


Next: Direct Control (DC)
Up: Learning Nonlinear State-Space Models
Previous: Task-Oriented Identification
Control Schemes
So far only passive observation and learning has been considered. Now
we come to the question how the control signals (or actions) are
selected. That is, given the history of observations
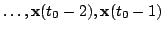 and control signals
and control signals
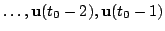 , select a good control signal
, select a good control signal
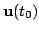 at the current time
at the current time 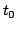 . Then, a new
observation
. Then, a new
observation
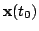 is made and time is increased by one.
Three different control schemes and their cooperation
are studied below and summarised in
Table I.
is made and time is increased by one.
Three different control schemes and their cooperation
are studied below and summarised in
Table I.
Subsections
Tapani Raiko
2005-05-23