Recall factor analysis described in Section 3.1.3, in which the conditional density in Equation (3.14) is restricted to be linear. In nonlinear FA, the generative mapping from factors (or latent variables or sources) to data is no longer restricted to be linear. The general form of the model is
 are observations
at time
are observations
at time  ,
,
 are the sources, and
are the sources, and
 are noise.
The function
are noise.
The function
 is a mapping from source
space to observation space parametrised by
is a mapping from source
space to observation space parametrised by
 .
.
Lappalainen and Honkela (2000) use a multi-layer perceptron (MLP)
network (see Haykin, 1999) with tanh-nonlinearities to model the mapping  :
:
 nonlinearity operates on each component of the input vector separately.
The mapping is thus parameterised by the matrices
nonlinearity operates on each component of the input vector separately.
The mapping is thus parameterised by the matrices  and
and  and bias vectors
and bias vectors  and
and  . MLP networks
are well suited for nonlinear FA. First, they are universal
function approximators (see Hornik et al., 1989, for proof) which means that any type of nonlinearity can
be modelled by them in principle. Second, it is easy to model smooth,
nearly linear mappings with them. This makes it possible to learn
high dimensional nonlinear representations in practice.
. MLP networks
are well suited for nonlinear FA. First, they are universal
function approximators (see Hornik et al., 1989, for proof) which means that any type of nonlinearity can
be modelled by them in principle. Second, it is easy to model smooth,
nearly linear mappings with them. This makes it possible to learn
high dimensional nonlinear representations in practice.
The traditional use of MLP networks differs a lot from the use in
nonlinear FA. Traditionally MLP networks are used in a supervised
manner, mapping known inputs
 to desired outputs
to desired outputs
 . During training of the network, both
and
are observed, whereas in nonlinear FA,
is always latent. The
traditional learning problem is much easier and can be reasonably
solved by using just point estimates.
. During training of the network, both
and
are observed, whereas in nonlinear FA,
is always latent. The
traditional learning problem is much easier and can be reasonably
solved by using just point estimates.
The used posterior approximation is a fully factorial Gaussian:
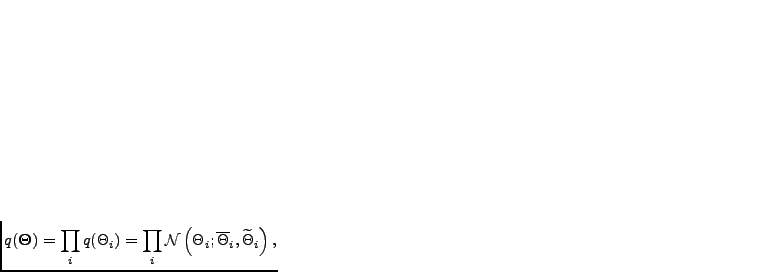 |
(4.8) |
 include the factors
include the factors
 , the
matrices
, the
matrices
 and
and
 , and other parameters. Thus for
each unknown variable
, and other parameters. Thus for
each unknown variable  , there are two parameters, the
posterior mean
, there are two parameters, the
posterior mean
 and the posterior variance
and the posterior variance
 . The
distribution that propagates through the nonlinear mapping
. The
distribution that propagates through the nonlinear mapping
 has
to be approximated. Honkela and Valpola (2005) suggest to do this by
linearising the tanh-nonlinearities using a Gauss-Hermite quadrature.
This works better than a Taylor approximation or
using a Gauss-Hermite quadrature on the whole mapping
.
has
to be approximated. Honkela and Valpola (2005) suggest to do this by
linearising the tanh-nonlinearities using a Gauss-Hermite quadrature.
This works better than a Taylor approximation or
using a Gauss-Hermite quadrature on the whole mapping
.
Using linear independent component analysis (ICA, see Section 3.1.4)
on sources
found by nonlinear factor analysis is a solution
to the nonlinear ICA problem, that is, finding independent components
that have been nonlinearly mixed to form the observations. A variety
of approaches for nonlinear ICA are reviewed by Jutten and Karhunen (2004).
Often, a special case known as post-nonlinear ICA is considered. In
post-nonlinear ICA, the sources are linearly mixed with the mapping
followed by component-wise nonlinear functions:
 again operates on each element
of its argument vector separately.
Ilin and Honkela (2004) consider post-nonlinear ICA by variational Bayesian
learning.
again operates on each element
of its argument vector separately.
Ilin and Honkela (2004) consider post-nonlinear ICA by variational Bayesian
learning.


