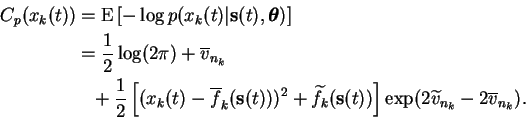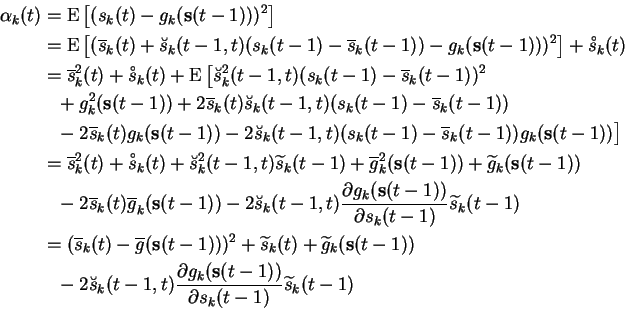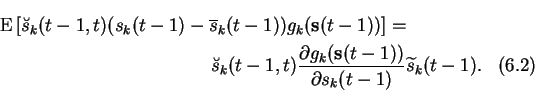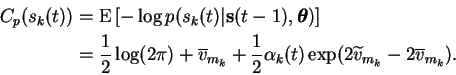As before, the general cost function of ensemble learning, as given in Equation (3.11), is
In the NSSM, all the probability distributions involved are Gaussian
so most of the terms will resemble the corresponding ones of the
CDHMM. For the parameters
![]() ,
,
The term
![]() is a little more complicated:
is a little more complicated:
The first term reduces to Equation (6.26) but the second term is a little different:
The expectation of
![]() has been evaluated in
Equation (6.5), so the only remaining terms are
has been evaluated in
Equation (6.5), so the only remaining terms are
![]() and
and
![]() . They both involve the nonlinear mappings
. They both involve the nonlinear mappings
![]() and
and
![]() , so they cannot be evaluated exactly.
, so they cannot be evaluated exactly.
The formulas allowing to approximate the distribution of the outputs
of an MLP network
![]() are presented in
Appendix B. As a result we get the posterior
mean of the outputs
are presented in
Appendix B. As a result we get the posterior
mean of the outputs
![]() and the posterior variance,
decomposed as
and the posterior variance,
decomposed as
With these results the remaining terms of the cost function are relatively easy to evaluate. The likelihood term is a standard Gaussian and yields
The source term is more difficult. The problematic expectation is
Using Equation (6.31), the remaining term of the cost function can be written as
![\begin{displaymath}\begin{split}C(\boldsymbol{S}, \boldsymbol{\theta}) &= C_q + ...
...mbol{\theta}) - \log p(\boldsymbol{\theta}) \right] \end{split}\end{displaymath}](img427.gif)
![$\displaystyle C_q(\theta_i) = \operatorname{E}\left[ \log q(\theta_i) \right] = -\frac{1}{2} (1 + \log (2 \pi \widetilde{\theta_i})).$](img429.gif)
![\begin{displaymath}\begin{split}C_q(\boldsymbol{S}) &= \operatorname{E}\left[ \l...
...\left[ \log q(s_k(t+1) \vert s_k(t)) \right] \Big). \end{split}\end{displaymath}](img431.gif)
![\begin{multline}
E_{q(s_k(t), s_k(t+1))} \left[ \log q(s_k(t+1) \vert s_k(t)) \...
...5ex][0ex]{\ensuremath{\scriptscriptstyle \,\circ}}}{s}}_k(t+1))).
\end{multline}](img432.gif)
![$\displaystyle \widetilde{f}_k(\mathbf{s}) \approx \widetilde{f}_k^*(\mathbf{s})...
...\widetilde{s}_j \left[ \frac{\partial f_k(\mathbf{s})}{\partial s_j} \right]^2.$](img437.gif)