In some of the described models the data is thought to have been
generated from original factors or source signals through a linear or
nonlinear mapping. The mapping and the sources can be adjusted to
match the data better by propagating the reconstruction error of the
data upwards in Figure ![[*]](cross_ref_motif.gif) . If the
nonlinearity is strong, but the mapping is not yet very meaningful, it
is hard to determine how the adjustments should be made.
. If the
nonlinearity is strong, but the mapping is not yet very meaningful, it
is hard to determine how the adjustments should be made.
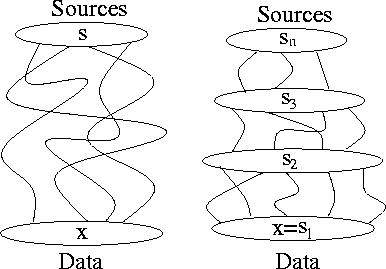 |
In hierarchical nonlinear factor analysis (HNFA), the hidden units or calculating units of an MLP-like network in NFA are replaced by latent variables. Even if the mapping between two adjacent layers is only slightly nonlinear, the total mapping through all the layers can be strongly nonlinear. The learning or the adjustments can be done layer by layer. One part can learn even if the total mapping is not yet very meaningful.
Hierarchical models for parameters are widely used in modern Bayesian data analysis [18,59]. That is, observations are modelled conditionally on some parameters which themselves are modelled by hyperparameters. In HNFA, however, the hierarchy applies also to the time dependent sources and not only to the parameters.
HNFA belongs to Bayesian networks [33]. In Bayesian networks, the variables are connected as a directed acyclic graph. Some of the variables are observed and others are latent or hidden. Variables can be continuous valued or discrete.
Neal developed the logistic belief net [51], which is like HNFA with binary variables. He replaced symmetric connections of Boltzmann machine with directed connections that form an acyclic graph. After that, the probabilistic calculations become easy.
Frey and Hinton [15] constructed a nonlinear Gaussian belief network for tasks such as stereo vision and speech recognition. Gaussian latent variables were passed through linear, binary, rectified and sigmoidal functions to get nonlinear units. Maximum likelihood and Gibbs sampling were compared as learning methods.
Murphy [50] used a variational approximation to the logistic function to perform approximate inference in Bayesian networks containing discrete nodes with continuous parents. The experiments showed that the variational approximation is much faster than sampling, but comparable in accuracy.