Almost all the distributions appearing in our model are assumed to be
Gaussians, and consequently almost all the terms appearing in the cost
function are expectations of logarithms of Gaussian distributions. We
shall use the second layer biases
a as an example. For each
element ai, there is one term in
![]() and
and
![]() ,
namely the terms q(ai) and
p(ai | ma, va).
The cost function therefore includes terms
,
namely the terms q(ai) and
p(ai | ma, va).
The cost function therefore includes terms
![]() and
and
![]() .
In the first expectation the terms q(ai)only depends on ai which means that we can integrate over the other
variables and we have
.
In the first expectation the terms q(ai)only depends on ai which means that we can integrate over the other
variables and we have
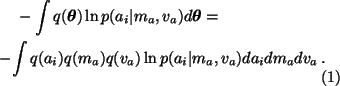
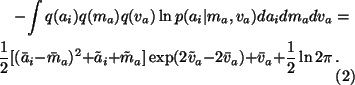
The following terms are the only ones whose expectations in
(16) give different results than (19) or
(20):
q(Mi(t), si(t)),
p(Mi(t) | ci),
p(si(t) | Mi(t), msi, vsi) and
![]() .
.
The index Mi(t) is discrete and therefore we have a summation
instead of integration in the cost function. Let us denote
![]() and denote the mean and variance of
the Gaussian
q(si(t) | Mi(t) = l) by
and denote the mean and variance of
the Gaussian
q(si(t) | Mi(t) = l) by
![]() and
and
![]() .
Then the expectations of
.
Then the expectations of
![]() in
(16) are given by
in
(16) are given by
![\begin{multline}\sum_l \int q(\boldsymbol{\theta}) \ln q(M_i(t) = l, s_i(t))
d\...
...dot{s}_{il}(t) - \frac{1}{2} \ln 2 \pi e
\tilde{s}_{il}(t)] \, .
\end{multline}](img49.gif)
For the expectation of
![]() we shall first
evaluate the following integral:
we shall first
evaluate the following integral:
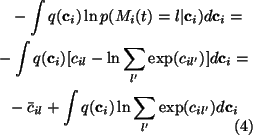
The resulting integral can be approximated by applying a second order
Taylor's series expansion of
![]() with respect
to cil' around the posterior mean
with respect
to cil' around the posterior mean
![]() .
This yields
the following approximation for the integral:
.
This yields
the following approximation for the integral:
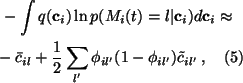
where
![]() .
Now we see that the expectation of
.
Now we see that the expectation of
![]() is
is
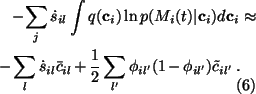
Since both
q(si(t) | Mi(t)) and
p(si(t) | Mi(t), msi,
vsi) are Gaussian, the terms
![]() have expectations which are similar to
(20):
have expectations which are similar to
(20):
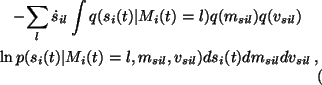
which equals to the sum of terms
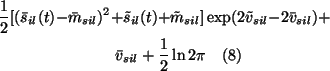
weighted by
![]() .
.
The observations xk(t) are known -- unless there are missing
values -- which means that there are no terms of the form
![]() .
The expectations of
.
The expectations of
![]() are
the most difficult terms in the cost function. If the posterior mean
and variance of the function
fk(s(t)) are known -- let us
denote them by
are
the most difficult terms in the cost function. If the posterior mean
and variance of the function
fk(s(t)) are known -- let us
denote them by
![]() and
and
![]() for short -- then the
expectation has a form similar to (20):
for short -- then the
expectation has a form similar to (20):
![\begin{multline}\frac{1}{2}[(x_k(t) - \bar{f}_k(t))^2 + \tilde{f}_k(t)]
\exp(2\...
... - 2\bar{v}_{nk}) + \\ \bar{v}_{nk} + \frac{1}{2} \ln 2
\pi \, .
\end{multline}](img65.gif)