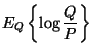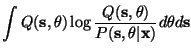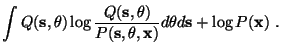In general there are infinitely many possible explanations of different complexity for the observed data. All the possible explanations should be taken into account and weighted according to their posterior probabilities. This approach, known as Bayesian learning, optimally solves the tradeoff between under- and overfitting.
In practice, exact treatment of the posterior pdfs of the models is impossible. Therefore, some suitable approximation method must be used. Ensemble learning [4,1,7,9], which is one type of variational learning, is a method for parametric approximation of posterior pdfs. The basic idea in ensemble learning is to minimise the misfit between the posterior pdf and its parametric approximation.
Let
![]() denote the exact posterior pdf and
denote the exact posterior pdf and
![]() its parametric approximation. The misfit is
measured with the Kullback-Leibler (KL) divergence
CKL between Pand Q, defined by the cost function
its parametric approximation. The misfit is
measured with the Kullback-Leibler (KL) divergence
CKL between Pand Q, defined by the cost function
Because the KL divergence involves an expectation over a distribution,
it is sensitive to probability mass rather than to probability
density. The term
![]() does not depend on the
parameters or the factors and can be neglected.
does not depend on the
parameters or the factors and can be neglected.
The learning resembles the expectation maximisation (EM) algorithm. The factors are adjusted while keeping the mapping constant and the mapping is adjusted while keeping the factors constant always minimising the cost function. All the parameters and factors are modelled with Gaussian distributions rather than point estimates.
A more detailed account of the unsupervised ensemble learning method used for nonlinear factor analysis and discussion of potentially appearing problems can be found in [6].