There are some special states in the learning algorithm. The states are layer-specific and can be active together. For example after rebooting, only the sources are updated for a while by keeping the weights constant. When learning an MLP-like network, the uppermost sources can be kept constant while updating the rest of the network. After adding a new layer to the network, the old parts can be kept constant and just learn the new part.
New neurons can be ``kept alive'' encouraging new
neurons to be used instead of dampened off. This is achieved by
modifying the propagated derivatives of the cost function in the
multiplication node. The last term of derivate in
equation (![[*]](cross_ref_motif.gif) ),
),
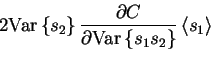 |
(6.8) |