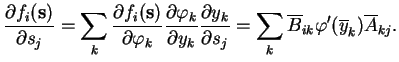In this appendix, it is shown how to evaluate the distribution of the
outputs of an MLP network
![]() , assuming the inputs
, assuming the inputs
![]() and
all the network weights are independent and Gaussian. These equations
are needed in evaluating the ensemble learning cost function of the
Bayesian NSSM in Section 6.2.
and
all the network weights are independent and Gaussian. These equations
are needed in evaluating the ensemble learning cost function of the
Bayesian NSSM in Section 6.2.
The exact model for our single-hidden-layer MLP network
![]() is
is
| (B.2) | ||
| (B.3) | ||
| (B.4) | ||
| (B.5) | ||
| (B.6) |
The computations in the first layer of the network can be
written as
![]() . Since all the parameters
involved are independent, the mean and the variance of
. Since all the parameters
involved are independent, the mean and the variance of ![]() are
are
The nonlinear activation function is handled with a truncated Taylor
series approximation about the mean
![]() of the inputs. Using a
second order approximation for the mean and first order for the
variance yields
of the inputs. Using a
second order approximation for the mean and first order for the
variance yields
The computations of the output layer are given by
![]() . This may look the same as the one for the first
layer, but there is the big difference that the
. This may look the same as the one for the first
layer, but there is the big difference that the ![]() are no longer
independent. Their dependence does not, however, affect the
evaluation of the mean of the outputs, which is
are no longer
independent. Their dependence does not, however, affect the
evaluation of the mean of the outputs, which is
The dependence between ![]() arises from the fact that each
arises from the fact that each ![]() may
potentially affect all of them. Hence, the variances of
may
potentially affect all of them. Hence, the variances of ![]() would
be taken into the account incorrectly if
would
be taken into the account incorrectly if ![]() were assumed
independent.
were assumed
independent.
Two possibly interfering paths can be seen in
Figure B.1. Let us assume that the net weight of
the left path is ![]() and the weight of the right path
and the weight of the right path ![]() , so that
the two paths cancel each other out. If, however, the outputs of the
hidden layer are incorrectly assumed to be independent, the estimated
variance of the output will be greater than zero. The same effect can
also happen the other way round when constructive inference of the two
paths leads to underestimated output variance.
, so that
the two paths cancel each other out. If, however, the outputs of the
hidden layer are incorrectly assumed to be independent, the estimated
variance of the output will be greater than zero. The same effect can
also happen the other way round when constructive inference of the two
paths leads to underestimated output variance.
The effects of different components of the inputs on the outputs can
be measured using the Jacobian matrix
![]() of the mapping
of the mapping
![]() with elements
with elements
![]() . This leads to the approximation for the
output variance
. This leads to the approximation for the
output variance
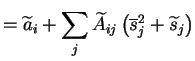 |
(B.14) | |
| (B.15) |
The needed partial derivatives can be evaluated efficiently at the mean of the inputs with the chain rule
![\includegraphics[width=.4\textwidth]{pics/multipath}](img532.gif)
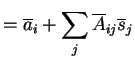
![$\displaystyle = \widetilde{a}_i + \sum_j \left[ \overline{A}_{ij}^2 \widetilde{...
...+ \widetilde{A}_{ij} \left( \overline{s}_j^2 + \widetilde{s}_j \right) \right].$](img538.gif)
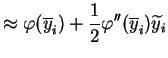
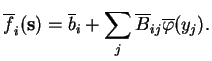
![\begin{displaymath}\begin{split}\widetilde{f}_i(\mathbf{s}) \approx &\sum_j \lef...
...}^2(y_j) + \widetilde{\varphi}(y_j) \right) \right] \end{split}\end{displaymath}](img553.gif)