The final rightmost variance model in Fig. 6 is
somewhat involved in that it contains both nonlinearities and hierarchical
modelling of variances. Before going into its mathematical details and into
the two simpler models in Fig. 6, we point out that we
have considered in our earlier papers related but simpler block models.
In Valpola03ICA_Nonlin, a hierarchical nonlinear model for the
data
![]() is discussed without modelling the variance. Such a model
can be applied for example to nonlinear ICA or blind source separation.
Experimental results Valpola03ICA_Nonlin show that this block model
performs adequately in the nonlinear BSS problem, even though the results are
slightly poorer than for our earlier computationally more demanding
model Lappalainen00,Valpola03IEICE,Honkela05NIPS with multiple computational paths.
is discussed without modelling the variance. Such a model
can be applied for example to nonlinear ICA or blind source separation.
Experimental results Valpola03ICA_Nonlin show that this block model
performs adequately in the nonlinear BSS problem, even though the results are
slightly poorer than for our earlier computationally more demanding
model Lappalainen00,Valpola03IEICE,Honkela05NIPS with multiple computational paths.
In another paper Valpola04SigProc, we have considered hierarchical modelling of variance using the block approach without nonlinearities. Experimental results on biomedical MEG (magnetoencephalography) data demonstrate the usefulness of hierarchical modelling of variances and existence of variance sources in real-world data.
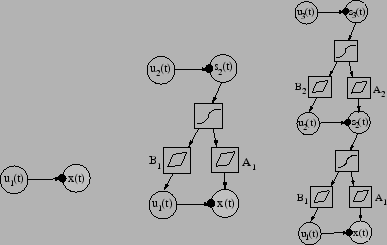 |
Learning starts from the simple structure shown in the left
subfigure of Fig. 6. There a variance source is
attached to each Gaussian observation node. The nodes represent vectors,
with
![]() being the output vector of the variance source and
being the output vector of the variance source and
![]() the
the
![]() th observation (data) vector. The vectors
th observation (data) vector. The vectors
![]() and
and
![]() have the same dimension, and each component of the variance
vector
have the same dimension, and each component of the variance
vector
![]() models the variance of the respective component of
the observation vector
models the variance of the respective component of
the observation vector
![]() .
.
Mathematically, this simple first model obeys the equations
Consider then the intermediate model shown in the middle subfigure
of Fig. 6. In this second learning stage,
a layer of sources with variance sources attached to them is added.
These sources are represented by the source vector
![]() , and
their variances are given by the respective components of the variance
vector
, and
their variances are given by the respective components of the variance
vector
![]() quite similarly as in the left subfigure.
The (vector) node between the source vector
quite similarly as in the left subfigure.
The (vector) node between the source vector
![]() and the
variance vector
and the
variance vector
![]() represents an affine transformation
with a transformation matrix
represents an affine transformation
with a transformation matrix
![]() including a bias term. Hence
the prior mean inputted to the Gaussian variance source having the output
including a bias term. Hence
the prior mean inputted to the Gaussian variance source having the output
![]() is of the form
is of the form
![]() , where
, where
![]() is the bias vector, and
is the bias vector, and
![]() is a vector of componentwise
nonlinear functions (9). Quite similarly, the vector node
between
is a vector of componentwise
nonlinear functions (9). Quite similarly, the vector node
between
![]() and the observation vector
and the observation vector
![]() yields as its
output the affine transformation
yields as its
output the affine transformation
![]() ,
where
,
where ![]() is a bias vector. This in turn provides the input
prior mean to the Gaussian node modelling the observation vector
is a bias vector. This in turn provides the input
prior mean to the Gaussian node modelling the observation vector
![]() .
.
The mathematical equations corresponding to the model represented graphically in the middle subfigure of Fig. 6 are:
Compared with the simplest model (33)-(34),
one can observe that the source vector
![]() of the
second (upper) layer and
the associated variance vector
of the
second (upper) layer and
the associated variance vector
![]() are of quite similar form,
given in Eqs. (39)-(40). The models
(37)-(38) of the data vector
are of quite similar form,
given in Eqs. (39)-(40). The models
(37)-(38) of the data vector
![]() and the associated variance vector
and the associated variance vector
![]() in the first (bottom)
layer differ from the simple first model (33)-(34)
in that they contain additional terms
in the first (bottom)
layer differ from the simple first model (33)-(34)
in that they contain additional terms
![]() and
and
![]() , respectively. In these terms, the nonlinear
transformation
, respectively. In these terms, the nonlinear
transformation
![]() of the source vector
of the source vector
![]() coming from the upper layer have been multiplied by the linear mixing
matrices
coming from the upper layer have been multiplied by the linear mixing
matrices ![]() and
and ![]() . All the ``noise'' terms
. All the ``noise'' terms
![]() ,
,
![]() ,
,
![]() , and
, and
![]() in Eqs. (37)-(40) are modelled by similar zero mean
Gaussian distributions as in Eqs. (35) and (36).
in Eqs. (37)-(40) are modelled by similar zero mean
Gaussian distributions as in Eqs. (35) and (36).
In the last stage of learning, another layer is added on the top of the
network shown in the middle subfigure of Fig. 6.
The resulting structure is shown in the right subfigure. The added new
layer is quite similar as the layer added in the second stage. The prior
variances represented by the vector
![]() model the source
vector
model the source
vector
![]() , which is turn affects via the affine transformation
, which is turn affects via the affine transformation
![]() to the mean of the mediating variance
node
to the mean of the mediating variance
node
![]() . The source vector
. The source vector
![]() provides also
the prior mean of the source
provides also
the prior mean of the source
![]() via the affine transformation
via the affine transformation
![]() .
.
The model equations (37)-(38) for the data
vector
![]() and its associated variance vector
and its associated variance vector
![]() remain the same as in the intermediate model shown graphically in
the middle subfigure of Fig. 6. The model equations
of the second and third layer sources
remain the same as in the intermediate model shown graphically in
the middle subfigure of Fig. 6. The model equations
of the second and third layer sources
![]() and
and
![]() as
well as their respective variance vectors
as
well as their respective variance vectors
![]() and
and
![]() in the rightmost subfigure of Fig. 6 are given by
in the rightmost subfigure of Fig. 6 are given by
It should be noted that in the resulting network the number of scalar-valued nodes (size of the layers) can be different for different layers. Additional layers could be appended in the same manner. The final network of the right subfigure in Fig. 6 utilises variance nodes in building a hierarchical model for both the means and variances. Without the variance sources the model would correspond to a nonlinear model with latent variables in the hidden layer. As already mentioned, we have considered such a nonlinear hierarchical model in Valpola03ICA_Nonlin. Note that computation nodes as hidden nodes would result in multiple paths from the latent variables of the upper layer to the observations. This type of structure was used in Lappalainen00, and it has a quadratic computational complexity as opposed to linear one of the networks in Figure 6.