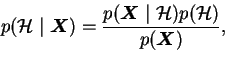Ensemble learning offers another important benefit. Comparison of
different models is straightforward. The Bayes rule can be applied
again to get the probability of a model given the data
![[*]](cross_ref_motif.gif) )
)
Multiple models can be used as a mixture of experts model
[24]. The experts can be weighted with their probabilities
given in equation (). If the models have equal
prior probabilities and the parameter approximations
CKL are
equally good, the weights simplify to ![]() .
In practice, the
costs tend to differ in the order of hundreds or thousands, which
makes the model with the lowest cost C dominant. Therefore it is
reasonable to concentrate on model selection rather than weighting.
.
In practice, the
costs tend to differ in the order of hundreds or thousands, which
makes the model with the lowest cost C dominant. Therefore it is
reasonable to concentrate on model selection rather than weighting.