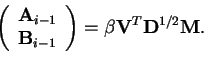The network is initialised as a single layer, that is n=1. This
means that there are only variance neurons connected to the
observations. A new layer i>1 can be added during the learning. The
means of matrixes
Ai-1 and
Bi-1 are
initialised by applying vector quantisation [1] to the
whitened mean of concatenated vectors
si-1(t) and
ui-1(t)
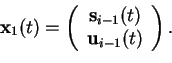 |
(6.1) |
The whitened vector
x2(t) of
x1(t) is obtained
from singular value decomposition
| x2(t) = D-1/2Vx1(t), | (6.2) |
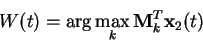 |
(6.3) |
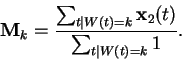 |
(6.4) |
Finally the initial values for
Ai-1 and
Bi-1 are
![[*]](cross_ref_motif.gif) .
.
The posterior means of sources
si(t) were initialised to
-2 and the means of
ui(t) were initialised to -1.
These very simple initial values of the sources are not harmful,
because of a special state explained in Section .
The posterior variances of
si(t),
ui(t),
Ai-1 and
Bi-1 are initialised to small values.