SELF-ORGANIZING MAPS IN
NATURAL LANGUAGE PROCESSING
by
of
Helsinki University of Technology
Neural Networks Research Centre
P.O. Box 2200
FIN-02015 HUT, FINLAND
as
in
Some pictures are also available.
Abstract
Kohonen's Self-Organizing Map (SOM) is one of the most popular artificial neural network algorithms. Word category maps are SOMs that have been organized according to word similarities, measured by the similarity of the short contexts of the words. Conceptually interrelated words tend to fall into the same or neighboring map nodes. Nodes may thus be viewed as word categories. Although no a priori information about classes is given, during the self-organizing process a model of the word classes emerges.
The central topic of the thesis is the use of the SOM in natural language processing. The approach based on the word category maps is compared with the methods that are widely used in artificial intelligence research. Modeling gradience, conceptual change, and subjectivity of natural language interpretation are considered. The main application area is information retrieval and textual data mining for which a specific SOM-based method called the WEBSOM has been developed. The WEBSOM method organizes a document collection on a map display that provides an overview of the collection and facilitates interactive browsing.
I wish to express my deepest gratitude to Academy Professor Teuvo Kohonen without whom this work would not have been possible. As the inventor of the Self-Organizing Map he has created this area, and as the leader of the Neural Networks Research Centre he has gathered a stimulating and effective environment. I wish to thank professor Kohonen for his most invaluable advice and fatherly personal encouragement. His support has covered an overwhelming expertise in the technical and methodological issues as well as in the philosophical underpinnings of the field. Without his efforts from the 1960's till these days the concentrated and well-equipped research would not have been possible.
As a member of the WEBSOM team I have received great help and support. Central parts of this work are based on this collaboration. Therefore, I wish to show my deepest gratitude to Dr.Tech. Samuel Kaski, Prof. Teuvo Kohonen, and Ms Krista Lagus. I also wish to thank former colleagues Dr.Tech. Ari M. Vepsäläinen and Mr. Ville Pulkki for their efforts, and all the current and former colleagues in the Neural Networks Research Centre and in the Laboratory for Information Processing Science of Helsinki University of Technology, in VTT Information Technology, in VTKK Tietopalvelu, in Kielikone project of Sitra foundation, and in the Department of Information Processing Science of University of Oulu.
I wish to thank the prereviewers Prof. Fred Karlsson and Prof. Pasi Koikkalainen for their invaluable and constructive comments on the work and suggestions for improvements.
I have received a lot of valuable help, advice and comments during the years of research work from many current and former supervisors and colleagues, collaborators, and academic friends. I wish to express my warmest thanks to Ms Riitta Alkula, Dr. Harri Arnola, Mr. Jukka Honkela, Ms Sanna Hätönen, Dr. Heikki Hyötyniemi, Dr. Mauri Kaipainen, Dr. Jari Kangas, Prof. Fred Karlsson, Ms Taru Kuhanen, Mr. Aarno Lehtola, Prof. Seppo Linnainmaa, Dr. Kirsti Lonka, Ms Sini Maury, Prof. Erkki Oja, Ms Eeva Palosuo, Dr. Inga-Britt Persson, Mr. Jarno Raukko, Mr. Timo Sampolahti, and Prof. Olli Simula. I hope that the inevitable omissions will be forgiven.
Last but not least, I would like to thank Dr. Kaarlo Jaakkola and Dr. Jari Ahlberg as well as Shiatsu specialist Raija Koivisto for their efforts in ensuring my health recovery without which I would not have been able to write this thesis.
The thesis is dedicated to my parents: Maila, who left this world too early, Kaisa and Unto; and to Kristiina and Johanna whose patience I gratefully acknowledge; and especially to Catherine who has given me her understanding support and the deepest motivation for the work in its last phases.
I hope that this work provides insight into how it is possible to learn
to understand, and, on the other hand, why it is not always easy to
understand, although the same words are used. As a more
straightforward consequence I also wish that the methodological results
support development of applications that help people to communicate
with each other efficiently by providing means for finding relevant
information, and, in the long run, help in preventing
unnecessary misunderstandings.
Helsinki, 2nd of December, 1997
Timo Honkela
The thesis consists of an introduction and the following publications:
In Publication 1, Kohonen's Self-Organizing Map (SOM) is used to model the impreciseness of natural language interpretation. The author designed the study and conducted the practical experiments related to the SOM. Ari M. Vepsäläinen provided his expertise of associative memories.
Publication 2 extends the principles presented in Publication 1 by introducing a model of a ``communicating agent'' that is based on the SOM. The basic idea is to provide a model of adaptation that leads to intersubjectivity in interpretation of natural language expressions and to coherence in communication.
Publication 3 deals with the analysis of contextual relations of words. The work was based on the principle of self-organizing semantic maps presented by Ritter and Kohonen in 1989 in Biological Cybernetics. In their article, artificially generated, syntactically correct and meaningful short phrases were used as the input to the SOM. For the publication, the method was refined and the input consisted of segments of text from a natural corpus. The author made the initial experiments, which then were continued by Ville Pulkki under the guidance of Prof. Teuvo Kohonen and the author. Ville Pulkki introduced the idea of using word-specific maps in the preprocessing, rather than calculating a single averaged context vector for each word in the vocabulary.
Studies on the WEBSOM full-text analysis method are described in Publications 4, 5, and 8. The basic system is presented in Publications 4 and 5. In the former, organization of the document collection was still supervised, i.e., the information of the group into which each document belonged was included in the input vector. This method was used in order to improve separation of the classes. Publication 5 presents a fully unsupervised method with improvements in the document encoding. The original idea of using a two-stage SOM architecture was due to the author. Samuel Kaski was the main originator of the idea of using table lookups for the efficient encoding of the documents and the subsequent convolution. The original document maps were limited to some 10 000 documents at maximum. To facilitate considerably larger maps for up to one million documents, Professor Kohonen later suggested some new methods for shortcut computation. Many ideas and details, as well as implementations and experiments were developed jointly in a team consisting of Samuel Kaski, Teuvo Kohonen, Krista Lagus, and myself. It is not possible to give the full account of all the contributions of the individual team members. However, in general, the first of author's main contributions were related to the word category maps. Publication 8 then analyses the field of information retrieval and data mining of text collections. The author's idea was to use a two-level SOM, called WEBSOM, as a tool for intelligent information retrieval. This author's contribution ensued from his rather long experience in natural language processing and information retrieval that guided the selection and handling of the main themes.
Publication 6 is a rather specific study of the word category maps aiming at methodological fine-tuning. The effects of the various parameter selections were tested by the author using a map comparison method presented by Samuel Kaski and Krista Lagus at the ICANN'96 conference.
Publication 7 presents how the word category maps can be used in natural language processing (NLP) applications. The main emphasis is on the WEBSOM method, and the concrete results presented in the publication are based on the close collaboration of the WEBSOM team. Publication 7 also discusses the nature of the found clusters and the general principles of using the SOM, e.g., in graded classification, following the argumentations set by Ritter and Kohonen in their article in the journal Biological Cybernetics in 1989. The author has introduced the concepts of ``emerging categories'' and ``adaptive prototypes'' related to the SOM that were first presented in the International Cognitive Linguistics Conference in Amsterdam, July, 1997, the papers of which have not been published yet.
In Publication 9 the introduction outlines some limits of the traditional symbolic approaches such as relying on fixed categorizations, problems related to handling language change, and, moreover, subjectivity and context-sensitivity of interpretation. One chapter summarizes the basic principles of using the SOM in natural language interpretation. Finally, the last chapter contains some epistemological considerations.
In summary, the author's main contribution was the idea of the two-level SOM architecture where the first map clusters the words statistically according to their context, and the second map utilizes the frequency histograms clustered by the first map. The linguistic interpretations are also mainly the author's contribution.
| AI | Artificial intelligence |
| ASSOM | Adaptive subspace self-organizing map |
| HTML | Hypertext markup language |
| IR | Information retrieval |
| KDD | Knowledge discovery in databases |
| MT | Machine translation |
| NLP | Natural language processing |
| RGB | Red-green-blue |
| SOM | Self-organizing map |
| SQL | Structured query language |
| WWW | World wide web |
| input vector (data item), kth input vector | |
| t | discrete-time index |
| N | number of input vectors |
| ith model vector | |
| hij | neighborhood kernel in the SOM algorithm |
![[*]](foot_motif.gif) ,
disambiguation,
syntactical analysis based on dependency
grammar (Lehtola and Valkonen, 1986,Valkonen et al., 1987),
semantical
analysis that used a set of tree transformation rules to transform the
dependency tree into a tree of predicate
structures (Lehtola and Honkela, 1988,Honkela, 1989),
and finally a two-stage database query formulation that first produced
a system-independent query
expression (Hyötyniemi and Lehtola, 1988),
and finally then formed the query (Hyötyniemi and Lehtola, 1991).
Special-purpose formalisms and metatools were developed during the project
(e.g., Lehtola88ismis,Lehtola88icsc).
The approach was mainly grounded on rule-based formalisms
that proved to be practical in the tasks of syntactic
analysis. A major problem arose in the semantical analysis.
Three key findings have been relevant as the initiating problems
that motivated the research reported in this thesis:
,
disambiguation,
syntactical analysis based on dependency
grammar (Lehtola and Valkonen, 1986,Valkonen et al., 1987),
semantical
analysis that used a set of tree transformation rules to transform the
dependency tree into a tree of predicate
structures (Lehtola and Honkela, 1988,Honkela, 1989),
and finally a two-stage database query formulation that first produced
a system-independent query
expression (Hyötyniemi and Lehtola, 1988),
and finally then formed the query (Hyötyniemi and Lehtola, 1991).
Special-purpose formalisms and metatools were developed during the project
(e.g., Lehtola88ismis,Lehtola88icsc).
The approach was mainly grounded on rule-based formalisms
that proved to be practical in the tasks of syntactic
analysis. A major problem arose in the semantical analysis.
Three key findings have been relevant as the initiating problems
that motivated the research reported in this thesis:
When the analysis concerning the structure
and content of natural language expressions
is considered, one key factor
for quantitative problems
is the
combinatorial explosion caused by the contextuality of
interpretation at the semantic level.
Ambiguity further increases the necessity of taking the context
into account in order to make rational interpretations.
In a 500 000 word sample, (Järvinen, 1994)
reports an ambiguity rate of 16.4%, i.e.,
16 words out of 100 have more than one morphological
or syntactic interpretation.
Research work and experimentation of the use of morphological analysis and generation tools along with the full-text database system called Minttu provided experience on the themes of information retrieval (Alkula and Honkela, 1992). The Minttu system was developed by the Finnish State Computer Center (VTKK, currently the Tieto Group) and it is widely used for storage and retrieval of administrative documents including the Finnish law. The need for using morphological analyzers and generators arises from the fact that Finnish is a highly synthetic language. Many words are formed from a word stem and inflectional or derivational suffices generated by morphological transformations. Therefore, for instance, finding occurrences of a word in texts is problematic. The main result was a system architecture for keyword-based information retrieval (IR) systems that use morphological analyzers and generators of Finnish word forms (cf. Alkula and Honkela, 1992). The study also provided us insight into the general, well-known problems of IR. Searching for relevant documents from a very large collection has traditionally been based on keywords and their Boolean expressions. Often, however, the search results show high recall and low precision, or vice versa.
In summary, the main motivation for the research project
presented in this thesis arose
from the wish to develop
a framework based on a novel paradigm and
a practical application in which some
of the difficulties mentioned above would be taken into account.
The problems encountered in developing a natural-language
database interface led into
a re-evaluation of the status of the traditional
artificial intelligence
methodology and, specifically, that of natural language
processing.
Also many traditional philosophical underpinnings
had to be questioned. Both quantitative and qualitative issues had
to be considered. Firstly, the amount of knowledge needed in a successful
large-scale NLP application is vast. Secondly,
it seems that knowledge cannot be adequately modeled
only by means of symbolic
representation formalisms based on predicate logic.
Further argumentation for these
conclusions will be given in Chapter ![[*]](cross_ref_motif.gif) .
.
The experiences described above called for a completely new paradigm for approximate semantic analysis of natural language expressions. It turned out that the Self-Organizing Map formalism (Kohonen, 1995c) might provide means to cope with the qualitative and quantitative problems described earlier.
In this thesis,
the Self-Organizing Map will be introduced
in Chapter .
Chapter describes the principles
and practices of using the SOM in natural language processing and
interpretation,
and Chapter presents the use of the SOM
in a particular application area, i.e., information
retrieval and data mining of document collections.
),
the cells (or nodes) of which become specifically
tuned to various input signal patterns or classes of patterns
in an orderly fashion.
The learning process is competitive and unsupervised, meaning
that no teacher is needed to define the correct output
(or actually the cell into which the input is mapped)
for an input. In the basic version, only one map node (winner)
at a time is activated corresponding to each input.
The locations of the responses
in the array
tend to become ordered
in the learning process
as if some meaningful nonlinear coordinate
system for the different input features were being
created over the network (Kohonen, 1995c).
The SOM was developed by Prof. Teuvo Kohonen in the early 1980s (Kohonen, 1981a, 1981b, 1981c, 1981d, 1982a, 1982b). The first application area of the SOM was speech recognition, or perhaps more accurately, speech-to-text transformation (Kohonen et al., 1984,Kohonen, 1988).
Assume that some sample data sets
(such as in Table )
have to be mapped onto the array
depicted in Figure ;
the set of input samples is described by a real vector ![]() where t is the index of the sample,
or the discrete-time coordinate.
Each node i in the map contains a model
vector
where t is the index of the sample,
or the discrete-time coordinate.
Each node i in the map contains a model
vector ![]() ,which has the same number of elements
as the input vector
,which has the same number of elements
as the input vector ![]() .
.
The stochastic SOM algorithm performs a regression process.
Thereby, the initial values of the components of the model
vector, ![]() , may even be selected at random.
In practical applications, however,
the model vectors are more profitably
initialized in some orderly fashion, e.g., along
a two-dimensional subspace spanned by the
two principal eigenvectors of the input data vectors (Kohonen, 1995c).
Moreover, a batch version of the SOM algorithm may also
be used (Kohonen, 1995c).
, may even be selected at random.
In practical applications, however,
the model vectors are more profitably
initialized in some orderly fashion, e.g., along
a two-dimensional subspace spanned by the
two principal eigenvectors of the input data vectors (Kohonen, 1995c).
Moreover, a batch version of the SOM algorithm may also
be used (Kohonen, 1995c).
| 250 | 235 | 215 | antique white |
| 165 | 042 | 042 | brown |
| 222 | 184 | 135 | burlywood |
| 210 | 105 | 30 | chocolate |
| 255 | 127 | 80 | coral |
| 184 | 134 | 11 | dark goldenrod |
| 189 | 183 | 107 | dark khaki |
| 255 | 140 | dark orange | |
| 233 | 150 | 122 | dark salmon |
| ... | ... | ... | ... |
Any input item is thought to be mapped into
the location, the ![]() of
which matches best with
of
which matches best with ![]() in some metric.
The self-organizing algorithm creates the ordered
mapping as a repetition of
the following basic tasks:
in some metric.
The self-organizing algorithm creates the ordered
mapping as a repetition of
the following basic tasks:
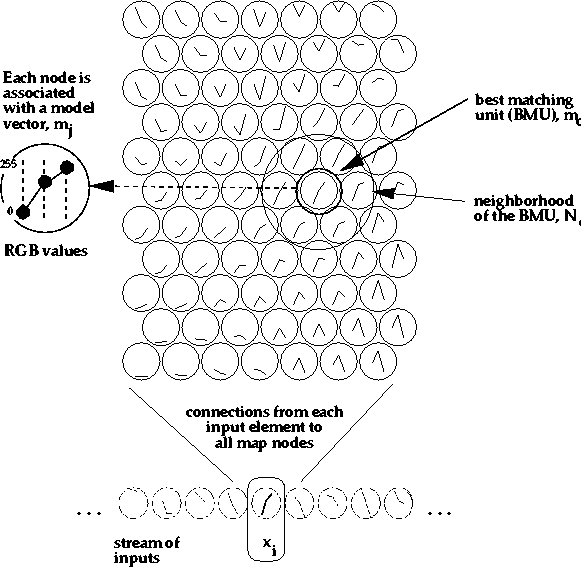 |
The basic idea in the SOM learning process
is that, for each sample input vector ![]() ,the winner and the nodes in its
neighborhood are changed closer to
,the winner and the nodes in its
neighborhood are changed closer to ![]() in the
input data space.
During the learning process, individual changes
may be contradictory,
but the net outcome in the process
is that ordered values for the
in the
input data space.
During the learning process, individual changes
may be contradictory,
but the net outcome in the process
is that ordered values for the ![]() emerge over the array.
If the number of available input samples
is restricted, the samples must be presented
reiteratively to the SOM algorithm.
The random initial state, two intermediate states,
and the final map
are shown in Figure .
emerge over the array.
If the number of available input samples
is restricted, the samples must be presented
reiteratively to the SOM algorithm.
The random initial state, two intermediate states,
and the final map
are shown in Figure .
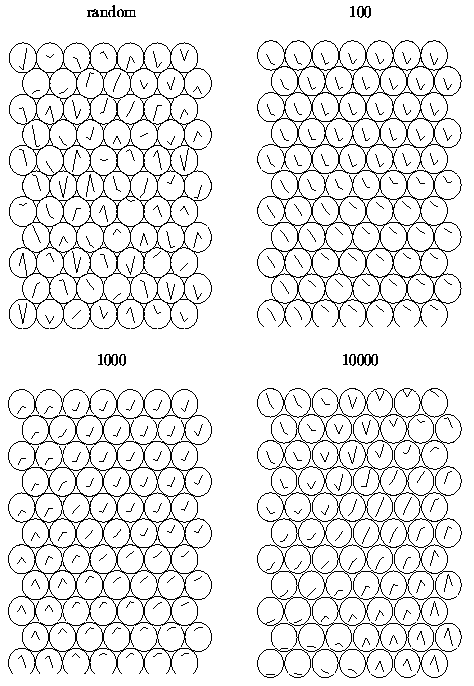 |
Adaptation of the model vectors in the learning process may take place according to the following equations:
(1)
otherwise,
where t is the discrete-time index of the variables,
the factor ![]() is a scalar that defines
the relative size of the learning step, and
Nc(t) specifies the neighborhood around the winner
in the map array.
is a scalar that defines
the relative size of the learning step, and
Nc(t) specifies the neighborhood around the winner
in the map array.
At the beginning of the learning process the radius of the
neighborhood is fairly large, but it
is made to shrink during learning.
This ensures that the global order is obtained
already at the beginning, whereas towards the end,
as the radius gets smaller, the local corrections of the
model vectors in the map will be more specific.
The factor ![]() also decreases during learning.
also decreases during learning.
 |
One method of evaluating the quality of
the resulting map is to calculate
the average quantization error over the input samples,
defined as E![]() where c indicates the best-matching unit for x.
After training,
for each input sample vector the best-matching unit in the
map is searched for,
and the average of the respective quantization errors is
returned.
where c indicates the best-matching unit for x.
After training,
for each input sample vector the best-matching unit in the
map is searched for,
and the average of the respective quantization errors is
returned.
The mathematical analysis of the algorithm has turned out to be very difficult. The proof of the convergence of the SOM learning process in the one-dimensional case was first given in (Cottrell and Fort, 1987). Convergence properties are more generally studied, e.g., in (Erwin et al., 1991,Erwin et al., 1992a,Erwin et al., 1992b,Horowitz and Alvarez, 1996,Flanagan, 1997). A number of details about the selection of the parameters, variants of the map, and many other aspects have been covered in the monograph (Kohonen, 1995c). The aim of this work is not to study or expound the mathematical and statistical properties of the SOM. The main point of view is to regard the SOM as a model of natural language interpretation, and explicate its use in natural language processing (NLP) applications, especially in information retrieval and data mining of large text collections, as introduced in the following chapter.
Most computations reported in the publications have been conducted using the SOM_PAK software package (Kohonen et al., 1996a).
In the following, four particular views of the SOM are selected to serve as a basis for further inspection of the following chapters: 1. The SOM is a model of specific aspects of biological neural nets, 2. The SOM constitutes a representative of a new paradigm in artificial intelligence and cognitive modeling, 3. The SOM is a tool for statistical analysis and visualization, 4. The SOM is a tool for the development of complex applications.
.
The relationship between the SOM and its
counterparts in neurodynamics is described
in detail, e.g., in
(Kohonen, 1992;
1993;
1996b).
This issue, however, is
only of indirectly related to this work, while
the second and the fourth of these
four threads are the main
points of view to be considered.
.
Some applications require efficient construction of large maps. Searching the best-matching unit is usually the computationally heaviest operation in the SOM. Using a tree-structured SOM, it is possible to use hierarchical search for the best match (Koikkalainen and Oja, 1990,Koikkalainen, 1994). In this method, the idea is to construct a hierarchy of SOMs, teaching the SOM on each level before proceeding the next layer. Another speedup method for making the winner search faster, based on the idea of Koikkalainen, is presented in (Kohonen et al., 1996b).
Most SOM applications use numerical data. The purpose of the present thesis is to demonstrate that statistical features of natural text can also be regarded as numerical features that facilitate the application of the SOM in NLP tasks.
.
It seems likely that the methods
available have been more suitable for the study of
morphology and syntax. It also seems that the artificial
neural network models can offer a promising methodology
for dealing with these areas.
The connectionist study of morphology has been more limited in volume. However, already Koskenniemi (1983) discussed the relation between finite state automata used in his two-level model and neural networks. A widely referenced model of learning past tenses of English verbs was presented by Rumelhart and McClelland (1986). The aim was to demonstrate that (a) the model is able to capture the typical three-stage pattern of verb acquisition, (b) differences on performance on different types of regular and irregular verbs, and (c) the model responds appropriately to verbs that it has never seen before as well as to those included in the training set. Recently, Tikkala et. al (1997) have presented connectionistic models for simulating both normal and disordered word production as well as child language acquisition for Finnish.
In spite of the possibility to model linguistic phenomena in new ways, much of the connectionistic linguistic study has also mainly dealt with syntax and parsing. The relationship to main-stream generative linguistics is often close. Many models rely on the framework of well-known symbolic grammars (e.g., Faisal and Kwasny 1990, Nakamura et al. 1990, Schnelle and Wilkens 1990).
Connectionist approaches have been criticized,
for instance, by claiming that a proper linguistic
method should be able to represent constituent
structures and to model compositionality
(Fodor and Pylyshyn, 1988). Multiple answers can be given
to this line of criticism.
At the level
of semantics and pragmatics, the contextuality
may be considered to be more important:
the final interpretation of an expression is determined
in the context in which it appears.
In addition, specific models that capture
compositionality have been developed,
e.g., RAAM, Recurrent Auto-Associative Memory
(Pollack, 1990). Moreover, the SOM is also able to
represent implicit hierarchical structures.
This issue will be handled in more detail
in Section .
An overview of connectionist, statistical and symbolic approaches in NLP and an introduction to several articles is given by Wermter et al. (1996).
It may be asked why one should be interested in, e.g.,
the cognitive and philosophical point of view related
to the NLP. The phenomena, as such, are naturally
a relevant area of study.
From the application point of view,
the underlying principles of an approach
used in constructing an NLP application
may severely limit the chances to gain practical success.
That may be considered to have happened in the traditional
AI research and development. It remains to be seen, of
course, how far one can reach by adopting the
paradigm of radically connectionist
unsupervised learning devised, e.g., by
the Self-Organizing Maps.
In conclusion, the aim of this work is to study
the natural language processing in a rather
reductionistic way when considered from the
traditional point of view in which explicit
theories of the phenomena are built.
The aim is to study
semantics and pragmatics to see
which phenomena might be successfully
modeled using the artificial neural
network approach based on the
Self-Organizing Maps, and to consider
what the characteristics of
the practical applications based on
this approach are (Chapter ).
The next
chapter introduces a
model of automatic statistical lexical analysis
based on the SOM.
Contextual information has widely been used in statistical analysis of natural language corpora. Charniak (1993) presents the following scheme for grouping or clustering words into classes that reflect the commonality of some property.
The open questions are: what are the properties used in the vector, the distance metric used to decide whether two points are close to each other, and the algorithm used in clustering. In all of the publications of this thesis, the algorithm used has been the SOM. The SOM does both vector quantization and clustering at the same time. Moreover, it produces a topologically ordered result.
Handling computerized form of written language rests on processing of discrete symbols. How can a symbolic input such as a word be given to a numeric algorithm? Similarity in the appearance of the words does not usually correlate with the content they refer to. As a simple example one may consider the words ``window'', ``glass'', and ``widow''. The words ``window'' and ``widow'' are phonetically close to each other, whereas the semantic relatedness of the words ``window'' and ``glass'' is not reflected by any simple metric.
One useful numerical representation
can be obtained by taking into account
the sentential context in which the words occur.
Before utilization of the context information,
however, the numerical value of the code should not imply
any order to the words.
Therefore, it will be necessary to use uncorrelated vectors
for encoding.
The simplest method to introduce uncorrelated
codes is to assign a unit vector for each word.
When all different word forms in the
input material are listed, a code vector
can be defined to have
as many components as there are word forms in the list.
As an example related to
Table shown
earlier,
the color symbols of Table
are here replaced by binary numbers that encode them.
One vector element (column in the table)
corresponds to one unique color symbol.
| 0.250 | 0.235 | 0.215 | 1 | ... | |||||
| 0.165 | 0.042 | 0.042 | 1 | ... | |||||
| 0.222 | 0.184 | 0.135 | 1 | ... | |||||
| 0.210 | 0.105 | 0.030 | 1 | ... | |||||
| 0.255 | 0.127 | 0.080 | 1 | ... | |||||
| 0.184 | 0.134 | 0.011 | 1 | ... | |||||
| ... | ... | ... | . | . | . | . | . | . | ... |
The component of the vector where the index
corresponds to the order of the word
in the list is set to the value ``1'', whereas
the rest of the components are ``0''.
This method, however, is only practicable in small experiments.
With a vocabulary picked from a even reasonably large corpus
the dimensionality
of the vectors would become intolerably high.
If the vocabulary is large,
the word forms
can be encoded by quasi-orthogonal random vectors
of a much smaller dimensionality (Ritter and Kohonen, 1989).
Such random vectors can still be considered to
be sufficiently dissimilar
mutually and not to convey any information
about the meaning of the words.
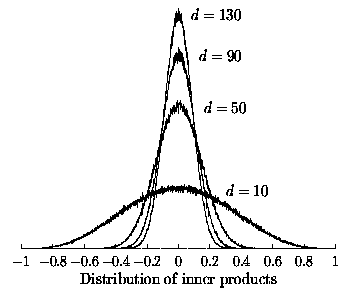
The influence of the random vector dimension
on the pairwise deviance from the orthogonality
is illustrated in Figure .
Mathematical analysis of the random encoding
of the word vectors is presented in
(Kaski, 1998).
 |
In the unsupervised formation of the word category map, each input x consists of an encoded word form and its averaged context. Each word in the vocabulary is encoded as an n-dimensional random vector. In our experiments (see, e.g., Publication 3) n has often been 90. A more straightforward way to encode each word would be to reserve one component for each distinct word but then, especially with a large vocabulary, the dimensionality of the vector would be computationally intractable. A mathematical analysis of the dimensionality reduction based on random encoding is presented by Ritter and Kohonen (1989).
The procedure of forming the word category map is presented in Publications 3, 4, 5, 7 and 9. In the following, the basic three steps are explained and motivated. Further methodological details are given in the publications.
The averaging process is well motivated when the computational point of view is considered. The number of training samples is reduced considerably in the averaging. The main disadvantage seems to be that information related to the varying use of single words is lost.
Evaluating word category maps could, in principle,
be based on calculating the quantization error of the map
(see Chapter ).
However, in many applications the most important factor
is the relative location of the words on the map.
Therefore, measures for evaluation that take
into account the word location are necessary.
Kaski and Lagus (1996) present
a method for comparing
instances of SOMs. This method is used in
Publication 6 to compare the results when
the number of word forms on the map and the neighborhood
type are considered. The comparison method suits
best to tasks in which the effect of parameter
changes need to be evaluated.
Another possibility is to use
a set of word lists as a basis of the
evaluation. Each list consists of words
that are expected to appear in nearby locations.
Some preliminary tests have been made using this
method.
A practical measure that can be used in
the word map evaluation is to make comparison
in a further level of processing, e.g.,
when the document maps are created (see Chapter ).
The classification results on the document map
can be used as the decision factor.
Often, it is practically impossible
to create a map that satisfies
all the expectations of a human viewer.
The reason may be that either the
input data simply does not contain
necessarily detailed and balanced
context information, or,
the expectations may vary.
The natural variation in multiple aspects
of human linguistic behavior and how
it can be modeled using the SOM is the
main theme of the Section .
In Publications 7 and 9, various applications
of word category maps are considered.
The main application related to the current
work is information retrieval and data mining
of full-text document collections.
The topic is introduced in Section .
In the following, a review of the research based on and
related to the lexical SOMs is given.
Thereafter, the potential of the word category
maps in modeling three phenomena is considered:
gradience or fuzziness in the relation between
expressions and their referents (Section ),
subjectivity in generating and interpreting natural language
expressions (Section ),
autonomous emergence of linguistically motivated
implicit word classes or categories
in a statistical analysis
based on the
contexts of the words (Section ).
As already mention earlier, the basic method for creating word category maps was introduced by Ritter and Kohonen (1989; 1990). Scholtes has applied the SOM in multiple NLP experiments. His main area is information retrieval (Scholtes, 1993).
Miikkulainen has widely used the SOM to create a model of story comprehension. The SOM is used to make conceptual analysis of the words appearing in the phrases (Miikkulainen, 1990a; 1990b; 1991; 1993a; 1993b; Miikkulainen and Dyer, 1991) . A model of aphasia based on the SOM is presented in (Miikkulainen, 1997). The model consists of two main parts: the maps for the lexical symbols in the different input and output modalities, and the map for the lexical semantics. A thorough framework for connectionist modeling of aphasia is presented in (Persson, 1995).
Scholtes has also used the SOM to parsing (Scholtes, 1992a; Scholtes and Bloemberger, 1992). An overall presentation is given in (Scholtes, 1993).
In (Schütze, 1992) cooccurence information is used to create lexical spaces. Here, the dimensionality reduction is based on singular value decomposition. In computing the context vectors, the window sizes are 1000 or 1200 characters rather than a fixed number of words. An automatic method for word sense disambiguation is developed: a training set of contexts is clustered, each cluster is assigned a sense, and the sense of the closest cluster is assigned to the new occurrences. Schütze uses two clustering methods to determine the sense clusters.
Bookman's model for natural language interpretation, LeMICON (Bookman, 1994), combines symbolic and connectionist representations. LeMICON is a structured connectionist model that makes use of both connectionist and symbolic techniques to construct interpretations of text. The basic building blocks of LeMICON include a semantic memory and a working memory. Each concept in the semantic memory is represented by a vector of so-called ``analog semantic features'' of dimension 454. These 454 named features are based on a selection from the category structure of the Roget's thesaurus. Thus, the approach is more ``classical'' than the one adopted in this work. Bookman demonstrates how to perform automatic knowledge acquisition using a 7 million word database of Wall Street Journal articles. The semantic memory of the LeMICON system is constructed automatically based on an unsupervised learning algorithm.
.
For instance, the majority of knowledge representation
formalisms used in the artificial intelligence
and natural language processing research have been
based on the tacit assumption of the world
consisting of entities and relations between these
entities. The words in the language are considered
to be ``labels'' of the entities.
The formalisms based on predicate logic
contain predicates
and their arguments (to model static structures
of entities and their relations),
logical connectives and quantifiers, and implications
(to model rule-like phenomena and dependencies).
Semantic networks and frame systems
share the underlying ontological assumption.
See, e.g., (Winston, 1984) for an overview
of the ``classical'' AI techniques.
Their influence on the models and metaphors
used in cognitive science is also substantial,
see, e.g., (Eysenck and Keane, 1990) for a textbook account.
Natural language is nowadays usually not viewed as a means for labeling the world but being an instrument by which the society and the individuals within it construct a model of the world. The world is continuous, and changing. Thus, the language is a medium of abstraction rather than a tool to create an exact ``picture'' of selected portions of the world. In the abstraction process, the relationship between a language and the world is one-to-many in the sense that a single word or expression in language is most often used to refer to a set or to a continuum of situations in the world. Thus, in order to model the relationship between language and world, the mathematical apparatus of the predicate logic, for instance, does not seem to provide enough representational power. One way of enhancing the representation is to take into account the unclear boundaries between different concepts. Many names have been used to refer to this phenomenon such as gradience, fuzziness, impreciseness, vagueness, or fluidity of concepts.
Perhaps the most widely used mathematical method of
modeling gradience is fuzzy logic and fuzzy membership
theory (Zadeh, 1965,Kosko, 1997). It is beyond the
scope of this work to give a detailed description
of fuzzy logic. For the purposes of the following discussion
a simple example may be sufficient.
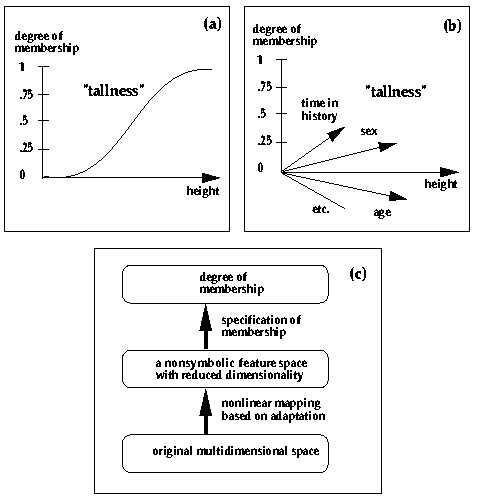
Regarding the sentence ``John is tall'',
the 'truth' of the sentence is a matter of degree.
It is not possible to state a limit of tallness
above which John would definitely be tall and under it
not. In fuzzy logic the truth of a proposition
is expressed by a value between 0 and 1 rather
than being just 'true' or 'false'
(see Figure a).
Accordingly,
an item may belong to a set in a fuzzy manner.
The degree of membership of a set is also specified
by a graded value from the real interval between 0 and 1.
Often, however, a single dimension such as height
is not enough: to state whether a person is tall
one must also know her or his sex, age, genetic
background, etc. (see Figure b).
The degree of membership becomes, thus, a surface
in a multi-dimensional space rather than
a curve of one variable.
The status or necessity of fuzzy logic has been questioned, e.g., by many traditional logicians (see, e.g., Haack 1996). Regardless of the philosophical arguments fuzzy logic has been found to be useful in constructing, for instance, practical control systems for cars, cameras, industrial processes, washing machines, etc. (Kosko, 1997).
Unsupervised learning can be used to learn the fuzzy descriptions of input data (Dickerson and Kosko, 1997). Using SOMs to learn descriptions of impreciseness of natural language is also the topic of Publication 1. The SOM is considered as a fuzzy classifier by Mitra and Pal (1994) (see also Mitra96). Tirri (1991) and Leivian et al. (1997) use the SOM to preprocess data before further processing by symbolic AI methods (rule-based expert systems, inductive learning).
The possibility of abandoning the predetermined
discrete, symbolic features is worth
consideration.
The criticism towards fuzzy logic
of going too far
in rejecting the basic assumptions
of traditional logics
may even be
reversed by claiming that fuzzy logic does not
go far enough.
Fuzzy logic is based on predetermined
distinct features and therefore the descriptions
created within it are
not autonomous even if the membership
clusters are found by using unsupervised
learning.
Publication 9 discusses
how the symbols could be ``broken up''.
Figure c
outlines a scheme for such an approach.
If suitable ``raw data'' are used,
it may not be necessary to use any
intermediate levels in
facilitating interpretation.
For example, de Sa (1994) proposes
a model of learning in a
cross-modal environment based on
the SOM. The SOM is used to associate
input from different modalities (pictures,
language). De Sa's practical experiments
use, however, input for which the interpretation
of the features is given beforehand.
Nenov and Dyer (1993,
1994
) present
an ambitious model and experiments
on perceptually grounded language
learning which is based on
creating associations between
linguistic expressions and visual images.
A mathematical framework for continuous formal systems is given by (MacLennan, 1995); it can be based on, e.g., Gabor filters. Traditionally, the filters have to be designed manually. To facilitate automatic extraction of features, the ASSOM method (Kohonen, 1995a; 1995b; 1996a; Kohonen et al., 1997a; 1997b) could be used. For instance, the ASSOM is able to learn Gabor-like filters automatically from the input image data. It remains to be seen, though, what kinds of practical results can be acquired by aiming at still further autonomy in the processing, e.g., by combining uninterpreted speech and image input. The scope and time table of such study is, of course, far beyond the current work.
 |
The CYC project (Lenat et al., 1990) has
collected a vast amount of knowledge to be used in
large-scale natural language processing applications.
Dozens of person years have been spent in coding the
knowledge representations by means of traditional AI
in terms of entities, rules, scripts, etc.
It seems, however, that the qualitative problems are not
satisfactorily solved by only adding
more and more pieces of symbolic knowledge representations to a system.
The world is changing all the time, and, perhaps still more
importantly, the symbolic descriptions are not
grounded.
The contextuality
of interpretation is easily neglected,
being, nevertheless, a very commonplace phenomenon
in natural language (see, e.g., Hormann 1986).
A model of contextuality in interpreting
imprecise size expressions is presented in Publication 1.
The importance of context becomes evident when, e.g., ambiguity is considered: the interpretation of ambiguous expressions is based on their context. Pulkki (1995) presents means for modeling ambiguity using the SOM. The basic idea is to teach small ``context maps'' so that the main SOM can process the contextual information into clusters. Each model vector of the single-word maps corresponds to a particular ``sense'' of the word. The SOM is used to resolve ambiguity in (Scholtes, 1992b). Gallant (1991) has also developed a neural network based approach for word sense disambiguation. A model for lexical disambiguation is presented by Mayberry and Miikkulainen (1994). The model is based on analyzing the frequencies of the contexts of ambiguous words. A recurrent network parser combines the context frequencies one word at a time, producing as the output the most likely interpretation of the current sentence.
A more traditional NLP approach is presented by Hirst (1987) with numerous illuminating examples of various types of ambiguity. Raukko (1994; 1997) discusses the linguistic phenomena of, or related to, ambiguity (polysemy, homonymy, vagueness) and proposes a view according to which the polysemous and vague words should not be considered as distinct entities but rather as patterns in continuous lexical space. This view is compatible with the approach adopted in this work.
Furnas et al. (1987) have found that in spontaneous word choice for objects in five domains, two people favored the same term with less than 20% probability. Bates (1986) has shown that different indexers, well trained in an indexing scheme, might assign index terms for a given document differently. It has also been observed that an indexer might use different terms for the same document at different times.
Chen et al. (1995) reported that system-generated concept spaces outperformed human-generated thesauri in concept recall (i.e., the concept spaces provide more meaningful concept associations), but the human-generated thesauri are more precise in their suggested associations than those suggested by the system-generated thesauri.
Moore and Carling (1988) state: ``Languages are in some respect like maps. If each of us sees the world from our particular perspective, then an individual's language is, in a sense, like a map of their world. Trying to understand another person is like trying to read a map, their map, a map of the world from their perspective.'' It seems that the SOM can be used in modeling the individual use of language: to create maps of subjective use of language based on examples, and, furthermore, to model intersubjectivity, i.e., to have a map that also models the contents of other maps. This is the main topic of Publication 2.
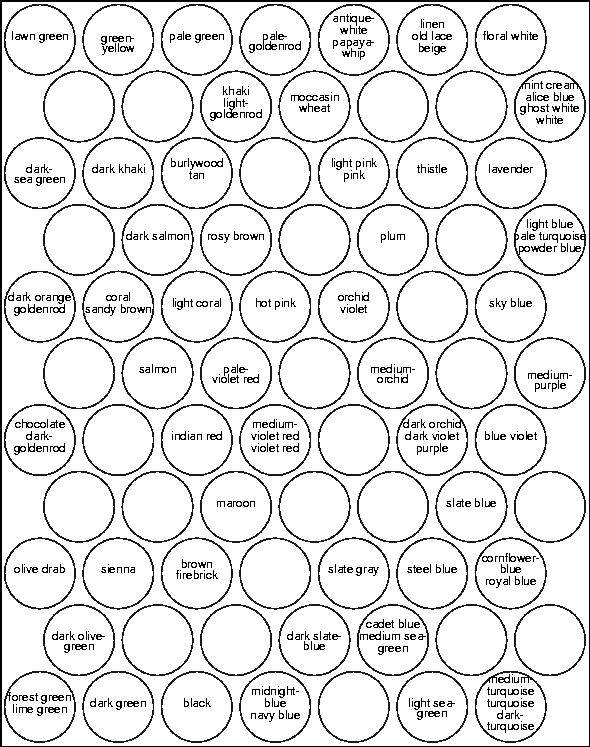
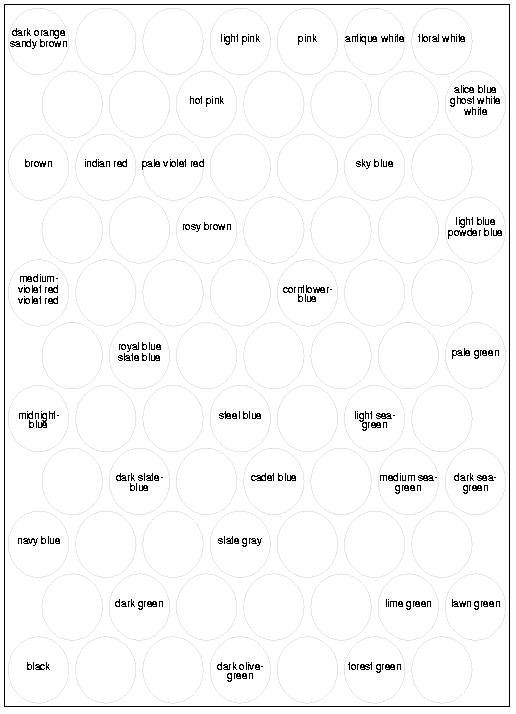
As an example related to the vocabulary problem,
two persons may have different conceptual
or terminological ``density'' of the topic under
consideration. A layman, for instance, is likely
to describe a phenomenon in general terms whereas
an expert uses more specific terms. This distinction
is illuminated by the pair of color word maps
in Figures (in Chapter )
and . The first map contains much
more refined symbols for the colors.
Publication 2 proposes a model that adds a third vector element,
i.e., the specification of the identity of the utterer of
the expressions. Thus, the network would be selective
according to the ``listener''.
When, for instance, the maps
in Figures
and are considered, the enhanced map would
provide a means for selecting which are the specific terms
that can be used in communication with those having
equal level of detailed knowledge and what is the scope
of use of the general terms in the other cases. The detailed
map contains, e.g., many expressions for different kinds
of blue that would be uninterpretable when the second
map is used. This naturally holds if the color is not
present in the input. If the color is provided for
both maps the less detailed model can be refined.
Further discussion can be found in Publication 2.
When the input vector contains both
context and symbol parts
the degree of supervision can be moderated
(controlled) using a single weight parameter
(Ritter and Kohonen, 1990).
In creating word category maps
the symbol part of the input vector is normally
scaled so that it does not significantly contribute
to the ordering of the map. A corresponding case
is presented in Figure .
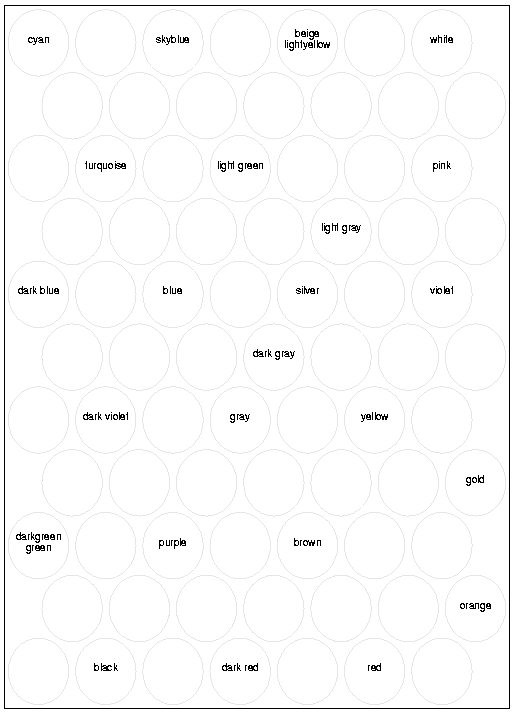
The different colors overlap, for instance,
two instances of white (``white'', ``ghost white'')
can be found in the same node with an instance
of very light blue (``alice blue'').
In addition, the areas of orange, red, and brown are
intertwined.
|
Figure shows the result of an experiment
in which the symbol part had 10 times higher weight
than in the previous one.
In both experiments, the colors
were classified into 9 classes based on
the head word of the color. Thus, e.g.,
all the different instances of green shared the
same symbol in the input vector. The difference
of the maps reflects the classifying effect
of the symbolic part.
 |
As a summary, the potential of modeling subjectivity
gives ground to applications in which
the SOM is used to learn, e.g.,
the interests or the level of terminological
knowledge of the user.
Honkala (1997)
presents a model of
browsing behavior by analyzing WWW user logs
which provides an example of personalization
(however, not based on linguistic analysis).
The possibility of modeling subjectivity can be contrasted with the traditional AI knowledge representation formalisms that provide very limited means for approaching this phenomenon. Brazdil and Muggleton (1991) use symbolic inductive inference as a means to learn to relate terms in a multiple agent communication as a kind of a model of intersubjectivity. They try to overcome language differences between agents automatically in a situation where the agents do not have the same predicate vocabulary. The system consists of a number of separate agents that can communicate. Each agent is able to perceive a portion of the given, possibly simulated world (in a symbolic form), accept facts and rules from another agent, formulate queries and supply them to another agent, respond to queries formulated by another agent, interpret answers provided by another agent, induce rules on the basis of facts, and integrate the knowledge. Their symbolic model of the environment is closely related to the model-theoretic approaches used in defining the semantics of formal languages. The inductive learning paradigm with symbolic representations does not, however, take into account that the meaning of an expression (queries, responses) in a natural domain is graded and changing, biased by the particular context, as discussed above.
The areas on a word category map can be considered as implicit categories or classes that have emerged during the learning process. Single nodes can be considered to serve as adaptive prototypes. Each prototype is involved in the adaptation process in which the neighbors influence each other and the map is gradually finding a form in which it can best represent the input.
One classical approach for defining concepts is based on the idea that a concept can be characterized by a set of defining attributes. The prototype theory of concepts involves that concepts have a prototype structure and there is no delimiting set of necessary and sufficient conditions for determining category membership that can also be fuzzy. Instances of a concept can be ranked in terms of their typicality. Membership in a category is determined by the similarity of an object's attributes to the category's prototype. The development of prototype theory is based on the works by, e.g., Rosch (1977) and Lakoff (1987). MacWhinney (1989) discusses the merits and problems of the prototype theory. He mentions that prototype theory fails to place sufficient emphasis on the relations between concepts. MacWhinney also points out that prototype theory has not covered the issue of how concepts develop over time in language acquisition and language change, and, moreover, it does not provide a theory of representation. MacWhinney's competition model has been designed to overcome these deficits. Recently, MacWhinney has presented a model of emergence in language based on the SOM (MacWhinney, 1997). His work is closely related to the adaptive prototypes of the word category maps, and to any maps of words that have been presented and discussed in Publications 1, 3, 4, 5, 6, 7, and 9. In MacWhinney's experiments the SOM is used to encode auditory and semantic information about words. Also Gärdenfors' recent work (e.g., Gärdenfors, 1996a; 1996b) is very closely related to the issue of adaptive prototypes.
.
The data mining use of the SOM has been extensively studied
by
Kaski (1997b).
In the following,
some general aspects of data mining of texts are outlined.
In textual data mining and information retrieval the needs of the user may vary from looking for a specific piece of knowledge to a general wish to familiarize oneself with a subject area. The person's level of knowledge determines how well she or he is able select the terms and phrases in a specific search. In addition, the capability of using the methods and tools in a natural way influences the effectiveness of the search or exploration process. When evaluating information retrieval systems the user's needs are often considered rather narrowly, based on the relevance judgments of the results acquired from a query. The reason for this probably is that the relevance studies can be formalized easily. Overall user satisfaction is, of course, more important than any single relevance evaluation. To outline a broader view one may ask how well the user is aware of the domain of the inquiry, the document collection, and her or his information needs.
The document collections may vary in many respects, the most relevant of which for this thesis are: the size of the collection, the length of the documents, the style and type of content of the texts, and the possible additional information including classification of the documents and index terms.
The basic approaches for information retrieval and data mining for which a system may provide support are: (1) searching using keywords or key documents, (2) exploration of the document collection supported by organizing the documents in some manner, and (3) filtering. The keyword search systems can be automated rather easily whereas the document collections have traditionally been organized manually. The organization is usually based on some (hierarchical) classification schemes; each document is assigned manually to one or several classes. Another kind of organization can be provided by introducing associations between the documents manually. Filtering refers to discarding uninteresting documents from an incoming document flow.
One of the oldest methods of searching for texts
that matches a query
is to index all of the words (hereafter called the terms)
that have appeared in the document collection.
The query itself, typically a list of appropriate keywords,
is converted into a list of terms. This
list is compared with the term list of each document to find matching
documents.
Various Boolean logic expressions can be formulated to control
the breadth of matching.
For instance, instead of a simple list of terms, the query
can be based on a
Boolean expression of the terms.
The following three basic problems
make it difficult to apply Boolean logic to text retrieval
(see, e.g.,
Salton 1989).
(1) Recall and precision of retrieval is
sensitive to small changes in formulation of a query.
For Boolean queries there is no simple
way of controlling the size of the output,
and the output is not ranked in the
order of relevancy. (2) Considering the results of a query it is
not known what was not found, especially if the document collection is
unfamiliar. (3) If the domain of the query
is not known well it is difficult to
formulate the query, i.e., to select the appropriate key words.
It is a very basic problem in the text document management that different words and phrases are used for expressing similar objects of interest. Natural languages are used for the communication between human beings, i.e., individuals with varying background, knowledge, and ways to express themselves. Therefore, if information retrieval is based only on the keywords as they appear in the text some interesting documents may not be discovered, or misleading documents may be returned. The traditional information retrieval methods have limited possibilities to tackle this phenomenon. Clearly, the information retrieval systems might therefore benefit from taking into account the contexts of the words and deriving relations of the words based on the contextual information.
One solution suggested for the selection of a vocabulary or of keywords is the use of thesauri. The systems could return not only the documents that match the query but also documents that match some synonyms, found in the thesaurus. However, if a thesaurus is used, the system will often return a larger number of irrelevant documents. Another problem in using a thesaurus that it may be difficult to create and maintain manually.
In the automatic recognition of items such as visual objects or segments of speech, one often represents the item as a real pattern vector of a number of feature values. One of the oldest pattern recognition methods is to compare the representations in some metric, e.g., the Euclidean metric, or based on similarity functions such as direction cosines between the pattern vectors.
The vector space model has been proposed by (Salton et al., 1975,Salton, 1989) to document collection analysis. It constitutes an alternative approach to the use of the Boolean algebra to combine the terms in the queries. In the vector space model, both the stored documents and the user's queries are represented by vectors where each dimension corresponds to a term. The value of a component, called a weight, may be a function of the frequency of the occurrence of the term in the document, and of how important the term is considered to be. Documents and queries are then compared based on some similarity functions between the vectors. Given a query, each document can be assigned a similarity score which indicates the quality of the match between the query and the document. The scores can be ranked and displayed to the user to provide the documents in the intended order of relevancy. Also word counts, i.e. term frequencies, can be used to measure differences of emphasis between documents. A major problem in the vector representation of documents is that in the representation all pairs are considered equally similar. Semantical relationships between the terms are not taken into account.
A successful system should be able to tackle the most
important
problem areas of information retrieval and textual data mining
that were discussed in Section .
In addition, it should be possible to use
the system in
different ways to meet as many of the different needs as possible.
In the following a short
summary of the basic requirements is given.
The system should:
A thorough overview of connectionist models in information retrieval is given in (Doszkocs et al., 1990). The connectionist models, often combined with the principles of the vector space model, appear to be a promising alternative for the traditional keyword-based methods. In the following, a novel SOM-based method for information retrieval and textual data mining, called WEBSOM, is introduced. The WEBSOM aims at satisfying the requirements listed above.
To produce maps that display similarity relations between document contents a suitable statistical method must be devised for encoding the documents. Perhaps the most straightforward method is to encode the documents based on the words or words forms they contain. In an early study, a small map of scientific documents was formed based on the word forms in their titles (Lin et al., 1991,Lin, 1992). Later also Lin has extended his method to full-text documents (Lin, 1997). When using the vector space model, the general procedure for converting documents to vectors can be summarized as three steps (modified from Lin, 1997):
Scholtes
has developed, based on the SOM, a neural filter and a neural interest
map for information retrieval (Scholtes, 1993).
In addition to encoding the documents based on their words,
Scholtes has used character n-grams in the encoding. This approach
has also been adopted in
(Hyötyniemi, 1996).
Merkl
(1993;
1994;
1995a;
1995b;
1997;
Merkl et al.,
1994)
has used the SOM to cluster textual
descriptions of software library components based
on similar principles. Some of the experiments have been
based on the use of hierarchical SOMs (see Chapter ).
Document maps have also been created by
Rozmus (1995) and
Zavrel (1995; 1996).
The AI Group lead by Hsinchun Chen
in the MIS Department at the University of Arizona
report that they have used the SOM in
their ``ET-Map'' in categorizing the content
of Internet documents to aid in searching and
exploration.
By virtue of the Self-Organizing Map algorithm, documents can be mapped onto a two-dimensional grid so that related documents appear close to each other. If the word forms are first organized into categories on a word category map, an encoding of the documents can be achieved that explicitly expresses the similarity of the word meanings. The encoded documents may then be organized by the SOM to produce a document map. The visualized document map provides a general view of the document collection.
The basic processing architecture of the WEBSOM method
is presented in Figure . The details
of the method are described in Publications 4 and 5.
An overview is given below.
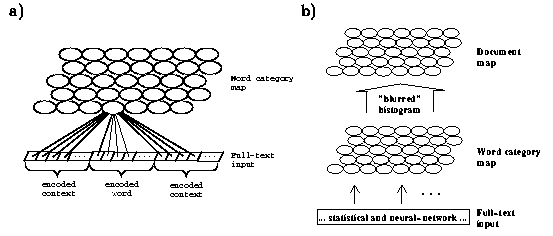
|
The documents are encoded by mapping their text, word by word,
onto the word
category map whereby a histogram of the ``hits'',
a word category histogram, on it is formed.
The histogram is a kind of ``fingerprint'' of the document.
To reduce the sensitivity of the histogram to small variations in
the document content the histograms can be smoothed using, e.g., a Gaussian
convolution kernel (see Publication 4).
This is possible since the word category map
is spatially ordered according to semantic
similarity relations between the words.
The document map is then formed by the SOM algorithm
using the word category histograms as inputs.
The WEBSOM has two possible modes of operation: unsupervised and supervised. In the former, clustering of the word category histograms of arbitrary text files is made by a normal Self-Organizing Map, whereby no class information about the documents is utilized. The organization of the documents is simply based on the analysis of the raw texts. In the supervised mode of operation, separation of the document groups of the document map is enhanced by utilizing auxiliary information about in which topic category the documents belong to. A closer study of using the supervised-SOM principle (Kohonen et al., 1984,Kohonen, 1995c) in the WEBSOM method and experimental results can be found in Publication 4. The first results based on unsupervised learning are presented in Publication 5 as well as in the technical report (Honkela et al., 1996).
A WWW-based
browsing environment has been developed
for supporting the exploration
of document collections.
The browsing tool
provides a view of the map.
First, the user may
zoom at any map area of the main map
by pointing to the map image to view the underlying
document space in more detail.
The clustering between the
neighboring map nodes has been shown using
different shades of gray (see, e.g.,
Ultsch and Siemon -1990,
Ultsch 1993,
Merkl and Rauber 1997):
if the model vectors are similar, light shades are used.
Otherwise the dark shade
indicates that there is a jump in neighboring
model vectors.
The WEBSOM browsing interface is implemented as a set of
HTML documents that
can be viewed using a graphical WWW browser.
The interface and its use in
exploring document collections is considered in
detail in (Lagus et al.,
1996a;
1996b;
1996c).
An example of a document map is shown in Figure .
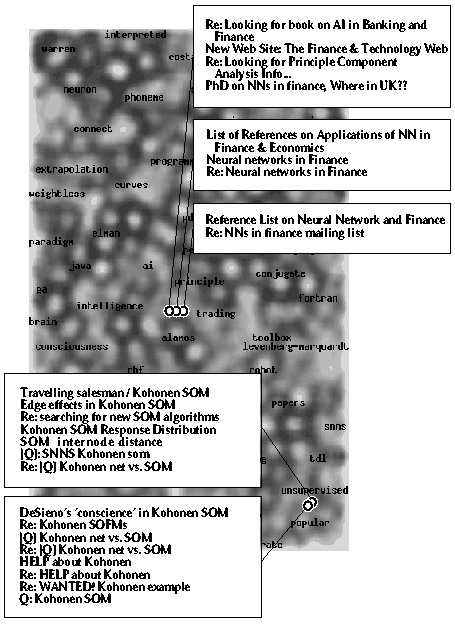 |
A map of conference abstracts is presented in (Lagus, 1997). The use of the SOM in data mining of both numerical and textual data collections is considered in detail in (Kaski, 1997b). General aspects of using the document maps are presented in Publication 8.
Since the first results the WEBSOM method has undergone significant developments. The developments, some of which are still unpublished are listed below.
.
The developments mentioned above will be reported in the forthcoming publications of the WEBSOM team.
)
have been worked out in the main contents of
this
thesis. However, some topics
have been given less emphasis than what could be
expected, for example the resolution of ambiguity.
The introduction outlined a large research
field which cannot, of course, be wholly covered in
a single dissertation. The main results may be
characterized to be, first,
the refinement of the methods of how to use
the SOM in natural language processing applications
and modeling in cognitive linguistics,
and, second,
the development of the WEBSOM method
in which the author's main contribution has
been the basic design of the two-level architecture.
The number of potential future directions is large, ranging from studies of the implications of the present work in, for instance, linguistics and philosophy of language. On the other hand, further development of applications warrants investigations. Some specific possibilities are mentioned in the following.
It would be interesting to study further the relationship between modeling natural language interpretation using the SOM and some related theories. Interesting viewpoints can be found in linguistics, cognitive linguistics, cognitive science, and philosophy of language. Specific related theories include, e.g., prototype theory, cognitive grammar, relevance theory, and constructivism. The use of the SOM in natural language processing could be compared with the wide range of other statistical and corpus-based approaches.
There exist several alternatives of encoding contextual information in the texts for the word category map. Only a small sample of these was covered in this work. Moreover, other means of collecting contextual information could be developed. They may be based on, e.g., associating words with input of other modalities. New applications in areas such as machine translation and collaborative systems could be developed. In machine translation the word category maps could be used, e.g., in lexical selection, i.e., finding a suitable word or phrase to be used in a context. Text materials in languages other than English could be processed. In the current work, the various word forms of the lexemes were encoded separately. This approach seemed to work well when English is considered. If the basic form of a word may occur in over 10 000 different inflectional word forms (like verbs in Finnish) novel problems must be solved.
In the WEBSOM method the relationship between the input data characteristics, the choices of the values for the parameters, and possible preprocessing tools requires in-depth studies. As a concrete example one may consider the effect of the document length on the WEBSOM process. In some cases a long document might be divided into shorter parts which would probably have clearer identity. In traditional keyword search that uses the Boolean algebra to combine the keywords one advantage is the possibility to combine terms in various ways so that the user controls the process. Similar functionality can be achieved in the WEBSOM method by allowing the user to combine the results of subsequent searches on the document map. It would also be useful to study user satisfaction in evaluating the WEBSOM method.
This document was generated using the LaTeX2HTML translator Version 97.1 (release) (July 13th, 1997)
Copyright © 1993, 1994, 1995, 1996, 1997, Nikos Drakos, Computer Based Learning Unit, University of Leeds.
The command line arguments were:
latex2html -split 2 honkela.tex.
The translation was initiated by Timo Honkela on 1/2/1998