The same ordered display can be used for illustrating the clustering density in different regions of the data space. The density of the reference vectors of an organized map will reflect the density of the input samples [Kohonen, 1995c, Ritter, 1991]. In clustered areas the reference vectors will be close to each other, and in the empty space between the clusters they will be more sparse. Thus, the cluster structure in the data set can be brought visible by displaying the distances between reference vectors of neighboring units [Kraaijveld et al., 1992, Kraaijveld et al., 1995, Ultsch, 1993b, Ultsch and Siemon, 1990].
The cluster display may be constructed as follows [Iivarinen et al., 1994]. The distance between each pair of reference vectors is computed and scaled so that the distances fit between a given minimum and maximum value, after optionally removing outliers. On the map display each scaled distance value determines the gray level or color of the point that is in the middle of the corresponding map units. The gray level values in the points corresponding to the map units themselves are set to the average of some of the nearest distance values (on a hexagonal grid, e.g., to the average of three of the six distances toward the lower-right corner). After these values have been set up, they can be visualized as such on the display, or smoothed spatially.
The resulting cluster diagram is very general in the sense that nothing needs to be assumed about the shapes of the clusters. Most of the clustering algorithms prefer clusters of certain shapes [Jain and Dubes, 1988].
A demonstration of a display constructed using SOM is presented in Figure 5.
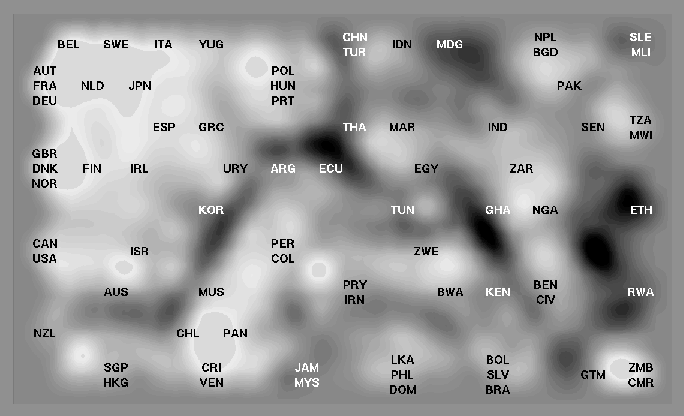
Figure: A map display constructed using the SOM algorithm. The
overall order of the countries seems to correspond fairly closely to
the Sammon's mapping of the same data set
(Fig. 4). The most prominent clustering
structures are also visible in both displays. Details on how the map
was constructed are presented in
Publication 2. The size of the map was 13
by 9 units.