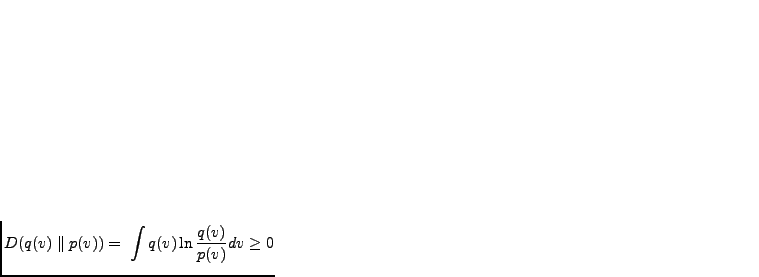Variational Bayesian (VB) learning
(MacKay, 2003,1995a; Jordan et al., 1999; Barber and Bishop, 1998; Hinton and van Camp, 1993; Lappalainen and Honkela, 2000; Lappalainen and Miskin, 2000)
is a fairly recently introduced (Hinton and van Camp, 1993; Wallace, 1990)
approximate fully Bayesian method,
which has become popular because of its good properties. Its key idea is
to approximate the exact posterior distribution
 by
another distribution
by
another distribution
 that is computationally
easier to handle.
that is computationally
easier to handle.
Typically, the misfit of the approximation is
measured by the Kullback-Leibler (KL) divergence
between two probability distributions  and
and  . The KL
divergence is defined by
. The KL
divergence is defined by
and . Its minimum value 0 is achieved when the
densities and are the same.
The VB method works by iteratively minimising the misfit
between the actual posterior pdf and its parametric approximation
using the KL divergence. Note that VB learning defines the goal and a
performance measure, but leaves the actual algorithm open.
The approximating distribution
is usually chosen to
be a product of several independent distributions, one for each parameter
or a set of similar parameters.
Even a crude approximation of a diagonal multivariate Gaussian density is adequate for
finding the region where the mass of the actual posterior density is
concentrated. The mean values of the Gaussian approximation provide
reasonably good point estimates of the unknown parameters, and the respective
variances measure the reliability of these estimates.
An example is given in Figure 2.1.
A main motivation of using VB is that it avoids overfitting which would be a difficult problem if ML or MAP estimates were used (see Section 2.5). VB method allows one to select a model having appropriate complexity, making often possible to infer the correct number of sources or latent variables.
Variational Bayes is closely related to information theoretic approaches which minimise the description length of the data, because the description length is defined to be the negative logarithm of the probability. Minimal description length thus means maximal probability. The information theoretic view provides insights to many aspects of learning and helps explain several common problems (Hinton and van Camp, 1993; Honkela and Valpola, 2004).