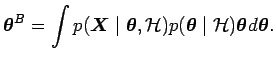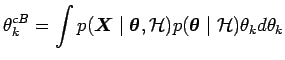This section describes how a LOHMM can be learned from data using the Bayesian approach.
Let us first separate a LOHMM into its parameters
![]() (the
probabilities) and the structure
(the
probabilities) and the structure
![]() (the rest). Let us also assume
a prior which generates a structure
(the rest). Let us also assume
a prior which generates a structure
![]() with probability
with probability
![]() and parameters for it with probability density
and parameters for it with probability density
![]() . Learning a
single LOHMM
. Learning a
single LOHMM
![]() from data
from data
![]() corresponds to finding a good
representative of the posterior probability mass:
corresponds to finding a good
representative of the posterior probability mass:
Instead of finding just one LOHMM, one could use an ensemble of them represented with a set of sampled points [5] or a distribution with a simple form [7]. This is out of scope of this paper.
Finding a good representative structure
![]() involves a combinatorial
search in the structure space, where for each structure candidate, the
parameters
involves a combinatorial
search in the structure space, where for each structure candidate, the
parameters
![]() need to be estimated. One could first try structures
that resemble good candidates by using inductive logic programming
[12] techniques. Also, the information from
other structures can be used to guide the parameter estimation. This
is further research.
need to be estimated. One could first try structures
that resemble good candidates by using inductive logic programming
[12] techniques. Also, the information from
other structures can be used to guide the parameter estimation. This
is further research.
The representative parameters
![]() for a given structure
for a given structure
![]() can be
found using estimation. There are two commonly used estimators: the
maximum a posteriori (map) estimate
can be
found using estimation. There are two commonly used estimators: the
maximum a posteriori (map) estimate
![]() and the Bayes
estimate
and the Bayes
estimate
![]() . They are defined as
. They are defined as
One can also use the Bayes estimator componentwise (cB). Each
component ![]() is estimated by
is estimated by