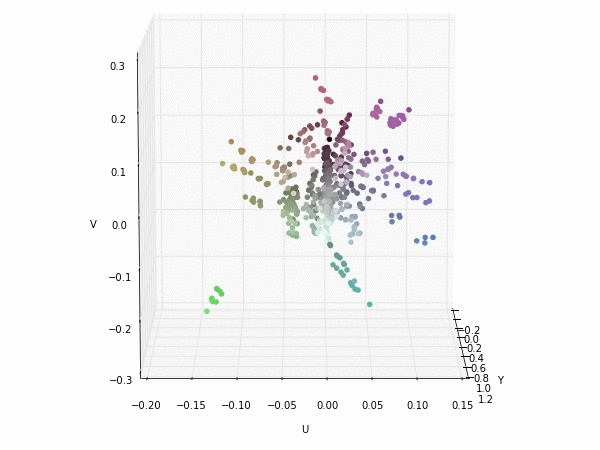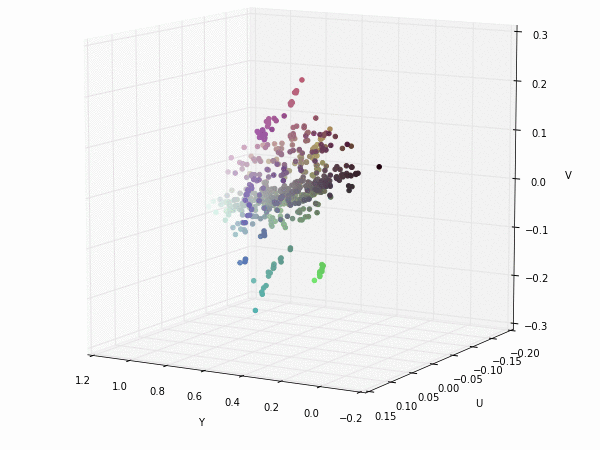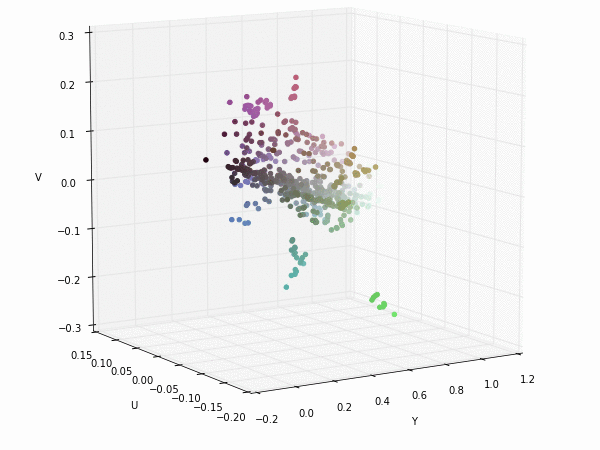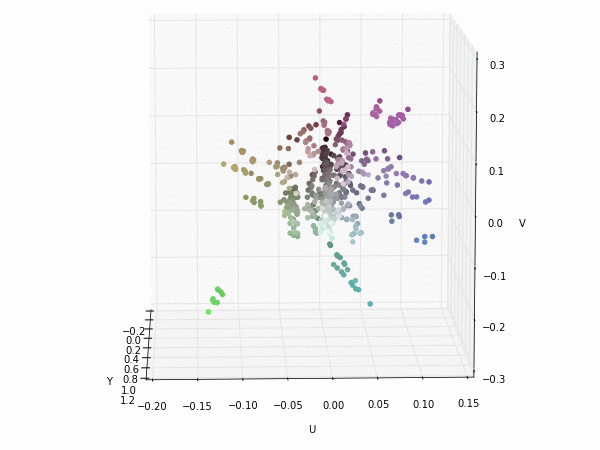
Colorspace transformations
RGB cubes represented in different colorspace transformations of the RGB channels in 3D. The 3D gifs can be seen if you click on the desired image . The size of each .GIF is ~11MB.
RGB and YUV
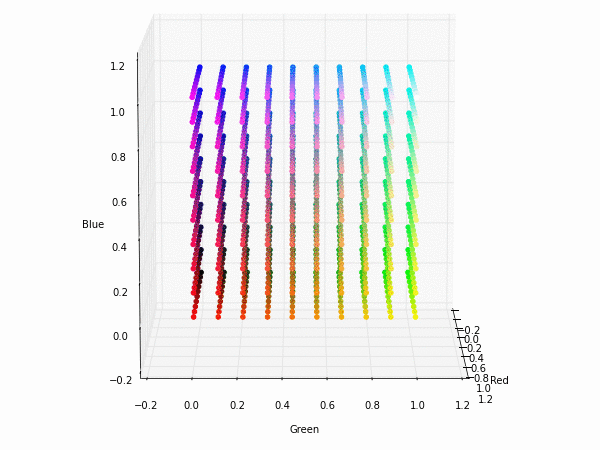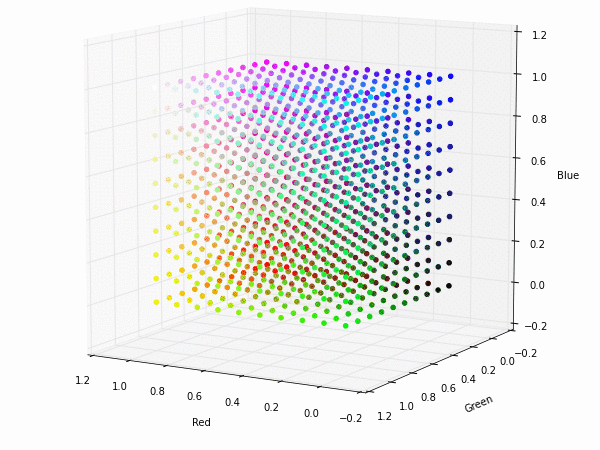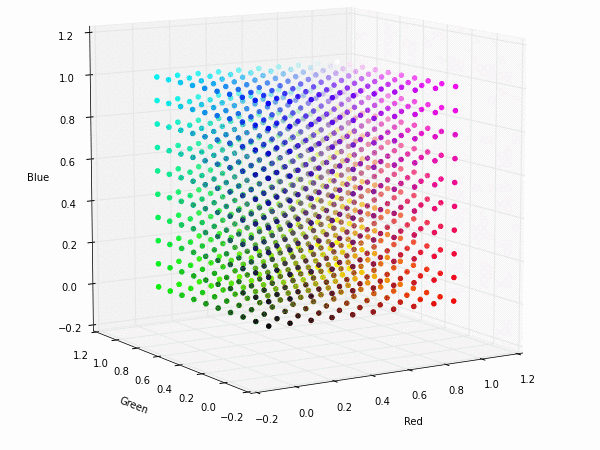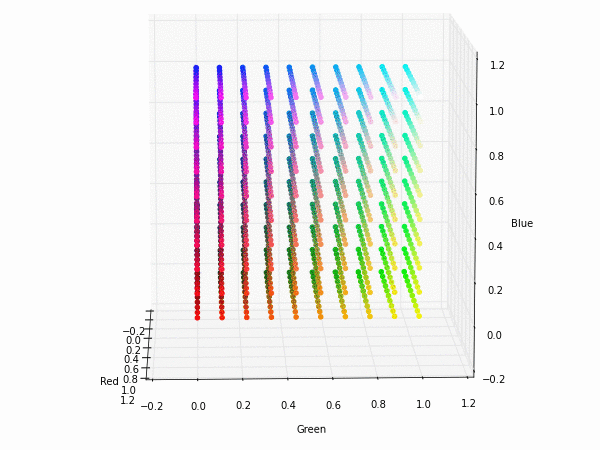
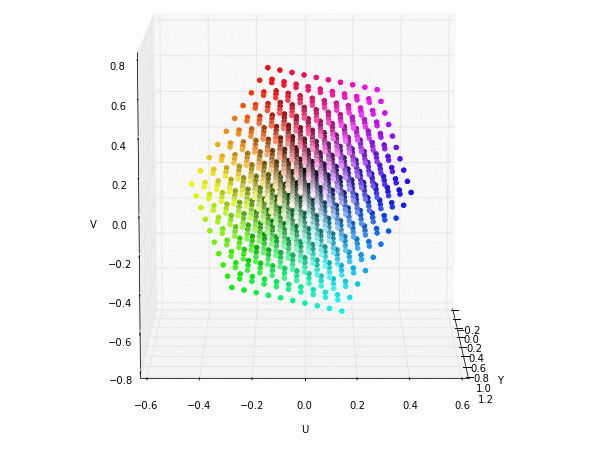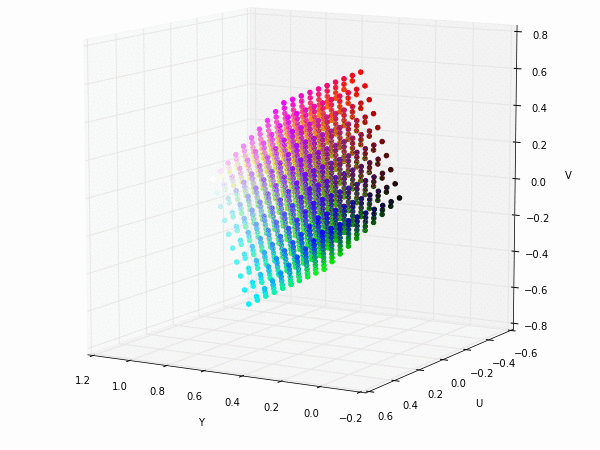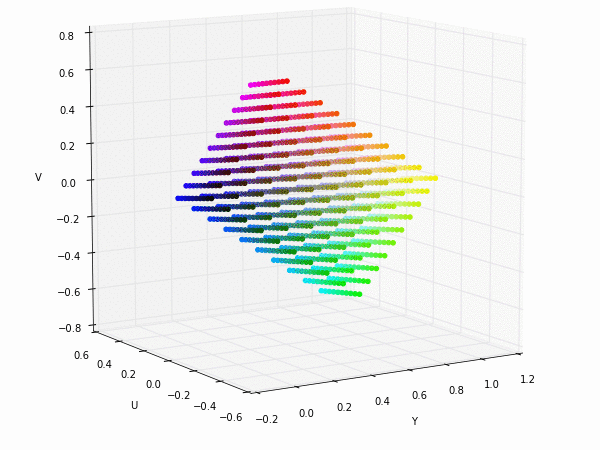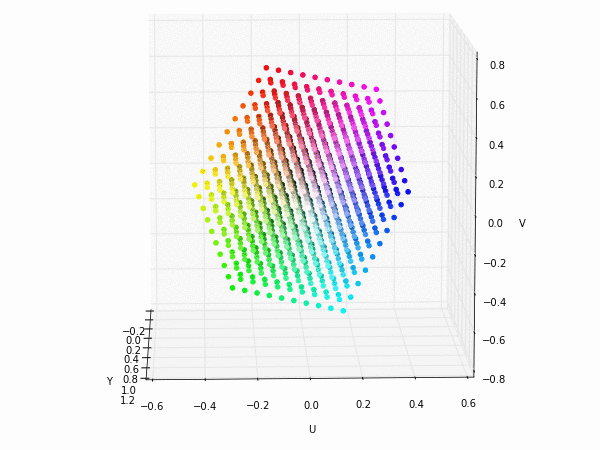
XYZ and YIQ
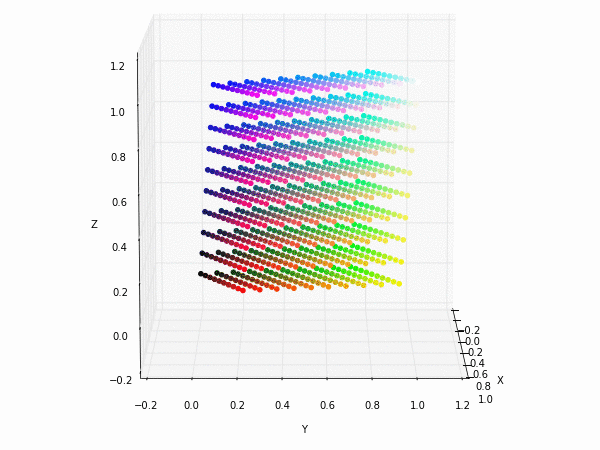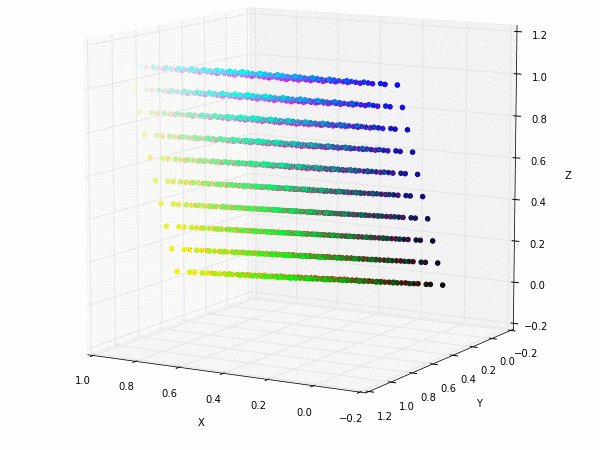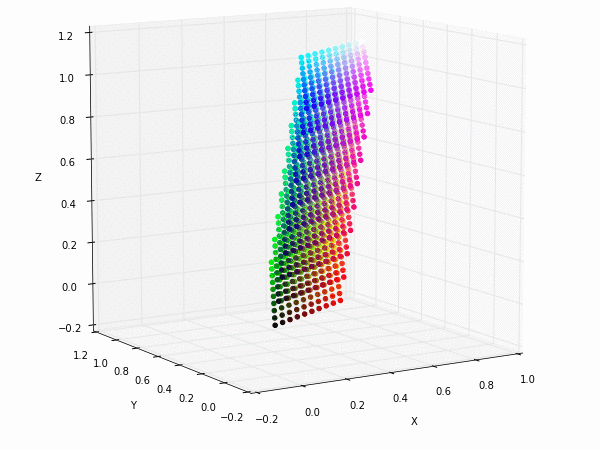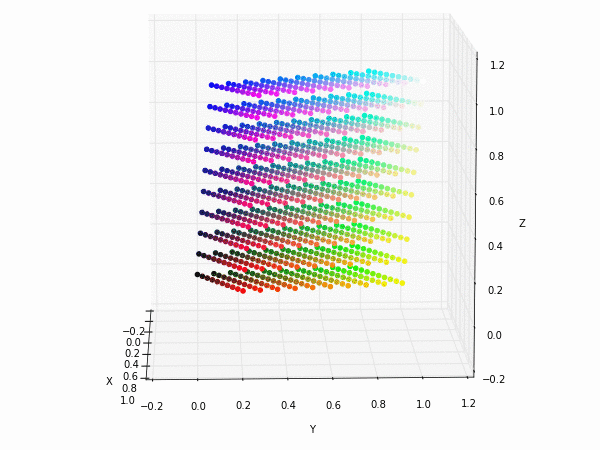

Alexnet first Convolution filters in original RGB and transformed to YUV
It is possible to see that the principal component is focused on the luminance (or luma Y' axis), while the chrominance is equaly distributed along U and V channels
The same visualization with the boundaries and the diagonal of the RGB colorspace.
Cifar10 Berkeley first Convolution filters in original RGB and transformed to YUV
In that case the principal component is not very clean but experimental results says that it do not hurt to reduce the number of connections separating the luminance from the chrominance channels.
Very Deep CNN (19conv) first Convolution filters in original RGB and transformed to YUV
Datasets
This section contains a list of useful datasets. These datasets and more about computer vision can be found in : cvpapersImageNet
ImageNet is an image database organized according to the WordNet hierarchy (currently only the nouns), in which each node of the hierarchy is depicted by hundreds and thousands of images. Currently we have an average of over five hundred images per node. We hope ImageNet will become a useful resource for researchers, educators, students and all of you who share our passion for pictures.
[show more info]Video classification USAA dataset
"The USAA dataset includes 8 different semantic class videos which are home videos of social occassions such e birthday party, graduation party,music performance, non-music performance, parade, wedding ceremony, wedding dance and wedding reception which feature activities of group of people. It contains around 100 videos for training and testing respectively. Each video is labeled by 69 attributes. The 69 attributes can be broken down into five broad classes: actions, objects, scenes, sounds, and camera movement. It can be used for evaluating approaches for video classification, N-shot and zero-shot learning, multi-task learning, attribute/concept-annotation, attribute/concepts-modality prediction, suprising attributes/concepts discovery, and latent-attribute(concepts) discovery etc."
[show more info]
YouTube Faces
"The data set contains 3,425 videos of 1,595 different people. All the videos were downloaded from YouTube. An average of 2.15 videos are available for each subject. The shortest clip duration is 48 frames, the longest clip is 6,070 frames, and the average length of a video clip is 181.3 frames."
[show more info]
Hollywood-2 Human Actions and Scenes dataset
"Hollywood-2 datset contains 12 classes of human actions and 10 classes of scenes distributed over 3669 video clips and approximately 20.1 hours of video in total. The dataset intends to provide a comprehensive benchmark for human action recognition in realistic and challenging settings. The dataset is composed of video clips extracted from 69 movies, it contains approximately 150 samples per action class and 130 samples per scene class in training and test subsets. A part of this dataset was originally used in the paper "Actions in Context", Marszałek et al. in Proc. CVPR'09. Hollywood-2 is an extension of the earlier Hollywood dataset."
[show more info]





KTH - Recognition of Human Actions
"The current video database containing six types of human actions (walking, jogging, running, boxing, hand waving and hand clapping) performed several times by 25 subjects in four different scenarios: outdoors s1, outdoors with scale variation s2, outdoors with different clothes s3 and indoors s4 as illustrated below. Currently the database contains 2391 sequences. All sequences were taken over homogeneous backgrounds with a static camera with 25fps frame rate. The sequences were downsampled to the spatial resolution of 160x120 pixels and have a length of four seconds in average."
[show more info]
[ webpage ]
UCF50
UCF50 is an action recognition data set with 50 action categories, consisting of realistic videos taken from youtube. This data set is an extension of YouTube Action data set (UCF11) which has 11 action categories.
Most of the available action recognition data sets are not realistic and are staged by actors. In our data set, the primary focus is to provide the computer vision community with an action recognition data set consisting of realistic videos which are taken from youtube. Our data set is very challenging due to large variations in camera motion, object appearance and pose, object scale, viewpoint, cluttered background, illumination conditions, etc. For all the 50 categories, the videos are grouped into 25 groups, where each group consists of more than 4 action clips. The video clips in the same group may share some common features, such as the same person, similar background, similar viewpoint, and so on. [...]
[show more info]

UCF101
UCF101 is an action recognition data set of realistic action videos, collected from YouTube, having 101 action categories. This data set is an extension of UCF50 data set which has 50 action categories.
With 13320 videos from 101 action categories, UCF101 gives the largest diversity in terms of actions and with the presence of large variations in camera motion, object appearance and pose, object scale, viewpoint, cluttered background, illumination conditions, etc, it is the most challenging data set to date. As most of the available action recognition data sets are not realistic and are staged by actors, UCF101 aims to encourage further research into action recognition by learning and exploring new realistic action categories. [...]
[show more info]
Workshops
ILSVRC - ImageNet Large Scale Visual Recognition Challenge
This challenge evaluates algorithms for object detection and image classification at large scale.
[show more info]THUMOS'13 - ICCV Workshop on Action Recognition with a Large Number of Classes
THUMOS: The First International Workshop on Action Recognition with a Large Number of Classes, in conjunction with ICCV '13, Sydney, Australia.
[show more info][ webpage ]
4DMOD - 14th International Conference on Computer Vision
4DMOD is the workshop on the modeling of dynamic scenes. Modeling shapes that evolve over time, analyzing and interpreting their motion is a subject of increasing interest of many research communities including the computer vision, the computer graphics and the medical imaging community. Following the 1st edition in 2011, the purpose of this workshop is to provide a venue for researchers, from various communities, working in the field of dynamic scene modeling from various modalities to present their work, exchange ideas and identify challenging issues in this domain. Contributions are sought on new and original research on any aspect of 4D Modeling. Possible topics include, but are not limited to :
[show more info][ webpage ]
TRECVID
The main goal of the TREC Video Retrieval Evaluation (TRECVID) is to promote progress in content-based analysis of and retrieval from digital video via open, metrics-based evaluation. TRECVID is a laboratory-style evaluation that attempts to model real world situations or significant component tasks involved in such situations.
[show more info][ webpage ]
Comparison of CNN libraries
There are several libraries that can be used for training CNN.Theano
"Theano is a Python library that allows you to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently."
Pylearn2
"Pylearn2 is a machine learning library. Most of its functionality is built on top of Theano. This means you can write Pylearn2 plugins (new models, algorithms, etc) using mathematical expressions, and theano will optimize and stabilize those expressions for you, and compile them to a backend of your choice (CPU or GPU)."
Caffe
"Caffe is a framework for convolutional neural network algorithms, developed with speed in mind. It was created by Yangqing Jia, and is in active development by the Berkeley Vision and Learning Center."
OverFeat
"OverFeat is an image recognizer and feature extractor built around a convolutional network.
The OverFeat convolutional net was trained on the ImageNet 1K dataset. It participated in the ImangeNet Large Scale Recognition Challenge 2013 under the name “OverFeat NYU”.
This release provides C/C++ code to run the network and output class probabilities or feature vectors. It also includes a webcam-based demo."
[ webpage | GitHub ]Some comparisons

References with abstract sorted by year
These are some references I read during my master's thesis. They contain the original abstract and my own notes. Some of the notes are textual parts of the original references, however other notes are just my own interpretation. It is also avaliable in html and LaTeX format : [ html | pdf ]
[+] Press this symbol on the papers title to see the abstract and additional information
1700
-
An essay concerning human understanding [Locke1700] [+]
-
Observations on man, his frame, his duty, and his expectations [Hartley1749] [+]
-
Mind and body. The theories of their relation [Bain1873] [+]
-
The principles of psychology [WilliamJames1890] [+]
-
Histologie du systeme nerveux de l'homme & des vertebres [Cajal1909] [+]
-
A history of the association psychology [HowardC.Warren1921] [+]
-
A logical calculus of the ideas immanent in nervous activity [McCulloch1943] [+]
-
First Draft of a Report on the EDVAC [Neumann1945] [+]
-
On a test of whether one of two random variables is stochastically larger than the other [Mann1947] [+]
-
Cybernetics or Control and Communication in the Animal and the Machine [Wiener1948] [+]
-
The Orgamization of Behavior a Neuropsychological Theory [Hebb1949] [+]
-
Equation of State Calculations by Fast Computing Machines [Metropolis1953] [+]
-
Communication theory and cybernetics [Gabor1954] [+]
-
Simulation of self-organizing systems by digital computer [Farley1954] [+]
-
Theory of neural-analog reinforcement systems and its application to the brain model problem [Minsky1954] [+]
-
Memory: The Analogy with Ferromagnetic Hysteresis [Cragg1955] [+]
-
Tests on a cell assembly theory of the action of the brain, using a large digital computer [Rochester1956] [+]
-
Probabilistic logics and the synthesis of reliable organisms from unreliable components [Neumann1956] [+]
-
Conditional probability machines and conditional reflexes [Uttley1956a] [+]
-
Temporal and spatial patterns in a conditional probability machine [Uttley1956] [+]
-
Electrical simulation of some nervous system functional activities. [Taylor1956] [+]
-
The Perceptron, a Perceiving and Recognizing Automaton [Rosenblatt1957] [+]
-
The perceptron: a probabilistic model for information storage and organization in the brain. [Rosenblatt1958] [+]
-
Design for a Brain: The Origin of Adaptive Behavior [Ashby1960] [+]
-
An Adaptive "ADALINE" Neuron Using Chemical "Memistors" [Widrow1960] [+]
-
Principles of neurodynamics. perceptrons and the theory of brain mechanisms [Rosenblatt1961] [+]
-
Receptive fields, binocular interaction and functional architecture in the cat's visual cortex [Hubel1962] [+]
-
On convergence proofs on perceptrons [Novikoff1962] [+]
-
Learning machines: foundations of trainable pattern-classifying systems [Nilsson1965] [+]
-
Theory of self-reproducing automata [Neumann1966] [+]
-
A Theory of Adaptive Pattern Classifiers [Amari1967] [+]
-
Receptive fields and functional architecture of monkey striate cortex [Hubel1968] [+]
-
Perceptrons [Minsky1969] [+]
-
Non-Holographic Associative Memory [Willshaw1969] [+]
-
Non-Holographic Associative Memory [Willshaw1969a] [+]
-
On the uniform convergence of relative frequencies of events to their probabilities [Vapnik1971] [+]
-
A simple neural network generating an interactive memory [Anderson1972] [+]
-
Characteristics of Random Nets of Analog Neuron-Like Elements [Amari1972] [+]
-
Automata Studies: Annals of Mathematics Studies. Number 34 [Shannon1972] [+]
-
Correlation matrix memories [Kohonen1972] [+]
-
Self-organization of orientation sensitive cells in the striate cortex [Malsburg1973] [+]
-
Beyond regression: new tools for prediction and analysis in the behavioral sciences [Werbos1974] [+]
-
A statistical theory of short and long term memory [Little1975] [+]
-
A mechanism for producing continuous neural mappings: ocularity dominance stripes and ordered retino-tectal projections [von1976mechanism] [+]
-
Luminance and opponent-color contributions to visual detection and adaptation and to temporal and spatial integration [King-Smith1976] [+]
-
Neocognitron: A Self-organizing Neural Network Model for a Mechanism of Pattern Recognition Unaffected by Shift in Position [Fukushima1980] [+] my notes
-
A. I. [Bernstein1981] [+] my notes
-
Learning-logic [Parker1985] [+]
-
Neuronlike adaptive elements that can solve difficult learning control problems [Barto1983] [+]
-
Neocognitron: A neural network model for a mechanism of visual pattern recognition [Fukushima1983] [+]
-
Optimization by Simulated Annealing [Kirkpatrick1983] [+]
-
Une procédure d'apprentissage pour réseau a seuil asymmetrique (a Learning Scheme for Asymmetric Threshold Networks) [LeCun1985] [+]
-
A Learning Algorithm for Boltzmann Machines* [Ackley1985] [+]
-
Learning Process in an Asymmetric Threshold Network [Cun1986] [+]
-
Highly parallel, hierarchical, recognition cone perceptual structures [Uhr1987] [+]
-
Parallel networks that learn to pronounce English text [Sejnowski1987] [+]
-
Intelligence: The Eye, the Brain, and the Computer [Fischler1987] [+]
-
A theoretical framework for back-propagation [Cun1988] [+]
-
A Combined Corner and Edge Detector [Harris1988] [+]
-
Self-organisation in a perceptual network [Linsker1988] [+]
-
Radial basis functions, multi-variable functional interpolation and adaptive networks [Broomhead1988] [+]
-
Neurocomputing: foundations of research [Anderson1988] [+]
-
Backpropagation applied to handwritten zip code recognition [LeCun1989a] [+]
-
Generalization and network design strategies [LeCun1989] [+]
-
Neurocomputing [Hecht-Nielsen1989] [+]
-
Multilayer feedforward networks are universal approximators [Hornik1989] [+]
-
Connectionism: Past, present, and future [Pollack1989] [+]
-
A learning algorithm for continually running fully recurrent neural networks [Williams1989b] [+]
-
Handwritten digit recognition with a back-propagation network [LeCun1990] [+]
-
A training algorithm for optimal margin classifiers [Boser1992] [+]
-
Artificial Neural Networks: Concepts and Control Applications [Vemuri1992] [+]
-
Connectionist learning of belief networks [Neal1992] [+]
-
AI: The tumultuous history of the search for artificial intelligence [Crevier1993] [+]
-
Mining association rules between sets of items in large databases [Agrawal1993a] [+]
-
Neural networks: a comprehensive foundation [Haykin1994] [+]
-
Neuro-vision systems: A tutorial. [GuptaMadanM.1994] [+]
-
Neural Networks and Related Methods for Classification [Ripley1994a] [+]
-
Neural Network Modeling: Statistical Mechanics and Cybernetic Perspectives [Neelakanta1994] [+]
-
The "wake-sleep" algorithm for unsupervised neural networks. [Hinton1995] [+]
-
Convolutional networks for images, speech, and time series [LeCun1995] [+]
-
Principles of digital image synthesis: Vol. 1 [Glassner1995] [+]
-
An information-maximization approach to blind separation and blind deconvolution [Bell1995] [+]
-
Survey and critique of techniques for extracting rules from trained artificial neural networks [Andrews1995a] [+]
-
Mean Field Theory for Sigmoid Belief Networks [Saul1996] [+] my notes
-
On Alan Turing's anticipation of connectionism [Copeland1996] [+]
-
Pattern Recognition and Neural Networks [Ripley1996] [+]
-
Affine / photometric invariants for planar intensity patterns [Gool1996] [+]
-
Neural Networks for Pattern Recognition. [Lange1997] [+]
-
Introduction to multi-layer feed-forward neural networks [Svozil1997] [+]
-
Bain on neural networks [Wilkes1997] [+]
-
Elements of artificial neural networks [Mehrotra1997] [+]
-
Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference [Pearl1997] [+]
-
Bidirectional recurrent neural networks [Schuster1997] [+]
-
Gradient-based learning applied to document recognition [LeCun1998] [+] my notes
-
Feature detection with automatic scale selection [Lindeberg1998] [+]
-
Reinforcement Learning: An Introduction [Barto1998] [+]
-
Neural Networks: An Introductory Guide for Social Scientists [Garson1998] [+]
-
Locating facial region of a head-and-shoulders color image [Chai1998] [+]
-
Text categorisation: A survey [Aas1999] [+]
-
Alan Turing\'s forgotten ideas in Computer Science [Copeland1999] [+]
-
Face segmentation using skin-color map in videophone applications [Chai1999] [+]
-
Efficient mining of emerging patterns: Discovering trends and differences [Dong1999] [+]
-
Independent component analysis: algorithms and applications. [Hyvarinen2000a] [+]
-
Independent component analysis applied to feature extraction from colour and stereo images. [Hoyer2000] [+]
-
Emergence of phase-and shift-invariant features by decomposition of natural images into independent feature subspaces [Hyvarinen2000b] [+]
-
Principles of Neurocomputing for Science and Engineering [Ham2000] [+]
-
Principles of Neurocomputing for Science and Engineering [Ham2000a] [+]
-
A Bayesian approach to skin color classification in YCbCr color space [Chai2000] [+]
-
Fast and inexpensive color image segmentation for interactive robots [Bruce2000] [+]
-
The elements of statistical learning [Friedman2001] [+]
-
Saliency, Scale and Image Description [Kadir2001] [+]
-
Why color management? [King2002] [+]
-
Computer vision: a modern approach [Forsyth2002] [+]
-
Best Practices for Convolutional Neural Networks Applied to Visual Document Analysis [Simard2003] [+] my notes
-
Models of distributed associative memory networks in the brain ∗ [Sommer] [+]
-
Neural networks in computer intelligence [Fu2003] [+]
-
Distinctive Image Features from Scale-Invariant Keypoints [Lowe2004] [+]
-
Gaussian processes for machine learning. [Seeger2004] [+]
-
Recognizing human actions: a local SVM approach [Schuldt2004] [+]
-
Visual categorization with bags of keypoints [Csurka2004] [+]
-
Scale & affine invariant interest point detectors [Mikolajczyk2004] [+]
-
Robust wide-baseline stereo from maximally stable extremal regions [Matas2004] [+]
-
PCA-SIFT: a more distinctive representation for local image descriptors [Ke2004] [+]
-
Harnessing Nonlinearity: Predicting Chaotic Systems and Saving Energy in Wireless Communication [Jaeger2004] [+]
-
Toward automatic phenotyping of developing embryos from videos. [Ning2005] [+]
-
On contrastive divergence learning [Carreira-Perpinan2005] [+] my notes
-
Object Recognition with Features Inspired by Visual Cortex [Serre] [+]
-
Rank, trace-norm and max-norm [Srebro2005] [+]
-
Local features for object class recognition [Mikolajczyk2005] [+]
-
Learning a similarity metric discriminatively, with application to face verification [Chopra2005] [+]
-
A comparison of affine region detectors [Mikolajczyk2005a] [+]
-
A performance evaluation of local descriptors [Mikolajczyk2005b] [+]
-
A sparse texture representation using local affine regions [Lazebnik2005] [+]
-
Computers and Commerce: A Study of Technology and Management at Eckert-Mauchly Computer Company, Engineering Research Associates, and Remington Rand, 1946 -- 1957 [Norberg2005] [+]
-
Skin segmentation using color pixel classification: analysis and comparison [Phung2005] [+]
-
Histograms of oriented gradients for human detection [Dalal2005] [+]
-
A fast learning algorithm for deep belief nets [Hinton2006a] [+]
-
A fast learning algorithm for deep belief nets [Hinton2006] [+]
-
Extreme learning machine: Theory and applications [Huang2006] [+]
-
Surf: Speeded up robust features [Bay2006] [+]
-
A convolutional neural network approach for objective video quality assessment [Callet2006] [+]
-
Reducing the dimensionality of data with neural networks [Hinton2006b] [+]
-
Pattern recognition and machine learning. [Bishop2006] [+]
-
Mind as machine: A history of cognitive science [Boden2006] [+]
-
Philosophy of Psychology and Cognitive Science: A Volume of the Handbook of the Philosophy of Science Series [Gabbay2006] [+]
-
The legacy of John von Neumann [Glimm2006] [+]
-
To recognize shapes, first learn to generate images [Hinton2007] [+]
-
Robust object recognition with cortex-like mechanisms. [Serre2007] [+]
-
Scaling learning algorithms towards AI [Bengio2007] [+] my notes
-
Unsupervised Learning of Invariant Feature Hierarchies with Applications to Object Recognition [Ranzato2007] [+]
-
An empirical evaluation of deep architectures on problems with many factors of variation [Larochelle2007] [+] my notes
-
Human action recognition using a modified convolutional neural network [Kim2007] [+]
-
Local features and kernels for classification of texture and object categories: A comprehensive study [Zhang2007] [+]
-
Classifier fusion for SVM-based multimedia semantic indexing [Qu] [+]
-
The mathematical biophysics of Nicolas Rashevsky [Cull2007] [+]
-
Deep learning via semi-supervised embedding [Weston2008] [+]
-
Unsupervised Learning of Human Action Categories Using Spatial-Temporal Words [Niebles2008] [+]
-
Learning realistic human actions from movies [Laptev2008] [+]
-
Action snippets: How many frames does human action recognition require? [Schindler2008] [+]
-
Representational power of restricted boltzmann machines and deep belief networks. [LeRoux2008] [+] my notes
-
The matrix cookbook [Petersen2008] [+]
-
Speeded-up robust features (SURF) [Bay2008] [+]
-
Connectionism: A Hands-on Approach [Dawson2008] [+]
-
Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations [Lee2009] [+] my notes
-
Learning Deep Architectures for AI [Bengio2009] [+]
-
Journal of Statistical Software [Leeuw2009] [+]
-
Stacks of convolutional restricted Boltzmann machines for shift-invariant feature learning [Norouzi2009] [+] my notes
-
Actions in context [Marszalek2009] [+]
-
Unsupervised feature learning for audio classification using convolutional deep belief networks. [Lee2009a] [+]
-
What is the best multi-stage architecture for object recognition? [Jarrett2009] [+] my notes
-
Evaluation of local spatio-temporal features for action recognition [Wang2009] [+] my notes
-
Natural Image Statistics [Hyvarinen2009] [+]
-
A Novel Connectionist System for Unconstrained Handwriting Recognition [Graves2009] [+]
-
Computational Intelligence: The Legacy of Alan Turing and John von Neumann [Muhlenbein2009] [+]
-
Tiled convolutional neural networks [Ngiam2010] [+]
-
Why does unsupervised pre-training help deep learning? [Erhan2010] [+]
-
Learning Convolutional Feature Hierarchies for Visual Recognition [Kavukcuoglu2010] [+]
-
Convolutional learning of spatio-temporal features [Taylor2010] [+]
-
Convolutional Deep Belief Networks on CIFAR-10 [Krizhevsky2010] [+] my notes
-
Tiled convolutional neural networks. [Le2010] [+]
-
Computer Vision--ECCV 2010 [Daniilidis2010] [+]
-
Computer vision: algorithms and applications [Szeliski2010] [+]
-
High dynamic range imaging: acquisition, display, and image-based lighting [Reinhard2010] [+]
-
Wilcoxon-Mann-Whitney or t-test? On assumptions for hypothesis tests and multiple interpretations of decision rules [Fay2010] [+]
-
Rectified linear units improve restricted boltzmann machines [Nair2010] [+]
-
Stacked convolutional auto-encoders for hierarchical feature extraction [Masci2011] [+]
-
Building high-level features using large scale unsupervised learning [Le2011] [+]
-
Generating text with recurrent neural networks [Sutskever2011] [+]
-
Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis [Le2011b] [+] my notes
-
Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis [Le2011a] [+]
-
Adaptive deconvolutional networks for mid and high level feature learning [Zeiler2011] [+]
-
Face Recognition in Unconstrained Videos with Matched Background Similarity [Wolf2011] [+]
-
Are sparse representations really relevant for image classification? [Rigamonti2011] [+] my notes
-
Audio-based music classification with a pretrained convolutional network [Dieleman2011] [+]
-
Action recognition by dense trajectories [Wang2011] [+]
-
Structured learning and prediction in computer vision [Nowozin2011] [+]
-
Kernel Adaptive Filtering: A Comprehensive Introduction [Liu2011] [+]
-
Machine learning: a probabilistic perspective [Murphy2012] [+]
-
Learning hierarchical features for scene labeling [Farabet2013] [+]
-
ImageNet Classification with Deep Convolutional Neural Networks [Krizhevsky2012] [+] my notes
-
The Stanford / Technicolor / Fraunhofer HHI Video [Araujo] [+]
-
TRECVid 2012 Semantic Video Concept Detection by NTT-MD-DUT [Sun2012] [+]
-
Local-feature-map Integration Using Convolutional Neural Networks for Music Genre Classification [Nakashika] [+]
-
Unsupervised and Transfer Learning Challenge: a Deep Learning Approach. [Mesnil2012] [+]
-
Recognizing 50 human action categories of web videos [Reddy2012] [+] my notes
-
Gated boltzmann machine in texture modeling [Hao2012] [+]
-
Applying convolutional neural networks concepts to hybrid NN-HMM model for speech recognition [Jiang2012] [+] my notes
-
Deep Neural Networks for Acoustic Modeling in Speech Recognition [Hinton2012a] [+] my notes
-
Attribute learning for understanding unstructured social activity [Fu2012] [+]
-
AXES at TRECVid 2012: KIS, INS, and MED [Arandjelovic2012] [+]
-
Improving neural networks by preventing co-adaptation of feature detectors [Hinton2012b] [+] my notes
-
Combining gradient histograms using orientation tensors for human action recognition [Perez2012] [+]
-
Computer Vision - ECCV 2012 [Fitzgibbon2012] [+]
-
Connectionism [Garson2012] [+]
-
Alan Turing's Electronic Brain: The Struggle to Build the ACE, the World's Fastest Computer [Copeland2012] [+]
-
Differential feedback modulation of center and surround mechanisms in parvocellular cells in the visual thalamus [Jones2012] [+]
-
TRECVID 2013 - An Introduction to the Goals , Tasks , Data , Evaluation Mechanisms , and Metrics [Over2013] [+]
-
MediaMill at TRECVID 2013: Searching Concepts, Objects, Instances and Events in Video [Snoek2013] [+]
-
Semi-supervised Learning of Feature Hierarchies for Object Detection in a Video [Yang2013] [+]
-
Action and event recognition with Fisher vectors on a compact feature set [Oneata2013] [+]
-
Challenges in Representation Learning: A report on three machine learning contests [Goodfellow2013b] [+]
-
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps [Simonyan2013] [+]
-
Visualizing and Understanding Convolutional Networks [Zeiler2013] [+]
-
Quaero at TRECVid 2013 : Semantic Indexing [Safadi2013] [+]
-
Understanding Deep Architectures using a Recursive Convolutional Network [Eigen2013] [+] my notes
-
Mitosis detection in breast cancer histology images with deep neural networks [Ciresan2013] [+]
-
3D convolutional neural networks for human action recognition. [Ji2013] [+] my notes
-
Multi-digit Number Recognition from Street View Imagery using Deep Convolutional Neural Networks [Goodfellow2013a] [+]
-
Intriguing properties of neural networks [Szegedy2013] [+]
-
An Empirical Investigation of Catastrophic Forgeting in Gradient-Based Neural Networks [Goodfellow2013] [+]
-
Learned versus Hand-Designed Feature Representations for 3d Agglomeration [Bogovic2013] [+]
-
Coloring Action Recognition in Still Images [Khan2013] [+] my notes
-
Comparison of Artificial Neural Networks ; and training an Extreme Learning Machine [Topics2013] [+]
-
Do Deep Nets Really Need to be Deep? [Ba2013] [+]
-
Network In Network [min2014] [+]
-
Improving Deep Neural Networks with Probabilistic Maxout Units [Springenberg2013] [+]
-
Deep Generative Stochastic Networks Trainable by Backprop [Bengio2013] [+]
-
Maxout Networks [Goodfellow2013c] [+]
-
Discrete geometry and optimization [Bezdek2013] [+]
-
Caffe: An open source convolutional architecture for fast feature embeding. [Jia2013] [+]
-
Deep Fisher networks for large-scale image classification [Simonyan2013a] [+]
-
Human vs. Computer in Scene and Object Recognition [Borji2013] [+]
-
OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks [Sermanet2014] [+] my notes
-
Deep Learning in Neural Networks: An Overview [Schmidhuber2014] [+]
-
Feature selection and hierarchical classifier design with applications to human motion recognition [Freeman2014] [+]
-
Learning Multi-modal Latent Attributes [Fu2014] [+]
-
Large-scale Video Classification with Convolutional Neural Networks [Karpathy] [+] my notes
-
Spectral Networks and Deep Locally Connected Networks on Graphs [Bruna2014] [+]
-
On the saddle point problem for non-convex optimization [Pascanu2014] [+]
-
Learning Deep Face Representation [Fan2014] [+] my notes
-
Towards Real-Time Image Understanding with Convolutional Networks [Farabet2014] [+]
-
Return of the Devil in the Details: Delving Deep into Convolutional Nets [Chatfield2014] [+]
-
DeepFace: Closing the Gap to Human-Level Performance in Face Verification [Taigman] [+]
-
Dropout: A Simple Way to Prevent Neural Networks from Overfitting [Srivastava2014] [+]
-
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition [He2014] [+] my notes
-
Imagenet large scale visual recognition challenge [Russakovsky2014] [+] my notes
-
Deformable part models are convolutional neural networks [Girshick2014b] [+] my notes
-
Two-stream convolutional networks for action recognition in videos [Simonyan2014a] [+] my notes
-
Efficient Object Localization Using Convolutional Networks [Tompson2014] [+] my notes
-
Caffe: Convolutional architecture for fast feature embedding [Jia2014] [+] my notes
-
Rich feature hierarchies for accurate object detection and semantic segmentation [Girshick2014] [+] my notes
-
Analyzing the performance of multilayer neural networks for object recognition [Agrawal2014] [+] my notes
-
Part-based R-CNNs for fine-grained category detection [Zhang2014] [+] my notes
-
Simultaneous Detection and Segmentation [Hariharan2014] [+] my notes
-
LSDA: Large Scale Detection through Adaptation [Hoffman2014] [+] my notes
-
From Captions to Visual Concepts and Back [Fang2014] [+] my notes
-
Recurrent Models of Visual Attention [Mnih2014] [+]
-
Do Convnets Learn Correspondence? [Long2014] [+]
-
How transferable are features in deep neural networks? [Yosinski2014] [+]
-
Deep Networks with Internal Selective Attention through Feedback Connections [Stollenga2014] [+]
-
Very deep convolutional networks for large-scale image recognition [Simonyan2014] [+]
-
Going deeper with convolutions [Szegedy2014] [+]
-
Histograms of pattern sets for image classification and object recognition [Voravuthikunchai2014] [+] my notes
-
Deep Learning: Methods and Applications [Deng2014] [+]
1749
1873
1890
1909
1921
1943
1945
1947
1948
1949
1953
1954
1955
1956
1957
1958
1960
1961
1962
1965
1966
1967
1968
1969
1971
1972
1973
1974
1975
1976
1980
1981
1982
1983
1985
1986
1987
1988
1989
1990
1992
1993
1994
1995
1996
1997
1998
1999
2000
2001
2002
2003
2004
2005
2006
2007
2008
2009
2010
2011
2012
2013
2014
References [bib | html]
| [1] |
J. Bogovic, G. Huang, and V. Jain.
Learned versus Hand-Designed Feature Representations for 3d
Agglomeration.
arXiv preprint arXiv:1312.6159, pages 1-14, 2013.
[ bib |
arXiv |
http ]
Keywords: mscthesis |
| [2] |
D. Chai and K. Ngan.
Locating facial region of a head-and-shoulders color image.
pages 124-129, Apr. 1998.
[ bib |
DOI |
http ]
Keywords: Australia,Chromium,Color,Digital simulation,Face detection,Humans,Layout,Skin,Visual communication,chrominance component,data mining,face recognition,facial region location,head-and-shoulders color image,image segmentation,mscthesis,robust algorithm,simulation results,skin-color pixels,spatial distribution characteristics |
| [3] |
G. Csurka and C. Dance.
Visual categorization with bags of keypoints.
Workshop on statistical ..., 2004.
[ bib |
.pdf ]
Keywords: mscthesis |
| [4] |
P. E. King-Smith and D. Carden.
Luminance and opponent-color contributions to visual detection and
adaptation and to temporal and spatial integration.
Journal of the Optical Society of America, 66(7):709-717, July
1976.
[ bib |
DOI |
http ]
Keywords: mscthesis |
| [5] |
Q. V. Le, W. Y. Zou, S. Y. Yeung, and A. Y. Ng.
Learning hierarchical invariant spatio-temporal features for action
recognition with independent subspace analysis.
Cvpr 2011, pages 3361-3368, June 2011.
[ bib |
DOI |
http ]
Keywords: mscthesis |
| [6] |
Y. LeCun.
Une procédure d'apprentissage pour réseau a seuil
asymmetrique (a Learning Scheme for Asymmetric Threshold Networks).
In Proceedings of Cognitiva, pages 599-604, Paris, France,
1985.
[ bib |
.pdf ]
Keywords: mscthesis |
| [7] |
K. Murphy.
Machine learning: a probabilistic perspective.
2012.
[ bib |
http ]
Keywords: mscthesis |
| [8] |
K. K. Reddy and M. Shah.
Recognizing 50 human action categories of web videos.
Machine Vision and Applications, 24(5):971-981, Nov. 2012.
[ bib |
DOI |
http ]
Keywords: action recognition,fusion,mscthesis,web videos |
| [9] |
T. Serre, L. Wolf, and T. Poggio.
Object Recognition with Features Inspired by Visual Cortex.
2005 IEEE Computer Society Conference on Computer Vision and
Pattern Recognition (CVPR'05), 2:994-1000, 2005.
[ bib |
DOI |
http ]
Keywords: mscthesis |
| [10] |
K. Simonyan and A. Zisserman.
Very deep convolutional networks for large-scale image recognition.
arXiv preprint arXiv:1409.1556, Sept. 2014.
[ bib |
.pdf ]
Keywords: Computer Science - Computer Vision and Pattern Rec,mscthesis |
| [11] |
K. Aas and L. Eikvil.
Text categorisation: A survey.
Raport NR, 1999.
[ bib |
.pdf ]
Keywords: mscthesis |
| [12] |
R. Andrews, J. Diederich, and A. B. Tickle.
Survey and critique of techniques for extracting rules from trained
artificial neural networks.
Knowledge-Based Systems, 8(6):373-389, Dec. 1995.
[ bib |
DOI |
.pdf ]
Keywords: fuzzy neural networks,inferencing,knowledge insertion,mscthesis,rule extraction,rule refinement |
| [13] |
L. Ba and R. Caurana.
Do Deep Nets Really Need to be Deep?
arXiv preprint arXiv:1312.6184, pages 1-6, 2013.
[ bib |
arXiv |
http ]
Keywords: mscthesis |
| [14] |
A. Barto, R. S. Sutton, and C. W. Anderson.
Neuronlike adaptive elements that can solve difficult learning
control problems.
Systems, Man and ..., SMC-13(5):834-846, Sept. 1983.
[ bib |
DOI |
http ]
Keywords: Biological neural networks,Learning systems,Neurons,Pattern Recognition,Problem-solving,adaptive control,adaptive critic element,adaptive systems,animal learning studies,associative search element,learning control problem,movable cart,mscthesis,neural nets,neuronlike adaptive elements,supervised learning,training |
| [15] |
H. Bay, A. Ess, T. Tuytelaars, and L. V. Gool.
Speeded-up robust features (SURF).
Computer vision and image ..., 110(3):346-359, June 2008.
[ bib |
DOI |
.pdf ]
Keywords: Camera calibration,Feature description,Interest points,Local features,mscthesis,object recognition |
| [16] |
A. Bell and T. Sejnowski.
An information-maximization approach to blind separation and blind
deconvolution.
Neural computation, 7(6):1129-1159, Nov. 1995.
[ bib |
http ]
Keywords: Algorithms,Humans,Learning,Models- Statistical,Neural Networks (Computer),Neurons,Probability,Problem Solving,Speech,mscthesis |
| [17] |
Y. Bengio and Y. LeCun.
Scaling learning algorithms towards AI.
Large-Scale Kernel Machines, (1):1-41, 2007.
[ bib |
.pdf ]
Keywords: mscthesis |
| [18] |
Y. Bengio, E. Thibodeau-Laufer, G. Alain, and J. Yosinski.
Deep Generative Stochastic Networks Trainable by Backprop.
June 2013.
[ bib |
arXiv |
http ]
Keywords: mscthesis |
| [19] |
J. Bernstein.
A. I.
The New Yorker, page 50, Dec. 1981.
[ bib |
http ]
Keywords: Advanced Research Projects Agency,Andrew,Artificial Intelligence Laboratory,Berliner,Bertram,Bobrow,Chess,Computer Language,Computers,Crick,Daniel,Dartmouth Summer Research on Artificial Intelligen,Dean,Digital Equipment Corp.,Edmonds,Electronic Learning Machine,Francis,Frank,Gelernter,Gleason,Hans,Harvard University,Herbert,John,MARVIN,MINSKY,Massachusetts Institute of Technology,Mathematicians,McCarthy,Microcomputers,Papert,Perceptron,Project MAC,Raphael,Robots,Rosenblatt,Seymour,artificial intelligence,mscthesis |
| [20] |
A. Borji and L. Itti.
Human vs. Computer in Scene and Object Recognition.
pages 113-120, 2013.
[ bib |
.pdf ]
Keywords: mscthesis |
| [21] |
M. Brown and D. Lowe.
Unsupervised 3D object recognition and reconstruction in unordered
datasets.
3-D Digital Imaging and Modeling, 2005. ..., pages 56-63,
June 2005.
[ bib |
DOI |
http ]
Keywords: Computer Graphics,Computer science,Computer vision,Image databases,Image recognition,Layout,RANSAC algorithm,Sparse matrices,automatic recognition,camera matrix,cameras,feature extraction,image matching,image motion analysis,image reconstruction,invariant local features,object motion,object recognition,object reconstruction,sparse bundle adjustment algorithm,unordered datasets,unsupervised 3D object recognition,visual databases |
| [22] |
S. Chopra, R. Hadsell, and Y. LeCun.
Learning a similarity metric discriminatively, with application to
face verification.
...Vision and Pattern Recognition ..., 1:539-546 vol.
1, June 2005.
[ bib |
DOI |
http ]
Keywords: Artificial neural networks,Character generation,Drives,Glass,L1 norm,Robustness,Spatial databases,Support vector machine classification,System testing,discriminative loss function,face recognition,face verification,geometric distortion,learning (artificial intelligence),mscthesis,semantic distance approximation,similarity metric learning,support vector machines |
| [23] |
P. Cull.
The mathematical biophysics of Nicolas Rashevsky.
Biosystems, 88(3):178-184, Apr. 2007.
[ bib |
DOI |
.pdf ]
Keywords: History,Mathematical biology,Mathematical biophysics,Rashevsky,Relational biology,mscthesis,neural nets |
| [24] |
K. Daniilidis, P. Maragos, and N. Paragios.
Computer Vision-ECCV 2010.
2010.
[ bib |
.pdf ]
Keywords: mscthesis |
| [25] |
M. R. W. Dawson.
Connectionism: A Hands-on Approach.
John Wiley & Sons, Apr. 2008.
[ bib |
http ]
Keywords: Psychology / Cognitive Psychology,Psychology / Cognitive Psychology & Cognition,Psychology / General,mscthesis |
| [26] |
C. Farabet, C. Couprie, L. Najman, and Y. LeCun.
Learning hierarchical features for scene labeling.
8:1915-1929, 2012.
[ bib |
.pdf ]
Keywords: CNN,mscthesis |
| [27] |
C. Farabet.
Towards Real-Time Image Understanding with Convolutional
Networks.
PhD thesis, Université Paris-Est, 2014.
[ bib |
.pdf ]
Keywords: CNN,mscthesis |
| [28] |
M. Fay and M. Proschan.
Wilcoxon-Mann-Whitney or t-test? On assumptions for hypothesis tests
and multiple interpretations of decision rules.
Statistics surveys, 4:1-39, 2010.
[ bib |
DOI |
.pdf ]
Keywords: mscthesis |
| [29] |
R. Girshick, J. Donahue, T. Darrell, and J. Malik.
Rich feature hierarchies for accurate object detection and semantic
segmentation.
IEEE Conference on Computer Vision and Pattern Recognition
(CVPR), Nov. 2014.
[ bib |
.pdf ]
Keywords: Computer Science - Computer Vision and Pattern Rec,mscthesis |
| [30] |
R. Girshick, F. Iandola, T. Darrell, and J. Malik.
Deformable part models are convolutional neural networks.
arXiv preprint arXiv:1409.5403, Sept. 2014.
[ bib |
.pdf ]
Keywords: Computer Science - Computer Vision and Pattern Rec,mscthesis |
| [31] |
A. Graves, M. Liwicki, S. Fernandez, R. Bertolami, H. Bunke, and
J. Schmidhuber.
A Novel Connectionist System for Unconstrained Handwriting
Recognition.
IEEE Transactions on Pattern Analysis and Machine Intelligence,
31(5):855-868, May 2009.
[ bib |
DOI |
http ]
Keywords: Algorithms,Automatic Data Processing,Connectionist temporal classification,Handwriting,Image Enhancement,Image Interpretation- Computer-Assisted,Information Storage and Retrieval,Long Short-Term Memory,Models- Statistical,Offline handwriting recognition,Online handwriting recognition,Pattern Recognition- Automated,Reading,Recurrent neural networks,Reproducibility of Results,Sensitivity and Specificity,Subtraction Technique,Unconstrained handwriting recognition,bidirectional long short-term memory,connectionist system,handwriting recognition,handwritten character recognition,hidden Markov model.,hidden Markov models,image segmentation,language modeling,mscthesis,offline handwriting,online handwriting,overlapping character segmentation,recurrent neural nets,recurrent neural network,unconstrained handwriting databases,unconstrained handwriting text recognition |
| [32] |
G. Hinton, S. Osindero, and Y. Teh.
A fast learning algorithm for deep belief nets.
Neural computation, 2006.
[ bib |
.pdf ]
Keywords: mscthesis |
| [33] |
G. Hinton and R. Salakhutdinov.
Reducing the dimensionality of data with neural networks.
Science, 313(July):504-507, 2006.
[ bib |
.pdf ]
Keywords: mscthesis |
| [34] |
Y. Jia.
Caffe: An open source convolutional architecture for fast feature
embeding., 2013.
[ bib |
http ]
Keywords: mscthesis |
| [35] |
F. Khan and R. Anwer.
Coloring Action Recognition in Still Images.
International journal of ..., pages 1-18, 2013.
[ bib |
http ]
Keywords: color features,image representation,mscthesis |
| [36] |
T. Kohonen.
Correlation matrix memories.
Computers, IEEE Transactions on, 21(4):353-359, Apr. 1972.
[ bib |
DOI |
http ]
Keywords: Associative memory,Pattern Recognition,associative net,associative recall,correlation matrix memory,mscthesis,nonholographic associative memory |
| [37] |
N. Lange, C. M. Bishop, and B. D. Ripley.
Neural Networks for Pattern Recognition.
Journal of the American Statistical Association, 92(440):1642,
Dec. 1997.
[ bib |
DOI |
http ]
Keywords: mscthesis |
| [38] |
Y. LeCun and Y. Bengio.
Convolutional networks for images, speech, and time series.
...handbook of brain theory and neural networks, pages
1-14, 1995.
[ bib |
.pdf ]
Keywords: CNN,mscthesis |
| [39] |
Y. LeCun, B. Boser, J. Denker, D. Henderson, R. Howard, W. Hubbard, and
L. Jackel.
Handwritten digit recognition with a back-propagation network.
Advances in neural ..., pages 396-404, 1990.
[ bib |
http ]
Keywords: mscthesis |
| [40] |
J. Leeuw.
Journal of Statistical Software.
Wiley Interdisciplinary Reviews: Computational, 15(9), 2009.
[ bib |
http ]
Keywords: mscthesis,r,support vector machines |
| [41] |
R. Linsker.
Self-organisation in a perceptual network.
Computer, 21(3):105-117, Mar. 1988.
[ bib |
DOI |
http ]
Keywords: mscthesis |
| [42] |
W. McCulloch and W. Pitts.
A logical calculus of the ideas immanent in nervous activity.
The bulletin of mathematical biophysics, 5(4):115-133, Dec.
1943.
[ bib |
DOI |
http ]
Keywords: Mathematical Biology in General,mscthesis |
| [43] | N. Nachar. The Mann-Whitney U: a test for assessing whether two independent samples come from the same distribution. Tutorials in Quantitative Methods for Psychology, 4(1):13-20, 2008. [ bib | .pdf ] |
| [44] |
T. Nakashika, C. Garcia, T. Takiguchi, and I. D. Lyon.
Local-feature-map Integration Using Convolutional Neural Networks
for Music Genre Classification.
INTERSPEECH, pages 1-4, 2012.
[ bib ]
Keywords: mscthesis |
| [45] |
J. Neumann and A. Burks.
Theory of self-reproducing automata.
1966.
[ bib |
http ]
Keywords: mscthesis |
| [46] |
R. Pascanu and Y. Dauphin.
On the saddle point problem for non-convex optimization.
arXiv preprint arXiv: ..., pages 1-11, 2014.
[ bib |
arXiv |
http ]
Keywords: mscthesis |
| [47] |
M. Ranzato, F. J. Huang, Y.-L. Boureau, and Y. LeCun.
Unsupervised Learning of Invariant Feature Hierarchies with
Applications to Object Recognition.
2007 IEEE Conference on Computer Vision and Pattern
Recognition, pages 1-8, June 2007.
[ bib |
DOI |
http ]
Keywords: mscthesis |
| [48] |
B. D. Ripley.
Pattern Recognition and Neural Networks.
Cambridge University Press, 1996.
[ bib |
http ]
Keywords: Mathematics / Probability & Statistics / General,mscthesis |
| [49] |
F. Rosenblatt.
The Perceptron, a Perceiving and Recognizing Automaton.
Technical report, Cornell Aeronautical Laboratory, Buffalo, NY, 1957.
[ bib ]
Keywords: mscthesis |
| [50] |
O. Russakovsky, J. Deng, and H. Su.
Imagenet large scale visual recognition challenge.
arXiv preprint arXiv: ..., Sept. 2014.
[ bib |
.pdf ]
Keywords: Computer Science - Computer Vision and Pattern Rec,I.4.8,I.5.2,mscthesis |
| [51] |
J. Schmidhuber.
Deep Learning in Neural Networks: An Overview.
Manno-Lugano, 2014.
[ bib |
arXiv |
http ]
Keywords: mscthesis |
| [52] |
T. Sejnowski and C. Rosenberg.
Parallel networks that learn to pronounce English text.
Complex systems, 1:145-168, 1987.
[ bib |
.pdf ]
Keywords: mscthesis |
| [53] |
T. Serre, L. Wolf, S. Bileschi, M. Riesenhuber, and T. Poggio.
Robust object recognition with cortex-like mechanisms.
IEEE transactions on pattern analysis and machine intelligence,
29(3):411-26, Mar. 2007.
[ bib |
DOI |
http ]
Keywords: Algorithms,Artificial Intelligence,Biomimetics,Biomimetics: methods,Computer Simulation,Humans,Image Enhancement,Image Enhancement: methods,Image Interpretation, Computer-Assisted,Image Interpretation, Computer-Assisted: methods,Models, Biological,Pattern Recognition, Automated,Pattern Recognition, Automated: methods,Pattern Recognition, Visual,Pattern Recognition, Visual: physiology,Reproducibility of Results,Sensitivity and Specificity,Visual Cortex,Visual Cortex: physiology,mscthesis,visual cortex |
| [54] |
K. Simonyan, A. Vedaldi, and A. Zisserman.
Deep Inside Convolutional Networks: Visualising Image Classification
Models and Saliency Maps.
arXiv preprint arXiv:1312.6034, pages 1-8, 2013.
[ bib |
arXiv |
http ]
Keywords: CNN,mscthesis |
| [55] |
N. Srebro and A. Shraibman.
Rank, trace-norm and max-norm.
Learning Theory, pages 545-560, 2005.
[ bib |
http ]
Keywords: mscthesis |
| [56] |
M. F. Stollenga, J. Masci, F. Gomez, and J. Schmidhuber.
Deep Networks with Internal Selective Attention through Feedback
Connections.
pages 3545-3553. Curran Associates, Inc., 2014.
[ bib |
http ]
Keywords: mscthesis |
| [57] |
Y. Sun, K. Sudo, Y. Taniguchi, and H. Li.
TRECVid 2012 Semantic Video Concept Detection by NTT-MD-DUT.
Proc. TRECVID 2012 ..., 2012.
[ bib |
.pdf ]
Keywords: 2012 video,concept detection system first,developed at the ntt,haojie li,in this paper,lei yi,mscthesis,we describe the trecvid,yue guan |
| [58] |
I. Sutskever, J. Martens, and G. Hinton.
Generating text with recurrent neural networks.
Proceedings of the ..., 2011.
[ bib |
.pdf ]
Keywords: mscthesis |
| [59] |
R. S. Sutton and A. G. Barto.
Reinforcement Learning: An Introduction.
MIT Press, 1998.
[ bib |
http ]
Keywords: Computers / Intelligence (AI) & Semantics,mscthesis |
| [60] |
W. K. Taylor.
Electrical simulation of some nervous system functional activities.
Information theory 3, pages 314-328, 1956.
[ bib ]
Keywords: mscthesis |
| [61] |
H. Wang, A. Klaser, C. Schmid, and C.-L. Liu.
Action recognition by dense trajectories.
...and Pattern Recognition ( ..., 2011.
[ bib |
http ]
Keywords: mscthesis |
| [62] |
N. Wiener.
Cybernetics or Control and Communication in the Animal and the
Machine.
The Massachusetts Institute of Technology, 1948.
[ bib |
http ]
Keywords: mscthesis |
| [63] |
D. J. Willshaw, O. P. Buneman, and H. C. Longuet-Higgins.
Non-Holographic Associative Memory.
Nature, 222(5197):960-962, June 1969.
[ bib |
DOI |
.pdf ]
Keywords: mscthesis |
| [64] |
Y. Yang, G. Shu, and M. Shah.
Semi-supervised Learning of Feature Hierarchies for Object Detection
in a Video.
2013 IEEE Conference on Computer Vision and Pattern
Recognition, pages 1650-1657, June 2013.
[ bib |
DOI |
.pdf ]
Keywords: mscthesis,trecvid |
| [65] |
M. Fisher, D. Ritchie, M. Savva, T. Funkhouser, and P. Hanrahan.
Example-based Synthesis of 3D Object Arrangements.
ACM Trans. Graph., 31(6):135:1-135:11, Nov. 2012.
[ bib |
DOI |
http ]
Keywords: 3D scenes,automatic layout,data-driven methods,probabilistic modeling,procedural modeling |
| [66] |
E. Kalogerakis, S. Chaudhuri, D. Koller, and V. Koltun.
A Probabilistic Model for Component-based Shape Synthesis.
ACM Trans. Graph., 31(4):55:1-55:11, July 2012.
[ bib |
DOI |
http ]
Keywords: data-driven 3D modeling,machine learning,probabilistic graphical models,shape structure,shape synthesis |
| [67] |
A. Bain.
Mind and body. The theories of their relation.
New York : D. Appleton and company, 1873.
[ bib |
http ]
Keywords: Psychophysiology,mscthesis |
| [68] |
M. Boden.
Mind as machine: A history of cognitive science, volume 1.
2006.
[ bib |
http ]
Keywords: mscthesis |
| [69] |
B. J. Copeland and D. Proudfoot.
Alan Turing's forgotten ideas in Computer Science.
Scientific American, pages 99-103, 1999.
[ bib |
http ]
Keywords: mscthesis |
| [70] |
S. Dieleman, P. Brakel, and B. Schrauwen.
Audio-based music classification with a pretrained convolutional
network.
...International Society for Music ...,
(Ismir):669-674, 2011.
[ bib |
http ]
Keywords: CNN,mscthesis |
| [71] |
H. Fan, Z. Cao, Y. Jiang, Q. Yin, C. Doudou, and C. Doudou.
Learning Deep Face Representation.
arXiv preprint arXiv:1403.2802, pages 1-10, 2014.
[ bib |
arXiv |
.pdf ]
Keywords: mscthesis |
| [72] |
L. Fu.
Neural networks in computer intelligence.
page 484, Apr. 2003.
[ bib |
http ]
Keywords: mscthesis |
| [73] |
Y. Fu, T. M. Hospedales, T. Xiang, and S. Gong.
Learning Multi-modal Latent Attributes.
IEEE transactions on pattern analysis and machine intelligence,
36(2):303-16, Feb. 2014.
[ bib |
DOI |
http ]
Keywords: mscthesis |
| [74] |
G. D. Garson.
Neural Networks: An Introductory Guide for Social Scientists.
SAGE, Sept. 1998.
[ bib |
http ]
Keywords: Reference / Research,Social Science / Research,mscthesis |
| [75] |
I. Goodfellow, D. Erhan, P. Carrier, A. Courville, M. Mirza, B. Hamner,
W. Cukierski, Y. Tang, D. Thaler, D.-H. Lee, Y. Zhou, C. Ramaiah, F. Feng,
R. Li, X. Wang, D. Athanasakis, J. Shawe-Taylor, M. Milakov, J. Park,
R. Ionescu, M. Popescu, C. Grozea, J. Bergstra, J. Xie, L. Romaszko, B. Xu,
Z. Chuang, and Y. Bengio.
Challenges in Representation Learning: A report on three machine
learning contests.
Neural Information ..., pages 1-8, 2013.
[ bib |
arXiv |
http ]
Keywords: competition,dataset,mscthesis,representation learning |
| [76] |
L. V. Gool, T. Moons, and D. Ungureanu.
Affine / photometric invariants for planar intensity patterns.
Lecture Notes in Computer Science, pages 642-651. Springer Berlin
Heidelberg, Jan. 1996.
[ bib |
.pdf ]
Keywords: Artificial Intelligence (incl. Robotics),Computer Graphics,Control Engineering,Image Processing and Computer Vision,Pattern Recognition,mscthesis |
| [77] |
K. Hornik, M. Stinchcombe, and H. White.
Multilayer feedforward networks are universal approximators.
Neural networks, 2(5):359-366, 1989.
[ bib |
DOI |
http ]
Keywords: Back-propagation networks,Feedforward networks,Mapping networks,Network representation capability,Sigma-Pi networks,Squashing functions,Stone-Weierstrass Theorem,Universal approximation,mscthesis |
| [78] |
H. Jaeger and H. Haas.
Harnessing Nonlinearity: Predicting Chaotic Systems and Saving
Energy in Wireless Communication.
Science, 304(5667):78-80, Apr. 2004.
[ bib |
DOI |
http ]
Keywords: mscthesis |
| [79] |
Y. Jia, E. Shelhamer, and J. Donahue.
Caffe: Convolutional architecture for fast feature embedding.
Proceedings of the ..., June 2014.
[ bib |
http ]
Keywords: Computer Science - Computer Vision and Pattern Rec,Computer Science - Learning,Computer Science - Neural and Evolutionary Computi,mscthesis |
| [80] |
H. Kim, J. Lee, and H. Yang.
Human action recognition using a modified convolutional neural
network.
Advances in Neural Networks-ISNN 2007, pages 715-723, Jan.
2007.
[ bib |
.pdf ]
Keywords: Algorithm Analysis and Problem Complexity,Artificial Intelligence (incl. Robotics),Computation by Abstract Devices,Computer Communication Networks,Discrete Mathematics in Computer Science,Pattern Recognition,mscthesis |
| [81] |
I. Laptev and M. Marszalek.
Learning realistic human actions from movies.
Computer Vision and ..., 2008.
[ bib |
http ]
Keywords: mscthesis |
| [82] |
H. Larochelle, D. Erhan, A. Courville, J. Bergstra, and Y. Bengio.
An empirical evaluation of deep architectures on problems with many
factors of variation.
Proceedings of the 24th ..., (2006):8, 2007.
[ bib |
http ]
Keywords: mscthesis |
| [83] |
Q. Le, J. Ngiam, Z. Chen, D. hao Chia, and P. Koh.
Tiled convolutional neural networks.
NIPS, pages 1-9, 2010.
[ bib |
.pdf ]
Keywords: mscthesis |
| [84] |
M. Lin, Q. Chen, and S. Yan.
Network In Network.
page 10, Dec. 2013.
[ bib |
arXiv |
http ]
Keywords: mscthesis |
| [85] |
J. Matas, O. Chum, M. Urban, and T. Pajdla.
Robust wide-baseline stereo from maximally stable extremal regions.
Image and Vision Computing, 22(10):761-767, Sept. 2004.
[ bib |
DOI |
.pdf ]
Keywords: Distinguished regions,MSER,Maximally stable extremal regions,Robust metric,Wide-baseline stereo,mscthesis |
| [86] |
N. Metropolis, A. W. Rosenbluth, M. N. Rosenbluth, A. H. Teller, and E. Teller.
Equation of State Calculations by Fast Computing Machines.
The Journal of Chemical Physics, 21(6):1087-1092, June 1953.
[ bib |
DOI |
http ]
Keywords: Atomic and molecular interactions,Equations of state,Monte Carlo methods,mscthesis |
| [87] |
J. von Neumann.
First Draft of a Report on the EDVAC.
Technical Report 1, 1945.
[ bib |
.pdf ]
Keywords: mscthesis |
| [88] |
A. Novikoff.
On convergence proofs on perceptrons.
Proceedings of the Symposium on the Mathematical Theory of
Automata, New York, XII:615-622, 1962.
[ bib ]
Keywords: mscthesis |
| [89] |
B. D. Ripley.
Neural Networks and Related Methods for Classification.
Journal of the Royal Statistical Society. Series B
(Methodological), 56(3):409-456, Jan. 1994.
[ bib |
http ]
Keywords: mscthesis |
| [90] |
R. Szeliski.
Computer vision: algorithms and applications.
2010.
[ bib |
http ]
Keywords: Computer Vision - Algorithms and Applications,Image Processing and Computer Vision,mscthesis |
| [91] |
J. Tompson, R. Goroshin, and A. Jain.
Efficient Object Localization Using Convolutional Networks.
arXiv preprint arXiv: ..., Nov. 2014.
[ bib |
.pdf ]
Keywords: Computer Science - Computer Vision and Pattern Rec,mscthesis |
| [92] |
A. Topics and I. N. Computational.
Comparison of Artificial Neural Networks ; and training an Extreme
Learning Machine.
(April):1-3, 2013.
[ bib ]
Keywords: artificial neural network,extreme learning machine,mscthesis |
| [93] |
A. M. Uttley.
Conditional probability machines and conditional reflexes.
Automata studies, pages 253-276, 1956.
[ bib ]
Keywords: mscthesis |
| [94] |
A. L. Wilkes and N. J. Wade.
Bain on neural networks.
Brain and Cognition, 33(3):295-305, Apr. 1997.
[ bib |
DOI |
http ]
Keywords: Brain,History- 19th Century,History- 20th Century,Humans,Memory,Models- Neurological,Nerve Net,Neuropsychology,mscthesis |
| [95] | V. Mansinghka, T. D. Kulkarni, Y. N. Perov, and J. Tenenbaum. Approximate Bayesian Image Interpretation using Generative Probabilistic Graphics Programs. pages 1520-1528. Curran Associates, Inc., 2013. [ bib | .pdf ] |
| [96] |
S. Amari.
A Theory of Adaptive Pattern Classifiers.
IEEE Transactions on Electronic Computers, EC-16(3):299-307,
June 1967.
[ bib |
DOI |
http ]
Keywords: Accuracy of learning,Computer errors,Convergence,Logic,Piecewise linear techniques,Probability distribution,Vectors,adaptive pattern classifier,adaptive systems,convergence of learning,learning under nonseparable pattern distribution,linear decision function,mscthesis,piecewise-linear decision function,rapidity of learning |
| [97] |
J. A. Anderson and E. Rosenfeld.
Neurocomputing: foundations of research.
MIT Press, Cambridge, MA, USA, 1988.
[ bib |
http ]
Keywords: mscthesis |
| [98] |
R. Arandjelovic, A. Zisserman, and B. Fernando.
AXES at TRECVid 2012: KIS, INS, and MED.
2012.
[ bib |
.pdf ]
Keywords: mscthesis |
| [99] |
A. F. D. Araujo, F. Silveira, H. Lakshman, J. Zepeda, A. Sheth, and B. Girod.
The Stanford / Technicolor / Fraunhofer HHI Video.
2012.
[ bib ]
Keywords: bovw,centrist,dense ex-,for each run,harlap keypoint detector,l a stanford1 1,mscthesis,oppsift,residual,sift,spm,traction,trecvid |
| [100] |
C. M. Bishop.
Pattern recognition and machine learning., volume 1.
New York: springer, 2006., 2006.
[ bib ]
Keywords: mscthesis |
| [101] |
D. Chai and A. Bouzerdoum.
A Bayesian approach to skin color classification in YCbCr color
space.
volume 2, pages 421-424 vol.2, 2000.
[ bib |
DOI |
http ]
Keywords: Australia,Bayes decision rule,Bayes methods,Bayesian approach,Bayesian methods,Chromium,Costs,Mathematics,Pixel,Skin,Statistics,TV,YCbCr color space,color statistics,image classification,image colour analysis,minimum cost,mscthesis,nonskin color,pixels classification,skin color classification |
| [102] |
K. Chatfield and K. Simonyan.
Return of the Devil in the Details: Delving Deep into Convolutional
Nets.
arXiv preprint arXiv: ..., pages 1-11, 2014.
[ bib |
arXiv |
http ]
Keywords: mscthesis |
| [103] |
D. Crevier.
AI: The tumultuous history of the search for artificial
intelligence.
1993.
[ bib |
http ]
Keywords: mscthesis |
| [104] |
L. Deng and D. Yu.
Deep Learning: Methods and Applications.
2014.
[ bib |
.pdf ]
Keywords: mscthesis |
| [105] |
F. M. Ham and I. Kostanic.
Principles of Neurocomputing for Science and Engineering.
McGraw-Hill Higher Education, 1st edition, 2000.
[ bib ]
Keywords: mscthesis |
| [106] |
J. Hoffman, S. Guadarrama, and E. Tzeng.
LSDA: Large Scale Detection through Adaptation.
Advances in Neural ..., July 2014.
[ bib |
http ]
Keywords: Computer Science - Computer Vision and Pattern Rec,mscthesis |
| [107] |
Howard C. Warren.
A history of the association psychology.
page 355, 1921.
[ bib |
http ]
Keywords: mscthesis |
| [108] |
a. Hyvärinen and E. Oja.
Independent component analysis: algorithms and applications.
Neural networks : the official journal of the International
Neural Network Society, 13(4-5):411-30, 2000.
[ bib |
http ]
Keywords: Algorithms,Artifacts,Brain,Brain: physiology,Humans,Magnetoencephalography,Neural Networks (Computer),Normal Distribution,mscthesis |
| [109] |
T. Kadir and M. Brady.
Saliency, Scale and Image Description.
International Journal of Computer Vision, 45(2):83-105, Nov.
2001.
[ bib |
DOI |
.pdf ]
Keywords: Artificial Intelligence (incl. Robotics),Automation and Robotics,Computer Imaging- Graphics and Computer Vision,Entropy,Image Processing,feature extraction,image content descriptors,image database,mscthesis,salient features,scale selection,scale-space,visual saliency |
| [110] |
S. Lazebnik, C. Schmid, and J. Ponce.
A sparse texture representation using local affine regions.
IEEE Transactions on Pattern Analysis and Machine Intelligence,
27(8):1265-1278, Aug. 2005.
[ bib |
DOI |
http ]
Keywords: Algorithms,Brodatz database,Cluster Analysis,Computer Graphics,Computer vision,Detectors,Image Enhancement,Image Interpretation- Computer-Assisted,Image analysis,Image databases,Image recognition,Image texture analysis,Index Terms- Image processing and computer vision,Information Storage and Retrieval,Information retrieval,Laplacian regions,Numerical Analysis- Computer-Assisted,Pattern Recognition- Automated,Shape,Spatial databases,Surface texture,affine-invariant fashion,artificial intelligence,distinctive appearance pattern,elliptic shape,elliptical shape,feature extraction,feature measurement,image representation,image texture,local affine regions,mscthesis,pattern recognition.,shape normalization,sparse set,sparse texture representation,texture,texture element,texture recognition,visual databases |
| [111] |
N. Le Roux and Y. Bengio.
Representational power of restricted boltzmann machines and deep
belief networks.
Neural computation, 20(6):1631-49, June 2008.
[ bib |
DOI |
http ]
Keywords: Algorithms,Animals,Computer Simulation,Computer-Assisted,Humans,Learning,Learning: physiology,Models,Neural Networks (Computer),Signal Processing,Statistical,mscthesis |
| [112] |
Y. LeCun and L. Bottou.
Gradient-based learning applied to document recognition.
Proceedings of the ..., 1998.
[ bib |
.pdf ]
Keywords: CNN,mscthesis |
| [113] |
Y. LeCun.
Learning Process in an Asymmetric Threshold Network.
NATO ASI Series, pages 233-240. Springer Berlin Heidelberg, Jan.
1986.
[ bib |
http ]
Keywords: Artificial Intelligence (incl. Robotics),Computer Appl. in Life Sciences,Health Informatics,mscthesis |
| [114] |
G. Mesnil, Y. Dauphin, X. Glorot, S. Rifai, Y. Bengio, I. Goodfellow,
E. Lavoie, X. Muller, G. Desjardins, D. Warde-Farley, P. Vincent,
A. Courville, and J. Bergstra.
Unsupervised and Transfer Learning Challenge: a Deep Learning
Approach.
...of Machine Learning ..., 7:1-15, 2012.
[ bib |
http ]
Keywords: Auto-Encoders,Deep Learning,Denoising Auto-Encoders.,Neural Networks,Restricted Boltzmann Machines,Transfer Learning,Unsupervised Learning,mscthesis |
| [115] |
H. Mühlenbein.
Computational Intelligence: The Legacy of Alan Turing and John von
Neumann.
Computational Intelligence, pages 23-43, 2009.
[ bib |
http ]
Keywords: mscthesis |
| [116] |
R. M. Neal.
Connectionist learning of belief networks.
Artificial Intelligence, 56(1):71-113, July 1992.
[ bib |
DOI |
http ]
Keywords: mscthesis |
| [117] |
P. Over, G. Awad, J. Fiscus, and G. Sanders.
TRECVID 2013 - An Introduction to the Goals , Tasks , Data ,
Evaluation Mechanisms , and Metrics.
2013.
[ bib ]
Keywords: mscthesis,trecvid |
| [118] |
F. Rosenblatt.
The perceptron: a probabilistic model for information storage and
organization in the brain.
Psychological review, 65(6):386-408, 1958.
[ bib |
DOI |
http ]
Keywords: *Brain,*Cognition,*Memory,Nervous System,mscthesis |
| [119] |
L. Uhr.
Highly parallel, hierarchical, recognition cone perceptual
structures.
Parallel computer vision, 1987.
[ bib |
http ]
Keywords: mscthesis |
| [120] |
V. Vapnik and A. Chervonenkis.
On the uniform convergence of relative frequencies of events to
their probabilities.
Theory of Probability & Its Applications, 16(2):264-280, Jan.
1971.
[ bib |
DOI |
http ]
Keywords: mscthesis |
| [121] |
P. Werbos.
Beyond regression: new tools for prediction and analysis in the
behavioral sciences.
1974.
[ bib ]
Keywords: mscthesis |
| [122] |
J. Weston, F. Ratle, and R. Collobert.
Deep learning via semi-supervised embedding.
Proceedings of the 25th international conference on Machine
learning - ICML '08, pages 1168-1175, 2008.
[ bib |
DOI |
.pdf ]
Keywords: mscthesis,trecvid |
| [123] |
L. Wolf, T. Hassner, and I. Maoz.
Face Recognition in Unconstrained Videos with Matched Background
Similarity.
Cvpr 2011, pages 529-534, June 2011.
[ bib |
DOI |
http ]
Keywords: mscthesis |
| [124] |
A. Krizhevsky, I. Sutskever, and G. Hinton.
ImageNet Classification with Deep Convolutional Neural Networks.
NIPS, pages 1-9, 2012.
[ bib |
.pdf ]
Keywords: imagenet,mscthesis |
| [125] |
J. Bruna, A. Szlam, W. Zaremba, and Y. LeCun.
Spectral Networks and Deep Locally Connected Networks on Graphs.
pages 1-14, 2014.
[ bib |
arXiv ]
Keywords: mscthesis |
| [126] |
D. Forsyth and J. Ponce.
Computer vision: a modern approach.
2002.
[ bib |
http ]
Keywords: mscthesis |
| [127] |
J. Friedman, T. Hastie, and R. Tibshirani.
The elements of statistical learning.
2001.
[ bib |
.pdf ]
Keywords: mscthesis |
| [128] |
I. Goodfellow, M. Mirza, X. Da, A. Courville, and Y. Bengio.
An Empirical Investigation of Catastrophic Forgeting in
Gradient-Based Neural Networks.
arXiv preprint arXiv: ..., 2013.
[ bib |
arXiv |
http ]
Keywords: mscthesis |
| [129] |
B. Hariharan, P. Arbeláez, R. Girshick, and J. Malik.
Simultaneous Detection and Segmentation.
Lecture Notes in Computer Science, pages 297-312. Springer
International Publishing, Jan. 2014.
[ bib |
.pdf ]
Keywords: Artificial Intelligence (incl. Robotics),Computer Graphics,Image Processing and Computer Vision,Pattern Recognition,convolutional networks,detection,mscthesis,segmentation |
| [130] |
G. Hinton.
To recognize shapes, first learn to generate images.
Progress in brain research, 2007.
[ bib |
http ]
Keywords: mscthesis |
| [131] |
Q. Le, M. Ranzato, R. Monga, and M. Devin.
Building high-level features using large scale unsupervised
learning.
arXiv preprint arXiv: ..., 2011.
[ bib |
arXiv |
.pdf ]
Keywords: CNN,mscthesis |
| [132] |
D. Lowe.
Object recognition from local scale-invariant features.
volume 2, pages 1150-1157 vol.2, 1999.
[ bib |
DOI |
http ]
Keywords: 3D projection,Computer science,Electrical capacitance tomography,Filters,Image recognition,Layout,Lighting,Neurons,Programmable logic arrays,Reactive power,blurred image gradients,candidate object matches,cluttered partially occluded images,computation time,computational geometry,feature extraction,image matching,inferior temporal cortex,least squares approximations,local geometric deformations,local image features,local scale-invariant features,low residual least squares solution,multiple orientation planes,nearest neighbor indexing method,object recognition,primate vision,robust object recognition,staged filtering approach,unknown model parameters |
| [133] |
H. Mann and D. Whitney.
On a test of whether one of two random variables is stochastically
larger than the other.
The annals of mathematical statistics, 18(1):50-60, Mar. 1947.
[ bib |
DOI |
http ]
Keywords: mscthesis |
| [134] |
K. Mikolajczyk, B. Leibe, and B. Schiele.
Local features for object class recognition.
Computer Vision, 2005. ..., 2:1792-1799 Vol. 2, Oct. 2005.
[ bib |
DOI |
http ]
Keywords: Art,Computer vision,Detectors,Entropy,Hessian-Laplace regions,Image recognition,Interactive systems,Object detection,Photometry,SIFT descriptors,Testing,categorization problems,feature extraction,hierarchical agglomerative clustering,mscthesis,object class recognition,object recognition,pattern classification,pattern clustering,pedestrian detection,salient regions,scale invariant region detectors |
| [135] |
N. J. Nilsson.
Learning machines: foundations of trainable pattern-classifying
systems.
McGraw-Hill, 1965.
[ bib |
http ]
Keywords: Computers / Intelligence (AI) & Semantics,mscthesis |
| [136] |
P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y. LeCun.
OverFeat: Integrated Recognition, Localization and Detection using
Convolutional Networks.
arXiv preprint arXiv: ..., pages 1-16, 2014.
[ bib |
arXiv |
.pdf ]
Keywords: CNN,mscthesis |
| [137] |
C. E. Shannon and J. McCarthy.
Automata Studies: Annals of Mathematics Studies. Number 34.
Princeton University Press, 1972.
[ bib |
http ]
Keywords: Technology & Engineering / Electrical,mscthesis |
| [138] |
P. Simard, D. Steinkraus, and J. Platt.
Best Practices for Convolutional Neural Networks Applied to Visual
Document Analysis.
ICDAR, 2003.
[ bib |
.pdf ]
Keywords: CNN,mscthesis |
| [139] |
D. H. Ackley, G. E. Hinton, and T. J. Sejnowski.
A Learning Algorithm for Boltzmann Machines*.
Cognitive Science, 9(1):147-169, Jan. 1985.
[ bib |
DOI |
http ]
Keywords: mscthesis |
| [140] |
R. Agrawal, T. Imielinski, and A. Swami.
Mining association rules between sets of items in large databases.
ACM SIGMOD Record, pages 207-216, 1993.
[ bib |
DOI |
http ]
Keywords: mscthesis |
| [141] |
H. Bay, T. Tuytelaars, and L. V. Gool.
Surf: Speeded up robust features.
Computer Vision-ECCV 2006, 2006.
[ bib |
http ]
Keywords: mscthesis |
| [142] |
D. Eigen, J. Rolfe, R. Fergus, and Y. LeCun.
Understanding Deep Architectures using a Recursive Convolutional
Network.
arXiv preprint arXiv:1312.1847, pages 1-9, 2013.
[ bib |
arXiv |
.pdf ]
Keywords: CNN,mscthesis |
| [143] |
H. Fang, S. Gupta, and F. Iandola.
From Captions to Visual Concepts and Back.
arXiv preprint arXiv: ..., Nov. 2014.
[ bib |
.pdf ]
Keywords: Computer Science - Computation and Language,Computer Science - Computer Vision and Pattern Rec,mscthesis |
| [144] |
A. Glassner.
Principles of digital image synthesis: Vol. 1.
Elsevier, 1995.
[ bib |
http ]
Keywords: mscthesis |
| [145] |
J. Glimm, J. Impagliazzo, and I. Singer.
The legacy of John von Neumann.
American Mathematical Soc., Sept. 2006.
[ bib |
http ]
Keywords: Mathematics / General,mscthesis |
| [146] |
M. M. Gupta and G. K. Knopf.
Neuro-vision systems: A tutorial.
In Neuro-Vision Systems: Principles and Applications, pages
1-34. 1994.
[ bib |
.pdf ]
Keywords: mscthesis |
| [147] |
C. Harris and M. Stephens.
A Combined Corner and Edge Detector.
Procedings of the Alvey Vision Conference 1988, pages
23.1-23.6, 1988.
[ bib |
DOI |
.html ]
Keywords: mscthesis |
| [148] |
K. He, X. Zhang, S. Ren, and J. Sun.
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual
Recognition.
arXiv:1406.4729 [cs], June 2014.
[ bib |
.pdf ]
Keywords: Computer Science - Computer Vision and Pattern Rec,mscthesis |
| [149] |
P. O. Hoyer and A. Hyvärinen.
Independent component analysis applied to feature extraction from
colour and stereo images.
Network (Bristol, England), 11(3):191-210, Aug. 2000.
[ bib |
http ]
Keywords: Algorithms,Binocular,Binocular: physiology,Color Perception,Color Perception: physiology,Depth Perception,Depth Perception: physiology,Models,Neurological,Statistical,Vision,Visual Fields,Visual Fields: physiology,color,mscthesis |
| [150] |
A. Hyvärinen, J. Hurri, and P. O. Hoyer.
Natural Image Statistics.
39, 2009.
[ bib |
DOI |
http ]
Keywords: mscthesis |
| [151] |
K. Jarrett, K. Kavukcuoglu, M. A. Ranzato, and Y. LeCun.
What is the best multi-stage architecture for object recognition?
2009 IEEE 12th International Conference on Computer Vision,
pages 2146-2153, Sept. 2009.
[ bib |
DOI |
http ]
Keywords: mscthesis |
| [152] |
D. G. Lowe.
Distinctive Image Features from Scale-Invariant Keypoints.
International Journal of Computer Vision, 60(2):91-110, Nov.
2004.
[ bib |
DOI |
http ]
Keywords: mscthesis |
| [153] |
K. Mehrotra, C. Mohan, and S. Ranka.
Elements of artificial neural networks.
1997.
[ bib |
http ]
Keywords: mscthesis |
| [154] |
V. Mnih, N. Heess, and A. Graves.
Recurrent Models of Visual Attention.
Advances in Neural Information ..., June 2014.
[ bib |
http ]
Keywords: Computer Science - Computer Vision and Pattern Rec,Computer Science - Learning,Statistics - Machine Learning,mscthesis |
| [155] |
S. Phung, A. Bouzerdoum, and S. D. Chai.
Skin segmentation using color pixel classification: analysis and
comparison.
IEEE Transactions on Pattern Analysis and Machine Intelligence,
27(1):148-154, Jan. 2005.
[ bib |
DOI |
http ]
Keywords: Algorithms,Bayes methods,Bayesian classifier,Bayesian methods,Classification algorithms,Cluster Analysis,Color,Colorimetry,Computer Graphics,Computer Simulation,Degradation,Gaussian mixture classifier,Gaussian processes,Histograms,Image Enhancement,Image Interpretation- Computer-Assisted,Index Terms- Pixel classification,Information Storage and Retrieval,Models- Biological,Models- Statistical,Neural Networks (Computer),Pattern Recognition- Automated,Quantization,Reproducibility of Results,Sensitivity and Specificity,Signal Processing- Computer-Assisted,Skin,Skin Pigmentation,Subtraction Technique,Testing,artificial intelligence,chrominance channels,classifier design and evaluation,color pixel classification algorithm,color quantization,color space,color space representation,face detection.,histogram technique,image classification,image colour analysis,image representation,image segmentation,mscthesis,multilayer perceptron classifier,multilayer perceptrons,performance degradation,performance evaluation,piecewise linear classifiers,skin segmentation,unimodal Gaussian classifiers |
| [156] |
J. Pollack.
Connectionism: Past, present, and future.
Artificial Intelligence Review, pages 1-14, 1989.
[ bib |
http ]
Keywords: mscthesis |
| [157] |
B. Safadi, N. Derbas, A. Hamadi, T.-t.-t. Vuong, H. Dong, P. Mulhem, and G. Qu.
Quaero at TRECVid 2013 : Semantic Indexing.
2013.
[ bib |
.pdf ]
Keywords: mscthesis,trecvid |
| [158] |
F. Wilcoxon.
Individual comparisons by ranking methods.
Biometrics bulletin, 1(6):80-83, Dec. 1945.
[ bib |
DOI |
http ]
Keywords: ,Statistics- general |
| [159] |
J. Yosinski, J. Clune, Y. Bengio, and H. Lipson.
How transferable are features in deep neural networks?
pages 3320-3328. Curran Associates, Inc., 2014.
[ bib |
http ]
Keywords: mscthesis |
| [160] |
P. Agrawal, R. Girshick, and J. Malik.
Analyzing the performance of multilayer neural networks for object
recognition.
Computer Vision-ECCV 2014, pages 329-344, Jan. 2014.
[ bib |
.pdf ]
Keywords: Artificial Intelligence (incl. Robotics),Computer Graphics,Image Processing and Computer Vision,Pattern Recognition,convolutional neural networks,empirical analysis,mscthesis,object recognition |
| [161] |
P. L. Callet.
A convolutional neural network approach for objective video quality
assessment.
Neural Networks, IEEE ..., 5:1316-1327, 2006.
[ bib |
.pdf ]
Keywords: CNN,mscthesis |
| [162] |
H. Lee, P. Pham, Y. Largman, and A. Ng.
Unsupervised feature learning for audio classification using
convolutional deep belief networks.
NIPS, pages 1-9, 2009.
[ bib |
.pdf ]
Keywords: mscthesis |
| [163] |
M. Everingham and S. Eslami.
The pascal visual object classes challenge: A retrospective.
International Journal of ..., 111(1):98-136, June 2014.
[ bib |
DOI |
.pdf ]
Keywords: Artificial Intelligence (incl. Robotics),Benchmark,Computer Imaging- Vision- Pattern Recognition and Graphics,Database,Image Processing and Computer Vision,Object detection,Pattern Recognition,object recognition,segmentation |
| [164] |
J. Bruce, T. Balch, and M. Veloso.
Fast and inexpensive color image segmentation for interactive
robots.
volume 3, pages 2061-2066 vol.3, 2000.
[ bib |
DOI |
http ]
Keywords: Application software,Color,Hardware,Machine vision,Merging,Real time systems,Software systems,Sorting,color image segmentation,color space thresholding,heuristic,image colour analysis,image segmentation,mobile robot,mobile robots,mscthesis,optical tracking,perceptual grouping,robot vision,threshold classifier,tracking |
| [165] |
M. Carreira-Perpinan and G. Hinton.
On contrastive divergence learning.
...on artificial intelligence and ..., 0, 2005.
[ bib |
http ]
Keywords: mscthesis |
| [166] |
B. Copeland and D. Proudfoot.
On Alan Turing's anticipation of connectionism.
Synthese, 108(3):361-377, Sept. 1996.
[ bib |
DOI |
http ]
Keywords: Epistemology,Logic,Metaphysics,Philosophy,Philosophy of Language,mscthesis |
| [167] |
A. Fitzgibbon, S. Lazebnik, P. Perona, Y. Sato, and C. Schmid.
Computer Vision - ECCV 2012.
2012.
[ bib ]
Keywords: mscthesis |
| [168] |
D. Gabor.
Communication theory and cybernetics.
Circuit Theory, Transactions of the IRE Professional ...,
CT-1(4):19-31, Dec. 1954.
[ bib |
DOI |
http ]
Keywords: Acoustic noise,Buildings,Circuit synthesis,Cybernetics,Nonlinear equations,Nonlinear filters,Sampling methods,Signal analysis,Time measurement,mscthesis,speech recognition |
| [169] |
D. Hubel and T. Wiesel.
Receptive fields, binocular interaction and functional architecture
in the cat's visual cortex.
The Journal of physiology, pages 106-154, 1962.
[ bib |
.pdf ]
Keywords: mscthesis |
| [170] |
S. Kirkpatrick, C. D. Gelatt, and M. P. Vecchi.
Optimization by Simulated Annealing.
Science, 220(4598):671-680, 1983.
[ bib ]
Keywords: mscthesis |
| [171] |
H. Lee, R. Grosse, R. Ranganath, and A. Y. Ng.
Convolutional deep belief networks for scalable unsupervised
learning of hierarchical representations.
Proceedings of the 26th Annual International Conference on
Machine Learning - ICML '09, pages 1-8, 2009.
[ bib |
DOI |
.pdf ]
Keywords: CNN,mscthesis,trecvid |
| [172] |
W. Liu, J. C. Principe, and S. Haykin.
Kernel Adaptive Filtering: A Comprehensive Introduction.
John Wiley & Sons, Sept. 2011.
[ bib |
http ]
Keywords: Science / Waves & Wave Mechanics,Technology & Engineering / Electrical,mscthesis |
| [173] |
J. Masci, U. Meier, D. Ciresan, and J. Schmidhuber.
Stacked convolutional auto-encoders for hierarchical feature
extraction.
Artificial Neural Networks ..., pages 52-59, 2011.
[ bib |
.pdf ]
Keywords: CNN,auto-encoder,classification,convolutional neural network,learning,mscthesis,trecvid,unsupervised |
| [174] |
M. Minsky.
Theory of neural-analog reinforcement systems and its
application to the brain model problem.
PhD thesis, 1954.
[ bib |
http ]
Keywords: mscthesis |
| [175] |
M. Norouzi, M. Ranjbar, and G. Mori.
Stacks of convolutional restricted Boltzmann machines for
shift-invariant feature learning.
Computer Vision and Pattern ..., pages 2735-2742, 2009.
[ bib |
http ]
Keywords: mscthesis |
| [176] |
E. Perez, V. Mota, L. Maciel, D. Sad, and M. B. Vieira.
Combining gradient histograms using orientation tensors for human
action recognition.
Pattern Recognition (ICPR), 2012 21st International Conference
on. IEEE, 2012.
[ bib |
http ]
Keywords: mscthesis |
| [177] |
L. K. Saul, T. Jaakkola, and M. I. Jordan.
Mean Field Theory for Sigmoid Belief Networks.
arXiv:cs/9603102, Feb. 1996.
[ bib |
.pdf ]
Keywords: Computer Science - Artificial Intelligence,mscthesis |
| [178] |
C. Snoek and K. van de Sande.
MediaMill at TRECVID 2013: Searching Concepts, Objects, Instances
and Events in Video.
...of TRECVID, 2013.
[ bib |
http ]
Keywords: mscthesis,trecvid |
| [179] |
William James.
The principles of psychology.
New York : Henry Holt and company, 1890.
[ bib |
http ]
Keywords: Psychology,mscthesis |
| [180] | P. Dayan, G. Hinton, R. Neal, and R. Zemel. The helmholtz machine. Neural computation, 904:889-904, 1995. [ bib | http ] |
| [181] |
M. Everingham and L. V. Gool.
The pascal visual object classes (voc) challenge.
International journal of ..., 88(2):303-338, Sept. 2010.
[ bib |
DOI |
.pdf ]
Keywords: Artificial Intelligence (incl. Robotics),Benchmark,Computer Imaging- Vision- Pattern Recognition and Graphics,Database,Image Processing and Computer Vision,Object detection,Pattern Recognition,object recognition |
| [182] | J. Shotton, T. Sharp, and A. Kipman. Real-time human pose recognition in parts from single depth images. Communications of the ..., 56(1):116-124, Jan. 2013. [ bib | DOI | http ] |
| [183] |
Y.-T. Yeh, L. Yang, M. Watson, N. D. Goodman, and P. Hanrahan.
Synthesizing Open Worlds with Constraints Using Locally Annealed
Reversible Jump MCMC.
ACM Trans. Graph., 31(4):56:1-56:11, July 2012.
[ bib |
DOI |
http ]
Keywords: constrained synthesis,factor graphs,open worlds |
| [184] |
M. Zia, M. Stark, B. Schiele, and K. Schindler.
Detailed 3D Representations for Object Recognition and Modeling.
IEEE Transactions on Pattern Analysis and Machine Intelligence,
35(11):2608-2623, Nov. 2013.
[ bib |
DOI |
http ]
Keywords: 3D geometric object class representations,3D positions,3D representation,3D wireframes,Algorithms,Computational modeling,Computer Simulation,Computer vision,Design automation,Detectors,Geometry,Image Interpretation- Computer-Assisted,Imaging- Three-Dimensional,Models- Theoretical,Pattern Recognition- Automated,Shape,Solid modeling,Three-dimensional displays,artificial intelligence,bounding-box-based benchmarks,computational geometry,fine-grained categorization,geometric 3D reasoning,geometric detail,image 3D reconstruction,image matching,image reconstruction,image representation,inference,inference mechanisms,monocular 3D pose estimation,object class detectors,object modeling,object pose estimation,object recognition,photography,pose estimation,recognition,robust 2D matching,scene understanding,shape description,single image 3D reconstruction,solid modelling,ultrawide baseline matching,visual scene understanding |
| [185] |
O. Abdel-Hamid and A. Mohamed.
Applying convolutional neural networks concepts to hybrid NN-HMM
model for speech recognition.
Acoustics, Speech and ..., 2012.
[ bib |
http ]
Keywords: mscthesis |
| [186] |
W. Ashby.
Design for a Brain: The Origin of Adaptive Behavior.
1960.
[ bib |
http ]
Keywords: mscthesis |
| [187] |
Y. Bengio.
Learning Deep Architectures for AI, volume 2.
2009.
[ bib |
DOI |
.pdf ]
Keywords: mscthesis |
| [188] |
S. R. y. Cajal.
Histologie du systeme nerveux de l'homme & des vertebres.
page 1014, 1909.
[ bib |
http ]
Keywords: Nervous System,mscthesis |
| [189] |
D. Chai and K. Ngan.
Face segmentation using skin-color map in videophone applications.
IEEE Transactions on Circuits and Systems for Video Technology,
9(4):551-564, June 1999.
[ bib |
DOI |
http ]
Keywords: Face detection,Facial animation,H.261-compliant coder,Humans,Image coding,Layout,MPEG 4 Standard,Skin,brightness,chrominance component,complex background scene,face recognition,face-segmentation algorithm,fast algorithm,foreground/background coding,head-and-shoulders view,human skin color,image colour analysis,image segmentation,image sequences,input image,luminance,mscthesis,perceptual quality,pixels,regularization processes,reliable algorithm,simulation results,spatial distribution characteristics,test images,universal skin-color map,video coding,videophone applications,videophone sequence,videotelephony |
| [190] |
Y. L. Cun.
A theoretical framework for back-propagation.
1988.
[ bib |
http ]
Keywords: mscthesis |
| [191] |
G. Dong and J. Li.
Efficient mining of emerging patterns: Discovering trends and
differences.
Proceedings of the fifth ACM SIGKDD international ..., pages
43-52, 1999.
[ bib |
DOI |
http ]
Keywords: mscthesis |
| [192] |
D. Erhan, Y. Bengio, and A. Courville.
Why does unsupervised pre-training help deep learning?
...of Machine Learning ..., 9(2007):201-208, 2010.
[ bib |
.pdf ]
Keywords: mscthesis |
| [193] |
M. A. Fischler.
Intelligence: The Eye, the Brain, and the Computer.
Addison-Wesley, Jan. 1987.
[ bib |
http ]
Keywords: Computers / General,mscthesis |
| [194] |
Y. Fu, T. Hospedales, T. Xiang, and S. Gong.
Attribute learning for understanding unstructured social activity.
Computer Vision-ECCV 2012, 2012.
[ bib |
http ]
Keywords: mscthesis |
| [195] |
K. Fukushima, S. Miyake, and T. Ito.
Neocognitron: A neural network model for a mechanism of visual
pattern recognition.
Systems, Man and Cybernetics, ..., SMC-13(5):826-834, Sept.
1983.
[ bib |
DOI |
http ]
Keywords: Biological neural networks,Brain modeling,Computational modeling,Digital simulation,PDP-11/34 minicomputer,Pattern Recognition,Shape,Visualization,handwritten Arabic numerals,large-scale network,learning-with-a-teacher process,modifiable synapses,mscthesis,neural nets,neural network model,recognition,reinforcement,training,visual pattern recognition,visual perception |
| [196] |
F. M. Ham and I. Kostanic.
Principles of Neurocomputing for Science and Engineering.
McGraw-Hill Higher Education, 1st edition, 2000.
[ bib ]
Keywords: mscthesis |
| [197] |
S. Haykin.
Neural networks: a comprehensive foundation.
1994.
[ bib |
http ]
Keywords: mscthesis |
| [198] |
R. Hecht-Nielsen.
Neurocomputing.
Addison-Wesley Publishing Company, Jan. 1989.
[ bib |
http ]
Keywords: Computers / General,mscthesis |
| [199] |
G. Hinton, L. Deng, D. Yu, G. E. Dahl, A.-r. Mohamed, N. Jaitly, A. Senior,
V. Vanhoucke, P. Nguyen, T. N. Sainath, and B. Kingsbury.
Deep Neural Networks for Acoustic Modeling in Speech Recognition.
IEEE Signal Processing Magazine, (November):82-97, 2012.
[ bib |
.pdf ]
Keywords: CNN,mscthesis |
| [200] |
H. Jones and I. Andolina.
Differential feedback modulation of center and surround mechanisms
in parvocellular cells in the visual thalamus.
The Journal of ..., 32(45):15946-15951, Nov. 2012.
[ bib |
DOI |
http ]
Keywords: mscthesis |
| [201] |
A. Krizhevsky.
Convolutional Deep Belief Networks on CIFAR-10.
pages 1-9, 2010.
[ bib |
http ]
Keywords: mscthesis |
| [202] |
Q. V. Le, W. Y. Zou, S. Y. Yeung, and A. Y. Ng.
Learning hierarchical invariant spatio-temporal features for action
recognition with independent subspace analysis.
Cvpr 2011, pages 3361-3368, June 2011.
[ bib |
DOI |
http ]
Keywords: mscthesis |
| [203] |
Y. LeCun, B. Boser, J. Denker, D. Henderson, R. Howard, W. Hubbard, and
L. Jackel.
Backpropagation applied to handwritten zip code recognition.
Neural ..., 1989.
[ bib |
http ]
Keywords: mscthesis |
| [204] |
M. Minsky and S. Papert.
Perceptrons.
Nov. 1969.
[ bib |
http ]
Keywords: mscthesis |
| [205] |
V. Nair and G. Hinton.
Rectified linear units improve restricted boltzmann machines.
Proceedings of the 27th International ..., 2010.
[ bib |
.pdf ]
Keywords: mscthesis |
| [206] |
J. Nathans, T. Piantanida, and R. Eddy.
Molecular genetics of inherited variation in human color vision.
Science, 232(4747):203-210, Apr. 1986.
[ bib |
http ]
Keywords: Animals,Chromosome Mapping,Chromosomes- Human,Color,Color Perception,Color Vision Defects,DNA,Gene Frequency,Genes,Genetic Variation,Genotype,Humans,Mice,Nucleic Acid Hybridization,Retinal Pigments,X Chromosome |
| [207] |
P. S. Neelakanta and D. DeGroff.
Neural Network Modeling: Statistical Mechanics and Cybernetic
Perspectives.
CRC Press, July 1994.
[ bib |
http ]
Keywords: Computers / Software Development & Engineering / S,Technology & Engineering / Electronics / General,mscthesis |
| [208] |
J. von Neumann.
Probabilistic logics and the synthesis of reliable organisms from
unreliable components.
Automata studies, pages 43-98, 1956.
[ bib |
http ]
Keywords: mscthesis |
| [209] |
J. Ngiam, Z. Chen, D. Chia, P. W. Koh, and A. Y. Ng.
Tiled convolutional neural networks.
Advances in Neural ..., pages 1-9, 2010.
[ bib |
.pdf ]
Keywords: CNN,convolutional neural networks,mscthesis |
| [210] |
A. L. Norberg.
Computers and Commerce: A Study of Technology and Management at
Eckert-Mauchly Computer Company, Engineering Research Associates, and
Remington Rand, 1946 - 1957.
MIT Press, 2005.
[ bib |
http ]
Keywords: Computers / Computer Engineering,Computers / Computer Science,Computers / History,History / Modern / 20th Century,mscthesis |
| [211] |
D. Oneata, J. Verbeek, and C. Schmid.
Action and event recognition with Fisher vectors on a compact
feature set.
IEEE Intenational Conference on Computer Vision (ICCV), 2013.
[ bib |
.pdf ]
Keywords: mscthesis,trecvid |
| [212] |
E. Reinhard, W. Heidrich, and P. Debevec.
High dynamic range imaging: acquisition, display, and
image-based lighting.
Morgan Kaufmann, May 2010.
[ bib |
http ]
Keywords: Computers / Computer Graphics,mscthesis |
| [213] |
R. Rigamonti, M. a. Brown, and V. Lepetit.
Are sparse representations really relevant for image
classification?
Cvpr 2011, pages 1545-1552, June 2011.
[ bib |
DOI |
http ]
Keywords: mscthesis |
| [214] |
M. Schuster and K. K. Paliwal.
Bidirectional recurrent neural networks.
IEEE Transactions on Signal Processing, 45(11):2673-2681, Nov.
1997.
[ bib |
DOI |
http ]
Keywords: Artificial neural networks,Control systems,Databases,Parameter estimation,Probability,Recurrent neural networks,Shape,TIMIT database,Telecommunication control,Training data,artificial data,bidirectional recurrent neural networks,classification experiments,complete symbol sequences,conditional posterior probability,learning by example,learning from examples,mscthesis,negative time direction,pattern classification,phonemes,positive time direction,real data,recurrent neural nets,regression experiments,regular recurrent neural network,speech processing,speech recognition,statistical analysis,training |
| [215] |
M. Seeger.
Gaussian processes for machine learning., volume 14.
May 2004.
[ bib |
http ]
Keywords: Algorithms,Artificial Intelligence,Bayes Theorem,Entropy,Linear Models,Models, Statistical,Normal Distribution,Regression Analysis,Statistics, Nonparametric,mscthesis |
| [216] |
J. T. Springenberg and M. Riedmiller.
Improving Deep Neural Networks with Probabilistic Maxout Units.
Dec. 2013.
[ bib |
arXiv |
http ]
Keywords: mscthesis |
| [217] |
C. Szegedy, W. Zaremba, and I. Sutskever.
Intriguing properties of neural networks.
arXiv preprint arXiv: ..., pages 1-9, 2013.
[ bib |
http ]
Keywords: mscthesis |
| [218] |
G. Taylor, R. Fergus, Y. LeCun, and C. Bregler.
Convolutional learning of spatio-temporal features.
Computer Vision-ECCV 2010, 2010.
[ bib |
http ]
Keywords: activity recognition,con-,mscthesis,optical flow,restricted boltzmann machines,unsupervised learning,video analysis,volutional nets |
| [219] |
C. von der Malsburg and D. J. Willshaw.
A mechanism for producing continuous neural mappings: ocularity
dominance stripes and ordered retino-tectal projections.
Exp. Brain Res, 1:463-469, 1976.
[ bib ]
Keywords: mscthesis |
| [220] |
D. J. Willshaw, O. P. Buneman, and H. C. Longuet-Higgins.
Non-Holographic Associative Memory.
Nature, 222(5197):960-962, June 1969.
[ bib |
DOI |
.pdf ]
Keywords: mscthesis |
| [221] |
M. D. Zeiler, G. W. Taylor, and R. Fergus.
Adaptive deconvolutional networks for mid and high level feature
learning.
2011 International Conference on Computer Vision, pages
2018-2025, Nov. 2011.
[ bib |
DOI |
http ]
Keywords: mscthesis |
| [222] |
N. Zhang, J. Donahue, R. Girshick, and T. Darrell.
Part-based R-CNNs for fine-grained category detection.
Computer Vision–ECCV 2014, pages 834-849, Jan. 2014.
[ bib |
.pdf ]
Keywords: Artificial Intelligence (incl. Robotics),Computer Graphics,Fine-grained recognition,Image Processing and Computer Vision,Object detection,Pattern Recognition,convolutional models,mscthesis |
| [223] |
S.-I. Amari.
Characteristics of Random Nets of Analog Neuron-Like Elements.
IEEE Transactions on Systems, Man and Cybernetics,
SMC-2(5):643-657, Nov. 1972.
[ bib |
DOI |
http ]
Keywords: Biological neural networks,Equations,Frequency,Instruments,Microscopy,Neurons,Pulse modulation,Signal processing,Stability criteria,Stochastic processes,mscthesis |
| [224] |
J. Anderson.
A simple neural network generating an interactive memory.
Mathematical Biosciences, 14(3-4):197-220, Aug. 1972.
[ bib |
DOI |
http ]
Keywords: mscthesis |
| [225] |
S. Ayache, G. Quénot, and J. Gensel.
Classifier fusion for SVM-based multimedia semantic indexing.
Springer Berlin Heidelberg, 2007.
[ bib ]
Keywords: mscthesis |
| [226] |
K. Bezdek, A. Deza, and Y. Ye.
Discrete geometry and optimization.
Springer Science & Business Media, July 2013.
[ bib |
.pdf ]
Keywords: Mathematics / Geometry / General,Mathematics / Optimization,mscthesis |
| [227] |
D. Broomhead and D. Lowe.
Radial basis functions, multi-variable functional interpolation and
adaptive networks.
Mar. 1988.
[ bib |
http ]
Keywords: *ADAPTIVE SYSTEMS,*INTERPOLATION,*LEARNING,*MULTIVARIATE ANALYSIS,*NETWORKS,Active & Passive Radar Detection & Equipment,DATA BASES,FITTINGS,FOREIGN REPORTS,LAYERS,LINEAR DIFFERENTIAL EQUATIONS,NONLINEAR SYSTEMS,SIZES(DIMENSIONS),SOLUTIONS(GENERAL),SURFACES,UNITED KINGDOM,mscthesis |
| [228] |
P. Burt and E. Adelson.
The Laplacian pyramid as a compact image code.
Communications, IEEE Transactions on, 31(4):532-540, Apr.
1983.
[ bib |
DOI |
http ]
Keywords: Data compression,Data structures,Entropy,Frequency,Image coding,Image sampling,Laplace equations,Low pass filters,Pixel,Shape |
| [229] | P. Churchland and T. Sejnowski. Perspectives on cognitive neuroscience. Science, 242(4879):741-745, Nov. 1988. [ bib | DOI | http ] |
| [230] |
D. Ciresan, A. Giusti, and J. Schmidhuber.
Mitosis detection in breast cancer histology images with deep neural
networks.
Medical Image ..., 2013.
[ bib |
.pdf ]
Keywords: CNN,mscthesis |
| [231] |
B. Copeland.
Alan Turing's Electronic Brain: The Struggle to Build the ACE,
the World's Fastest Computer.
Oxford University Press, May 2012.
[ bib |
http ]
Keywords: Biography & Autobiography / Science & Technology,Computers / Social Aspects / General,Computers / Systems Architecture / General,Mathematics / General,Mathematics / History & Philosophy,Philosophy / General,Science / History,Science / Philosophy & Social Aspects,mscthesis |
| [232] |
B. G. Cragg and H. N. V. Temperley.
Memory: The Analogy with Ferromagnetic Hysteresis.
Brain, 78(2):304-316, June 1955.
[ bib |
DOI |
http ]
Keywords: mscthesis |
| [233] |
B. Farley and W. Clark.
Simulation of self-organizing systems by digital computer.
...of the IRE Professional Group on, 4(4):76-84, Sept.
1954.
[ bib |
DOI |
http ]
Keywords: Computational modeling,Computer Simulation,Contracts,Equations,Information systems,Laboratories,Mechanical factors,Organizing,TV,Tellurium,Time measurement,Transforms,mscthesis |
| [234] |
C. Freeman.
Feature selection and hierarchical classifier design with
applications to human motion recognition.
PhD thesis, 2014.
[ bib |
.pdf ]
Keywords: mscthesis |
| [235] |
K. Fukushima.
Neocognitron: A Self-organizing Neural Network Model for a Mechanism
of Pattern Recognition Unaffected by Shift in Position.
202, 1980.
[ bib ]
Keywords: mscthesis,visual cortex |
| [236] |
D. Gabbay, J. Woods, and P. Thagard.
Philosophy of Psychology and Cognitive Science: A Volume of the
Handbook of the Philosophy of Science Series.
Elsevier, Oct. 2006.
[ bib |
http ]
Keywords: Computers / Intelligence (AI) & Semantics,Psychology / Cognitive Psychology,Psychology / Cognitive Psychology & Cognition,mscthesis |
| [237] |
J. Garson.
Connectionism.
Winter 201 edition, 2012.
[ bib |
http ]
Keywords: artificial intelligence,language of thought hypothesis,mental representation,mscthesis |
| [238] |
I. J. Goodfellow, D. Warde-Farley, M. Mirza, A. Courville, and Y. Bengio.
Maxout Networks.
pages 1319-1327, Feb. 2013.
[ bib |
arXiv |
http ]
Keywords: mscthesis |
| [239] |
I. Goodfellow, Y. Bulatov, J. Ibarz, S. Arnoud, and V. Shet.
Multi-digit Number Recognition from Street View Imagery using Deep
Convolutional Neural Networks.
arXiv preprint arXiv: ..., pages 1-13, 2013.
[ bib |
arXiv |
http ]
Keywords: mscthesis |
| [240] |
T. Hao, T. Raiko, A. Ilin, and J. Karhunen.
Gated boltzmann machine in texture modeling.
...Neural Networks and Machine ..., 2012.
[ bib |
.pdf ]
Keywords: color,deep learn-,gated boltzmann machine,gaussian restricted boltzmann machine,ing,mscthesis,texture analysis |
| [241] |
D. Hartley.
Observations on man, his frame, his duty, and his
expectations.
00 L : Scholars' Facsimiles and Reprints, 1749.
[ bib |
http ]
Keywords: Philosophy,mscthesis |
| [242] |
D. O. Hebb.
The Orgamization of Behavior a Neuropsychological Theory.
John Wiley & Sons Inc., New York, 1949.
[ bib ]
Keywords: mscthesis |
| [243] |
G. E. Hinton, P. Dayan, B. J. Frey, and R. M. Neal.
The "wake-sleep" algorithm for unsupervised neural networks.
Science (New York, N.Y.), 268(5214):1158-61, May 1995.
[ bib |
http ]
Keywords: Algorithms,Neural Networks (Computer),Probability,Stochastic Processes,mscthesis |
| [244] |
G. Hinton, S. Osindero, and Y. Teh.
A fast learning algorithm for deep belief nets.
Neural computation, 1554:1527-1554, 2006.
[ bib |
http ]
Keywords: mscthesis |
| [245] |
G. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov.
Improving neural networks by preventing co-adaptation of feature
detectors.
arXiv preprint arXiv: ..., pages 1-18, 2012.
[ bib |
arXiv |
.pdf ]
Keywords: mscthesis |
| [246] |
G.-B. Huang, Q.-Y. Zhu, and C.-K. Siew.
Extreme learning machine: Theory and applications.
Neurocomputing, 70(1-3):489-501, Dec. 2006.
[ bib |
DOI |
http ]
Keywords: back-propagation algorithm,extreme learning machine,feedforward neural networks,mscthesis,random,real-time learning,support vector machine |
| [247] |
D. Hubel and T. Wiesel.
Receptive fields and functional architecture of monkey striate
cortex.
The Journal of physiology, pages 215-243, 1968.
[ bib |
.pdf ]
Keywords: mscthesis,visual cortex |
| [248] |
A. Hyvärinen and P. Hoyer.
Emergence of phase-and shift-invariant features by decomposition of
natural images into independent feature subspaces.
Neural computation, 1720:1705-1720, 2000.
[ bib |
http ]
Keywords: mscthesis |
| [249] |
A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, and L. Fei-Fei.
Large-scale Video Classification with Convolutional Neural
Networks.
vision.stanford.edu, 2014.
[ bib |
.pdf ]
Keywords: mscthesis |
| [250] |
K. Kavukcuoglu, P. Sermanet, Y.-l. Boureau, Y. LeCun, K. Gregor, and
M. Mathieu.
Learning Convolutional Feature Hierarchies for Visual Recognition.
NIPS, (1):1-9, 2010.
[ bib |
.pdf ]
Keywords: CNN,mscthesis |
| [251] |
J. King.
Why color management?
9th Congress of the International Color ..., 2002.
[ bib |
.pdf ]
Keywords: color,mscthesis |
| [252] |
T. Lindeberg.
Feature detection with automatic scale selection.
International journal of computer vision, 30(2):79-116, Nov.
1998.
[ bib |
DOI |
.pdf ]
Keywords: Artificial Intelligence (incl. Robotics),Automation and Robotics,Computer Imaging- Graphics and Computer Vision,Computer vision,Gaussian derivative,Image Processing,blob detection,corner detection,feature detection,frequency estimation,mscthesis,multi-scale representation,normalized derivative,scale,scale selection,scale-space |
| [253] |
W. A. Little and G. L. Shaw.
A statistical theory of short and long term memory.
Behavioral Biology, 14(2):115-133, June 1975.
[ bib |
DOI |
http ]
Keywords: mscthesis |
| [254] |
J. Locke.
An essay concerning human understanding.
Read Books, Nov. 1700.
[ bib |
http ]
Keywords: Literary Collections / Essays,Philosophy / General,mscthesis |
| [255] |
J. L. Long, N. Zhang, and T. Darrell.
Do Convnets Learn Correspondence?
pages 1601-1609. Curran Associates, Inc., 2014.
[ bib |
http ]
Keywords: mscthesis |
| [256] |
C. von der Malsburg.
Self-organization of orientation sensitive cells in the striate
cortex.
Kybernetik, 14(2):85-100, June 1973.
[ bib |
DOI |
http ]
Keywords: Neurosciences,Zoology,mscthesis |
| [257] |
M. Marszalek, I. Laptev, and C. Schmid.
Actions in context.
Computer Vision and ..., (i):2929-2936, 2009.
[ bib |
http ]
Keywords: mscthesis |
| [258] |
K. Mikolajczyk and C. Schmid.
A performance evaluation of local descriptors.
Pattern Analysis and Machine ..., 27(10):1615-1630, Oct.
2005.
[ bib |
DOI |
http ]
Keywords: Algorithms,Computer Simulation,Data Interpretation- Statistical,Detectors,Filters,Image Enhancement,Image Interpretation- Computer-Assisted,Image databases,Image recognition,Image retrieval,Index Terms- Local descriptors,Information Storage and Retrieval,Information retrieval,Interest points,Layout,Models- Statistical,Pattern Recognition- Automated,Robustness,Software,Software Validation,Spatial databases,artificial intelligence,complex filters,correlation methods,cross-correlation,filtering theory,image classification,image matching,image transformations,interest regions,invariance,local descriptors,matching,moment invariants,mscthesis,performance evaluation,recognition.,spin images,steerable filters |
| [259] |
K. Mikolajczyk and C. Schmid.
Scale & affine invariant interest point detectors.
International journal of computer vision, 60(1):63-86, Oct.
2004.
[ bib |
DOI |
.pdf ]
Keywords: Artificial Intelligence (incl. Robotics),Automation and Robotics,Computer Imaging- Graphics and Computer Vision,Image Processing,Interest points,Local features,affine invariance,matching,mscthesis,recognition,scale invariance |
| [260] | J. Ngiam, A. Khosla, M. Kim, J. Nam, H. Lee, and A. Y. Ng. Multimodal deep learning. International Conference on Machine Learning, 28, 2011. [ bib | .pdf ] |
| [261] |
J. C. Niebles, H. Wang, and L. Fei-Fei.
Unsupervised Learning of Human Action Categories Using
Spatial-Temporal Words.
International Journal of Computer Vision, 79(3):299-318, Mar.
2008.
[ bib |
DOI |
http ]
Keywords: action categorization,bag of words,mscthesis,spatio-temporal interest points,topic models,unsupervised learning |
| [262] |
F. Ning, D. Delhomme, Y. LeCun, F. Piano, L. Bottou, and P. E. Barbano.
Toward automatic phenotyping of developing embryos from videos.
IEEE transactions on image processing : a publication of the
IEEE Signal Processing Society, 14(9):1360-71, Sept. 2005.
[ bib |
http ]
Keywords: Algorithms,Animals,Artificial Intelligence,Automated,Automated: methods,Caenorhabditis elegans,Caenorhabditis elegans: anatomy & histology,Caenorhabditis elegans: classification,Caenorhabditis elegans: embryology,Caenorhabditis elegans: growth & development,Computer-Assisted,Computer-Assisted: methods,Embryo,Fetal Development,Fetal Development: physiology,Image Enhancement,Image Enhancement: methods,Image Interpretation,Microscopy,Nonmammalian,Nonmammalian: cytology,Pattern Recognition,Phase-Contrast,Phase-Contrast: methods,Phenotype,Reproducibility of Results,Sensitivity and Specificity,Video,Video: methods,mscthesis |
| [263] |
S. Nowozin and C. Lampert.
Structured learning and prediction in computer vision.
...and Trends® in Computer Graphics and Vision,
6(3–4):185-365, Mar. 2011.
[ bib |
DOI |
http ]
Keywords: mscthesis |
| [264] |
D. Parker.
Learning-logic.
Technical report, Invention Report S81-64, File 1, Cambridge, MA:
Center for Computational Research in Economics and Management Science, MIT.,
1982.
[ bib ]
Keywords: mscthesis |
| [265] |
J. Pearl.
Probabilistic Reasoning in Intelligent Systems: Networks of
Plausible Inference.
Morgan Kaufmann, 1997.
[ bib |
http ]
Keywords: Computers / Intelligence (AI) & Semantics,mscthesis |
| [266] |
K. Petersen and M. Pedersen.
The matrix cookbook.
Technical University of Denmark, pages 1-56, 2008.
[ bib |
.pdf ]
Keywords: acknowledgements,christian rishøj,contribu-,derivative of,derivative of inverse matrix,determinant,differentiate a matrix,douglas l,esben hoegh-,matrix algebra,matrix identities,matrix relations,mscthesis,thank the following for,theobald,tions and suggestions,we would like to |
| [267] |
N. Rochester and J. Holland.
Tests on a cell assembly theory of the action of the brain, using a
large digital computer.
Information Theory, IRE ..., 2(3):80-93, Sept. 1956.
[ bib |
DOI |
http ]
Keywords: Assembly,Brain,Brain modeling,Computational modeling,Electronic equipment testing,Fractionation,Laboratories,Neurons,Neurophysiology,Organisms,Psychology,mscthesis,neural networks |
| [268] |
F. Rosenblatt.
Principles of neurodynamics. perceptrons and the theory of brain
mechanisms.
Technical report, Cornell Aeronautical Laboratory, INC., Buffalo 21,
N.Y., Mar. 1961.
[ bib |
http ]
Keywords: *CYBERNETICS,*NERVOUS SYSTEM,*NEURODYNAMICS,*PERCEPTION,Anatomy and Physiology,Brain,Computers,Cybernetics,Mathematical analysis,Psychology,THEORY,mscthesis |
| [269] |
K. Schindler and L. van Gool.
Action snippets: How many frames does human action recognition
require?
2008 IEEE Conference on Computer Vision and Pattern
Recognition, pages 1-8, June 2008.
[ bib |
DOI |
http ]
Keywords: mscthesis |
| [270] |
C. Schuldt, I. Laptev, and B. Caputo.
Recognizing human actions: a local SVM approach.
Pattern Recognition, 2004. ..., pages 3-7, 2004.
[ bib |
http ]
Keywords: mscthesis |
| [271] |
K. Simonyan and A. Zisserman.
Two-stream convolutional networks for action recognition in videos.
Advances in Neural Information ..., June 2014.
[ bib |
http ]
Keywords: Computer Science - Computer Vision and Pattern Rec,mscthesis |
| [272] |
N. Srivastava and G. Hinton.
Dropout: A Simple Way to Prevent Neural Networks from Overfitting.
Journal of Machine ..., 15:1929-1958, 2014.
[ bib |
.html ]
Keywords: deep learning,model combination,mscthesis,neural networks,regularization |
| [273] |
D. Svozil, V. Kvasnicka, and J. Pospichal.
Introduction to multi-layer feed-forward neural networks.
Chemometrics and intelligent ..., 39:43-62, 1997.
[ bib |
http ]
Keywords: mscthesis,neural networks |
| [274] |
C. Szegedy, W. Liu, Y. Jia, and P. Sermanet.
Going deeper with convolutions.
arXiv preprint arXiv: ..., Sept. 2014.
[ bib |
.pdf ]
Keywords: Computer Science - Computer Vision and Pattern Rec,mscthesis |
| [275] |
A. M. Uttley.
Temporal and spatial patterns in a conditional probability machine.
Automata Studies, pages 277- 285, 1956.
[ bib ]
Keywords: mscthesis |
| [276] |
V. R. Vemuri.
Artificial Neural Networks: Concepts and Control Applications.
ieeexplore.ieee.org, page 509, Sept. 1992.
[ bib |
.pdf ]
Keywords: mscthesis |
| [277] |
W. Voravuthikunchai.
Histograms of pattern sets for image classification and object
recognition.
IEEE Conference on ..., pages 224-231, 2014.
[ bib |
http ]
Keywords: mscthesis |
| [278] |
H. Wang, M. M. Ullah, A. Klaser, I. Laptev, and C. Schmid.
Evaluation of local spatio-temporal features for action
recognition.
Procedings of the British Machine Vision Conference 2009, pages
124.1-124.11, 2009.
[ bib |
DOI |
.html ]
Keywords: mscthesis |
| [279] |
B. Widrow.
An Adaptive "ADALINE" Neuron Using Chemical "Memistors".
Technical report, Solid-State Electronics Laboratory, Stanford
Electronics Laboratories, Stanford University, Stanford, California, 1960.
[ bib ]
Keywords: mscthesis |
| [280] |
R. Williams and D. Zipser.
A learning algorithm for continually running fully recurrent neural
networks.
Neural computation, 1(2):270-280, June 1989.
[ bib |
DOI |
http ]
Keywords: mscthesis |
| [281] | T. Young. The Bakerian lecture: On the theory of light and colours. Philosophical transactions of the Royal Society of ..., 92:12-48, Jan. 1802. [ bib | DOI | http ] |
| [282] |
J. Zhang and M. Marszalek.
Local features and kernels for classification of texture and object
categories: A comprehensive study.
International journal of ..., 73(2):213-238, June 2007.
[ bib |
DOI |
.pdf ]
Keywords: Artificial Intelligence (incl. Robotics),Computer Imaging- Vision- Pattern Recognition and,Image Processing and Computer Vision,Pattern Recognition,image classification,kernel methods,keypoints,mscthesis,object recognition,scale- and affine-invariant,support vector machines,texture recognition |
| [283] |
B. Boser, I. Guyon, and V. Vapnik.
A training algorithm for optimal margin classifiers.
...of the fifth annual workshop on ..., pages 144-152,
1992.
[ bib |
http ]
Keywords: mscthesis |
| [284] |
M. Brown and D. Lowe.
Automatic panoramic image stitching using invariant features.
International journal of computer vision, 74(1):59-73, Aug.
2007.
[ bib |
DOI |
.pdf ]
Keywords: Artificial Intelligence (incl. Robotics),Computer Imaging- Vision- Pattern Recognition and Graphics,Image Processing and Computer Vision,Pattern Recognition,multi-image matching,recognition,stitching |
| [285] |
N. Dalal and B. Triggs.
Histograms of oriented gradients for human detection.
...and Pattern Recognition, 2005. CVPR 2005 ...,
1:886-893 vol. 1, June 2005.
[ bib |
DOI |
http ]
Keywords: High performance computing,Histograms,Humans,Image databases,Image edge detection,Object detection,Robustness,Testing,coarse spatial binning,contrast normalization,edge based descriptors,feature extraction,fine orientation binning,fine-scale gradients,gradient based descriptors,gradient methods,histograms of oriented gradients,human detection,linear SVM,mscthesis,object recognition,overlapping descriptor,pedestrian database,robust visual object recognition,support vector machines |
| [286] |
S. Ji, M. Yang, and K. Yu.
3D convolutional neural networks for human action recognition.
IEEE transactions on pattern analysis and machine intelligence,
35(1):221-31, Jan. 2013.
[ bib |
DOI |
http ]
Keywords: Algorithms,Automated,Automated: methods,Computer-Assisted,Computer-Assisted: methods,Decision Support Techniques,Image Interpretation,Imaging,Movement,Movement: physiology,Neural Networks (Computer),Pattern Recognition,Subtraction Technique,Three-Dimensional,Three-Dimensional: methods,mscthesis |
| [287] |
Y. Ke and R. Sukthankar.
PCA-SIFT: a more distinctive representation for local image
descriptors.
volume 2, pages II-506-II-513 Vol.2, June 2004.
[ bib |
DOI |
http ]
Keywords: Computer science,Computer vision,Filters,Histograms,Image retrieval,Object detection,Robustness,feature extraction,image deformations,image gradient,image registration,image representation,image retrieval application,local feature detection,local image descriptor,mscthesis,object recognition,object recognition algorithms,principal component analysis,principal components analysis |
| [288] |
Y. LeCun.
Generalization and network design strategies.
Connections in Perspective. North-Holland, ..., 1989.
[ bib |
.pdf ]
Keywords: mscthesis |
| [289] |
K. Mikolajczyk, T. Tuytelaars, C. Schmid, A. Zisserman, J. Matas,
F. Schaffalitzky, T. Kadir, and L. V. Gool.
A comparison of affine region detectors.
International journal of ..., 65(1-2):43-72, Nov. 2005.
[ bib |
DOI |
.pdf ]
Keywords: Artificial Intelligence (incl. Robotics),Computer Imaging- Graphics and Computer Vision,Image Processing,Local features,Pattern Recognition,affine region detectors,invariant image description,mscthesis,performance evaluation |
| [290] |
K. Simonyan, A. Vedaldi, and A. Zisserman.
Deep Fisher networks for large-scale image classification.
Advances in neural ..., pages 163-171, 2013.
[ bib |
http ]
Keywords: mscthesis |
| [291] |
F. T. Sommer, T. Wennekers, and E. C. Real.
Models of distributed associative memory networks in the brain ∗.
122(1949):55-69, 2003.
[ bib ]
Keywords: bidirectional associa-,cell assemblies,cognitive modeling,memory systems,mscthesis,reciprocal connections,tive memory |
| [292] |
Y. Taigman, M. Yang, M. A. Ranzato, and L. Wolf.
DeepFace: Closing the Gap to Human-Level Performance in Face
Verification.
2014.
[ bib |
.pdf ]
Keywords: mscthesis |
| [293] |
M. Zeiler and R. Fergus.
Visualizing and Understanding Convolutional Networks.
arXiv preprint arXiv:1311.2901, 2013.
[ bib |
arXiv |
.pdf ]
Keywords: CNN,mscthesis |
This file was generated by bibtex2html 1.97.