


Next: Hierarchical Prior for the
Up: Formulation of the Model
Previous: Main Structure
The priors for weights
A and
B have zero mean and
common variance to each dimension k, which corresponds to incoming
weights of a source si,k:
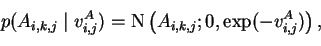 |
(5.7) |
where Ai,k,j is the element of
Ai that connects
si+1,j to si,k. Parameters for
B are similar and
are not shown here. The variance parameter has the prior parameters
that are common to dimensions j
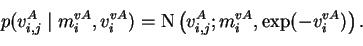 |
(5.8) |
The hyperparameters
mivA and
vivA have priors of the form
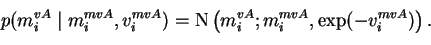 |
(5.9) |
The priors for these priors
mimvA,
mivvA,
vimvA and
vivvA of the hyperparameters are very flat
and defined as constants in the model structure. They are of the form
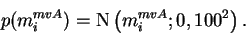 |
(5.10) |
Tapani Raiko
2001-12-10