


Next: Gaussian distribution
Up: Natural gradient learning for
Previous: Natural gradient learning for
When applying natural gradients to approximate inference, the geometry
is defined by the approximation
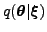 and not the full
model
and not the full
model
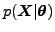 as usually. If the approximation
is chosen such that disjoint groups of variables are independent, that is,
as usually. If the approximation
is chosen such that disjoint groups of variables are independent, that is,
 |
(5) |
the computation of the natural gradient is simplified as the Fisher
information matrix becomes block-diagonal. The required matrix
inversion can be performed very efficiently because
 |
(6) |
The dimensionality of the problem space is often so high that
inverting the full matrix would not be feasible.
Figure 1:
The absolute change in the mean of the Gaussian in figures (a)
and (b) and the absolute change in the variance of the Gaussian in
figures (c) and (d) is the same.
However, the relative effect is much larger when the variance is small
as in figures (a) and (c) compared to the case when the variance is
high as in figures (b) and (d) [12].
![\begin{figure}\centering
%\begin{tabular}{cc}
\subfigure[]{
\epsfig{file=meanc...
...t: The contours show an objective function of the mean (horizontal
\end{figure}](img31.png) |
Next: Gaussian distribution
Up: Natural gradient learning for
Previous: Natural gradient learning for
Tapani Raiko
2007-09-11