In the first set of experiments we compared the computational
performance of different algorithms on PCA with missing values. The
root mean square (rms) error is measured on the training data,
![]() .
All experiments were run on a dual cpu AMD Opteron SE 2220 using
Matlab.
.
All experiments were run on a dual cpu AMD Opteron SE 2220 using
Matlab.
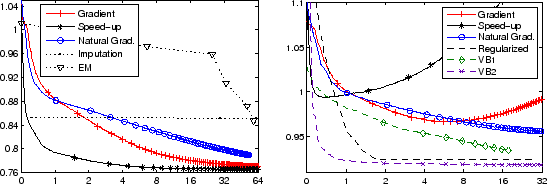
First, we tested the imputation algorithm. The first iteration where the
missing values are replaced with zeros, was completed in 17 minutes
and led to
![]() .
This iteration was still tolerably fast because the complete
data matrix was sparse. After that, it takes about 30 hours per iteration.
After three iterations,
.
This iteration was still tolerably fast because the complete
data matrix was sparse. After that, it takes about 30 hours per iteration.
After three iterations, ![]() was still 0.8513.
was still 0.8513.
Using the EM algorithm by [11], the E-step (updating
![]() )
takes 7 hours and the M-step (updating
)
takes 7 hours and the M-step (updating
![]() ) takes 18 hours. (There
is some room for optimization since we used a straightforward Matlab
implementation.) Each iteration gives a much larger improvement
compared to the imputation algorithm, but starting from a random
initialization, EM could not reach a good solution in reasonable time.
) takes 18 hours. (There
is some room for optimization since we used a straightforward Matlab
implementation.) Each iteration gives a much larger improvement
compared to the imputation algorithm, but starting from a random
initialization, EM could not reach a good solution in reasonable time.
We also tested the subspace learning algorithm described in
Section 3 with and without the proposed speed-up. Each run of the
algorithm with different values of the speed-up parameter ![]() was
initialized in the same starting point (generated randomly from a
normal distribution). The learning rate
was
initialized in the same starting point (generated randomly from a
normal distribution). The learning rate ![]() was adapted such that
if an update decreased the cost function,
was adapted such that
if an update decreased the cost function, ![]() was multiplied by
1.1. Each time an update would increase the cost, the update was
canceled and
was multiplied by
1.1. Each time an update would increase the cost, the update was
canceled and ![]() was divided by 2. Figure
1 (left) shows the learning curves for basic
gradient descent, natural gradient descent, and the proposed speed-up
with the best found parameter value
was divided by 2. Figure
1 (left) shows the learning curves for basic
gradient descent, natural gradient descent, and the proposed speed-up
with the best found parameter value
![]() . The proposed
speed-up gave about a tenfold speed-up compared to the gradient
descent algorithm even if each iteration took
longer. Natural gradient was slower than the basic gradient.
Table 1 gives a summary of the computational complexities.
. The proposed
speed-up gave about a tenfold speed-up compared to the gradient
descent algorithm even if each iteration took
longer. Natural gradient was slower than the basic gradient.
Table 1 gives a summary of the computational complexities.
 |