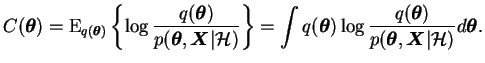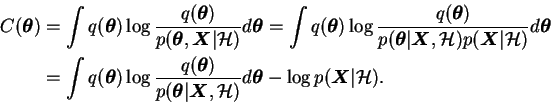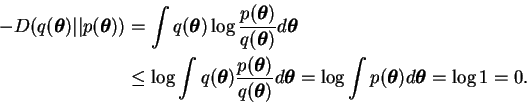Ensemble learning is a relatively new concept suggested by Hinton and van Camp in 1993 [23]. It allows approximating the true posterior distribution with a tractable approximation and fitting it to the actual probability mass with no intermediate point estimates.
The posterior distribution of the model parameters
![]() ,
,
![]() , is approximated with another distribution or
approximating ensemble
, is approximated with another distribution or
approximating ensemble
![]() . The objective function chosen
to measure the quality of the approximation is essentially the same
cost function as the one for EM algorithm in
Equation (3.10) [38]
. The objective function chosen
to measure the quality of the approximation is essentially the same
cost function as the one for EM algorithm in
Equation (3.10) [38]
Ensemble learning is based on finding an optimal function to approximate another function. Such optimisation methods are called variational methods and therefore ensemble learning is sometimes also called variational learning [30].
A closer look at the cost function
![]() shows that it can be
represented as a sum of two simple terms
shows that it can be
represented as a sum of two simple terms
The first term in Equation (3.12) is the
Kullback-Leibler divergence between the approximate posterior
![]() and the true posterior
and the true posterior
![]() . A simple
application of Jensen's inequality [52] shows that the
Kullback-Leibler divergence
. A simple
application of Jensen's inequality [52] shows that the
Kullback-Leibler divergence ![]() between two distributions
between two distributions
![]() and
and
![]() is always nonnegative:
is always nonnegative:
The Kullback-Leibler divergence is not symmetric and it does not obey the triangle inequality, so it is not a metric. Nevertheless it can be considered a kind of a distance measure between probability distributions [12].
Using the inequality in Equation (3.13) we find that the
cost function
![]() is bounded from below by the negative
logarithm of the evidence
is bounded from below by the negative
logarithm of the evidence
Looking at this the other way round, the cost function gives a lower bound on the model evidence with
An important feature for practical use of ensemble learning is that the cost function and its derivatives with respect to the parameters of the approximating distribution can be easily evaluated for many models. Hinton and van Camp [23] used a separable Gaussian approximating distribution for a single hidden layer MLP network. After that many authors have used the method for different applications.