In many of the described models, the observations are reconstructed as a weighted sum of model vectors. In vector quantisation [1], only one of the model vectors is active at a time, which means that all but one of the weights are zero. This is called local coding. There has to be lots of model vectors to get a reasonable accuracy. In basic factor analysis, the factors have a Gaussian distribution and therefore most of them can be active or nonzero at a time. This is called global coding. Sparse coding fits in between these two extremes; Each observation is reconstructed using just a few active units out of a larger collection. Biological evidence suggests [14] that the human brain uses sparse coding. It is said to have benefits like good representational capacity, fast learning, good generalisation and tolerance to faults and damage.
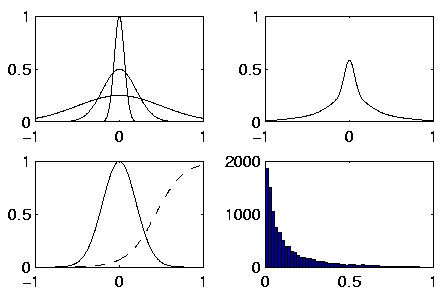
Sparsity implies that the distribution of a source has a high peak,
but the variation can still be broad. The peak corresponds to the
inactivity and therefore it is typically at zero. Kurtosis is one
measure of peakedness. It is defined as
Most of the probability density functions in this thesis are
Gaussian. However, by varying the variance or using a nonlinearity
with a flat part as in Figure ![[*]](cross_ref_motif.gif) , a peaked distribution
can be obtained. Beale showed [4] that by varying the
variance of a symmetrical distribution, the kurtosis always increases.
Because of the biological and experimental motivation to use sparse
coding, it is made sure in Chapter that the model is
rich enough to use it.
, a peaked distribution
can be obtained. Beale showed [4] that by varying the
variance of a symmetrical distribution, the kurtosis always increases.
Because of the biological and experimental motivation to use sparse
coding, it is made sure in Chapter that the model is
rich enough to use it.
 |