We shall now collect together the results derived in this section.
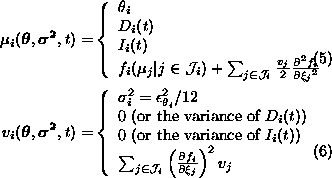
Substituting ![]() into
equation 7 yields equation 15 for the
expected description length LE.
into
equation 7 yields equation 15 for the
expected description length LE.
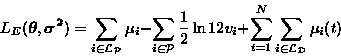 |
(9) |
Equations 13 and 14 describe how to convert a standard feedforward network into a network where the output of each neuron is assigned a mean and a variance. Equation 15 then defines the MDL-based cost function for such a network. The gradient of the cost function can be computed using standard backpropagation algorithm.