The production system stores all the necessary information to identify the operations done on a per product basis. Data of the products can be retrieved from the factory database with a database query. This data is used in modeling the process.
As in the Figure 5.3 the process data describes attributes of individual products. These attributes are the attributes of the incoming raw material in the form of element concentrations, the process parameter settings during the producing of a coil and the quality parameters of the final product shipped to the customer. The model variables from the process measurements can by summed in following:
A process model is constructed using these measurements. Model can be utilized to predict quality parameter values with given raw material and process parameter settings. In this way, we can study how different process settings contribute to the end product quality.
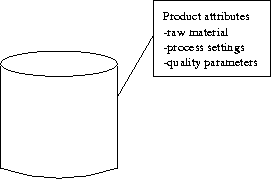
Figure 5.3: attributed product
The above mentioned parameters are gathered in a 28-dimensional vector
![]()
describing the product and its attributes. This vector is used to train a Self-Organizing Map. The approach is similar to that used in [2] in a process monitoring application. The difference is that in this case the measurement vector is a measurement of one particular product, whereas in [2] the measurement vector consists of the corresponding attributes of a sampled process state at a given time.
In this particular case study, passive data is used. Passive data is data collected during the normal operation of the plant. This kind of data does not cover all the possible operation points, but only those points already encountered in practice during the normal operation.