


We implemented the algorithms for LOHMM using Sicstus-![]() .
.![]() .
.![]() Prolog. The LOHMM in (1) was used to generate data
sequences of length 10. The train set consisted of 20 sequences and
the test set consisted of 50 sequences. The parameters of the LOHMM
were randomly initialised and estimated from fraction of the training
data using the componentwise Bayes estimator. It took about 10
iterations to reach our stopping criterion: increase of less than
Prolog. The LOHMM in (1) was used to generate data
sequences of length 10. The train set consisted of 20 sequences and
the test set consisted of 50 sequences. The parameters of the LOHMM
were randomly initialised and estimated from fraction of the training
data using the componentwise Bayes estimator. It took about 10
iterations to reach our stopping criterion: increase of less than
![]() in the log likelihood of the training data. We measured the
likelihood of the test set for each learned model.
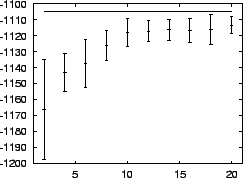
Figure 1 shows how the results (expectedly) get
better with more data to learn from.
in the log likelihood of the training data. We measured the
likelihood of the test set for each learned model.
Figure 1 shows how the results (expectedly) get
better with more data to learn from.
 |