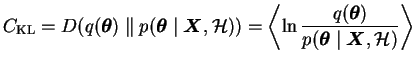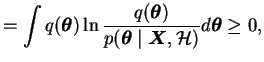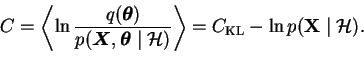Ensemble learning [25,3,44,52] is
one type of variational learning. The basic idea in ensemble learning
is to minimise the misfit between the exact posterior pdf
![]() and its parametric approximation
and its parametric approximation
![]() .
The misfit is measured with the Kullback-Leibler (KL) divergence
.
The misfit is measured with the Kullback-Leibler (KL) divergence
The terms C and
CKL differ by the term
![]() ,
the logarithm of the evidence. While optimising the distribution
,
the logarithm of the evidence. While optimising the distribution
![]() for a single model
for a single model
![]() ,
the evidence is constant and can be
ignored.
,
the evidence is constant and can be
ignored.
The cost function can be divided to a sum C=Cq+Cp, where
Density estimates of continuous valued latent variables offer a great advantage over point estimates in being robust against over-fitting and providing a cost function suitable for learning model structures. With ensemble learning the density estimates can be almost as efficient as point estimates. Roberts [58] compared Laplace approximation, sample based and ensemble learning with ICA problem on music data. The sources were well recovered using ensemble learning and the approach was considerably faster than the other methods.