Taking into account causal relations of the environment usually
results in simpler and computationally efficient models. Take for
example a situation where A and B are known to affect C and D,
but the effect is causally mediated through E. If E summarises
all the knowledge that A and B have about C and D, then Cand D are conditionally independent of A and B given E.
Mathematically this means that
| (23) |
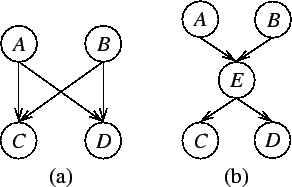 |
In general, a model with more variables but with simpler dependences is computationally more efficient. Introducing mediating variable Esimplifies the dependences because either only one variable affects two others, as in P(CD | Ei), or two variables affect one, as in P(Ei | AB). This strategy is a second nature to human beings who constantly try to organise the world by splitting complex dependences into simpler ones by introducing hidden, mediating variables, and therefore it is also usually easy to construct models using the same design principle. The mediating variables are not directly observable but can only be inferred from the dependence structure of the observations. These variables are therefore often called hidden or latent variables [25].
From a computational point of view, the efficiency is caused by the fact that the posterior probability of the unknown variables will be a product of many simple terms. Taking the logarithm will then split the product into a sum of many simple terms. Most methods for approximating the posterior probabilities can make use of this property, including the ML and MAP estimators, the EM algorithm, Laplace's method, ensemble learning and many versions of stochastic sampling.