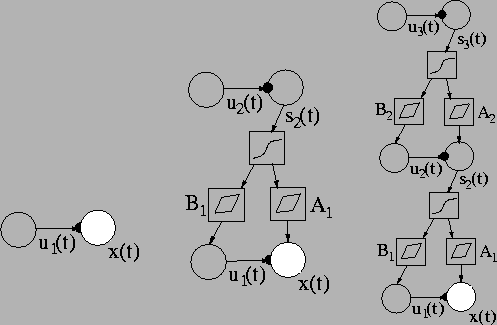
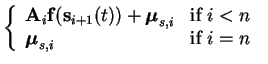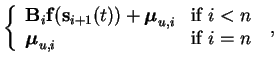Figure ![[*]](cross_ref_motif.gif) shows the structure for
hierarchical nonlinear factor analysis with variance modelling
(HNFA+VM). It utilises variance neurons and nonlinearities in
building a hierarchical model for both the means and variances.
Without the variance neurons the model would correspond to a
multi-layer perceptron with latent variables as hidden neurons. Note
that computational nodes as hidden neurons would result in multiple
paths from upper layer latent variables to the observations. This
type of structure was used in [43] and it has a quadratic
as opposed to linear computational complexity.
shows the structure for
hierarchical nonlinear factor analysis with variance modelling
(HNFA+VM). It utilises variance neurons and nonlinearities in
building a hierarchical model for both the means and variances.
Without the variance neurons the model would correspond to a
multi-layer perceptron with latent variables as hidden neurons. Note
that computational nodes as hidden neurons would result in multiple
paths from upper layer latent variables to the observations. This
type of structure was used in [43] and it has a quadratic
as opposed to linear computational complexity.
 |
The exact formulation of HNFA+VM is as follows. The observed
data matrix
X has T observations of n1 dimensions.
X is named
s1(t) for notational simplicity
On each layer i, there are ni sources assembled to a vector
si. The dimensions of the vectors are marked with
si,k,
![]() .
The sources on upper layers i>1are mapped through a Gaussian nonlinearity
.
The sources on upper layers i>1are mapped through a Gaussian nonlinearity
The connection downwards after the nonlinearity is done using the
affine mappings
Each source si,k has a corresponding variance neurons
ui,k. The signals
mis(t) and
miu(t)are used as prior means for them
![$\displaystyle \left[ \begin{array}{c}
\exp(-s_{i,1}(t)^2) \\
\exp(-s_{i,2}(t)^2) \\
\vdots \\
\exp(-s_{i,n_i}(t)^2) \end{array} \right].$](img191.gif)