A more simple case is when the maximum likelihood estimate is used for some on the parameters. This can be done by the EM-algorithm where the computation alternates between computing the posterior distribution of one set of variables given the current point estimate of the other set of variables (E-step) and then using the posterior distribution of the first set of variables to compute a new maximum likelihood estimate of the second set of variables (M-step).
When EM-algorithm is applied to ICA, usually the full posterior
distribution is computed for sources and the maximum likelihood
estimate is used for the rest of the parameters. This means that in
the E-step we need to compute the posterior distribution of the
sources s given x,A and the noise
covariance
![]()
Using the matrix notation for the finite number of samples, i.e. X and S, we can
write the M-step (see [9]) re-estimation for the mixing matrix as
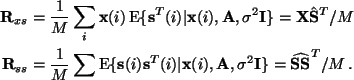
We will consider here the case where ![]() is small. If we
further assume that the mixtures are prewhitened, we can constrain the
mixing matrix to be orthogonal and we can assume that the sources have
unit variance. This makes
Rss a unit matrix.
is small. If we
further assume that the mixtures are prewhitened, we can constrain the
mixing matrix to be orthogonal and we can assume that the sources have
unit variance. This makes
Rss a unit matrix.
In [2] the EM-algorithm is derived as a low-noise approximation for the case
of square mixing matrix A. First, the posterior mean
![]() is obtained as
is obtained as
Substituting the above approximations we get
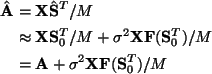
As the authors mention in [2], this approximation
leads to an EM-algorithm which converges slowly with low noise variance ![]() .
They also point out that there is no visible ``noise-correction''.
It is precisely this point that we will address in the next section.
.
They also point out that there is no visible ``noise-correction''.
It is precisely this point that we will address in the next section.