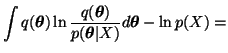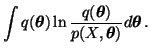The goal is to estimate the posterior pdf of all the unknown variables of the model. This is done by ensemble learning which amounts to fitting a simple, parametric approximation to the actual posterior pdf [5]. The cost function C is the misfit between the approximation and the actual posterior and is measured by the Kullback-Leibler information which is sensitive to the probability mass of densities. This is the most important advantage over maximum a posteriori (MAP) estimation which is computationally less expensive but is sensitive to probability density, not mass. This is why MAP estimation suffers from overfitting, which would be a serious problem since there are so many estimated variables, while ensemble learning is able avoid it.
For the time being, let us denote the set of all observations vectors
x(t) by X and denote all the other parameters by a vector
![]() .
The actual posterior pdf is thus
.
The actual posterior pdf is thus
![]() .
The joint pdf
.
The joint pdf
![]() is obtained from the definition of the model in
(3)-(14) and p(X) is a
normalising factor which does not depend on the unknown variables.
is obtained from the definition of the model in
(3)-(14) and p(X) is a
normalising factor which does not depend on the unknown variables.
Let us denote the approximation of the posterior pdf by
![]() .
In order for the cost function to be computable
in practice, a simple factorial form needs to be chosen for the
approximation
.
In order for the cost function to be computable
in practice, a simple factorial form needs to be chosen for the
approximation
![]() .
The maximally factorial form would
be
.
The maximally factorial form would
be
| (15) |
The assumption of factorial
![]() is equivalent to
assuming the unknown variables independent given the observations.
This is not true, of course, but we have to make this approximation in
order to obtain a practical algorithm. The only exception to this
maximally factorial form is that the index Mi(t) of the Gaussian
and the corresponding source si(t) are allowed to have posterior
dependency, that is, the terms
q(Mi(t), si(t)) are not further
factorised.
is equivalent to
assuming the unknown variables independent given the observations.
This is not true, of course, but we have to make this approximation in
order to obtain a practical algorithm. The only exception to this
maximally factorial form is that the index Mi(t) of the Gaussian
and the corresponding source si(t) are allowed to have posterior
dependency, that is, the terms
q(Mi(t), si(t)) are not further
factorised.
The approximation
![]() should be chosen so that it fits the
actual posterior as closely as possible. This is accomplished by
choosing
should be chosen so that it fits the
actual posterior as closely as possible. This is accomplished by
choosing
![]() to be Gaussian for other variables than sources
and for sources choosing
q(Mi(t), si(t)) = Q(Mi(t)) q(si(t) |
Mi(t)), where
q(si(t) | Mi(t)) is Gaussian.
to be Gaussian for other variables than sources
and for sources choosing
q(Mi(t), si(t)) = Q(Mi(t)) q(si(t) |
Mi(t)), where
q(si(t) | Mi(t)) is Gaussian.
Let us denote the mean and variance of
![]() by
by
![]() and
and
![]() ,
respectively. The result of
learning is then an estimate of
,
respectively. The result of
learning is then an estimate of
![]() and
and
![]() which tell the posterior mean and variance of
all the unknown variables.
which tell the posterior mean and variance of
all the unknown variables.
The term p(X) is constant with respect to the unknown parameters.
Instead of the pure Kullback-Leibler information
![]() it is therefore possible to use the
following cost function:
it is therefore possible to use the
following cost function:
Due to simple factorial forms of
![]() and
and
![]() the cost function splits into simple terms which are
easy to compute. Consequently, it is also easy to differentiate the
cost function with respect to
the cost function splits into simple terms which are
easy to compute. Consequently, it is also easy to differentiate the
cost function with respect to
![]() and
and
![]() and use the derivatives for constructing the
learning algorithm.
and use the derivatives for constructing the
learning algorithm.