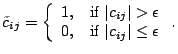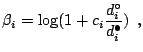Some analysis methods, for example, based on Bayesian inference, can provide information on the reliability of the solutions. ICA algorithms, however, do not readily offer any information on the reliability or stability of the solutions. Thus, understanding the causes of the variability and how to exploit it are essential for consistent analysis with ICA.
The sources of variability can be roughly categorized into three groups. First, theoretical assumptions behind the ICA algorithm may not fully hold (c.f., McKeown and Sejnowski, 1998). For example, the assumptions of strict statistical independence or absence of noise may limit the ability to converge to the true optimum, as explained earlier in Section 3.3.2. Second, the algorithm itself may be a source of variability as a result of the used optimization scheme. For example, initial conditions or adaptive iteration may affect the accuracy of estimating the independent components. Third, as the data partly defines the error-surface, it also affects the variability. The analysis of consistency may, therefore, reveal more about the properties of the data.
Additionally, the whitening, and possibly reducing the dimension, of the data is important. If the degrees of freedom is made too small, there may not be enough information to fully characterize the variability. On the other hand, if it is too high, the ICA algorithm is likely to overfit the data and cause severe variability, since on each application of ICA, the overfits can change freely.
This Chapter presents a method that exploits the inherent variability of the estimated independent components to acquire additional insight on the data. It is based on running ICA multiple times, in a controlled way, and then further analyzing the estimated components. Additionally, the results of the analysis are visualized to allow fast and easy interpretation, as explained Chapter 5.
To gather as much information on the variability as possible, ICA needs to be run multiple times. Naturally, a fast and efficient algorithm is required for keeping the analysis time meaningful. For example, the FastICA algorithm (FastICA, 1998) easily allows tens or even hundreds of runs to be used. The key is to adequately span the error-surface by randomizing the initial conditions and resampling the data on each run to allow the ICA algorithm to converge to different solutions. This should allow the identification of the consistent estimates and further analysis of the remaining variability.
Consider again the error-surface depicted in Figure 3.3. Randomizing the initial conditions makes the starting point and direction of optimization change on each run. This allows the ICA algorithm to consistently converge to the optimum solution by approaching it from different directions. Actually, some of the directions may allow a more optimal convergence than others and optimal points surrounded by local minima or noise may only be reached from certain directions.
Thus, by randomizing the initial conditions the method is able to exploit the variability to improve estimates and detect components, which are difficult to find. Also, it should allow to work around the limitations of the ICA algorithm to some extent, for example, under a high level of noise.
Resampling the data is often called bootstrapping (Meinecke et al., 2002) and the idea is, quite simply, to randomly resample the data with reposition on each pick. The point is that the resampling should not affect the global statistical properties of the data, but the error-surface, partly defined by the resampled data, would be slightly different on each run. The strong optimum point stays relatively stable, but the shape of local minima and noise on the surface can change freely. Thus, it allows the ICA algorithm to converge to different solutions and even reach solutions otherwise difficult to identify due to surrounding local minima or a high level of noise.
The idea is further illustrated in Figure 4.1 using a
2-dimensional error-surface, shown as thin curves. The data is resampled on
each run, causing the shape of the surface to change slightly, shown as thick
curves. This allows the algorithm to converge to different individual
solutions, marked as ``![]() ''. Some of the solutions can be around local
minima, but after running the algorithm many times most of the solutions are
near the true optimum. Therefore, the mean of all solutions gives the best
estimate of the true optimum.
''. Some of the solutions can be around local
minima, but after running the algorithm many times most of the solutions are
near the true optimum. Therefore, the mean of all solutions gives the best
estimate of the true optimum.
![\includegraphics[width=3.1cm]{images/bootstrap_a.eps}](thesis_img91.gif) (a) |
![\includegraphics[width=3.1cm]{images/bootstrap_b.eps}](thesis_img92.gif) (b) |
![\includegraphics[width=3.1cm]{images/bootstrap_c.eps}](thesis_img93.gif) (c) |
![\includegraphics[width=3.1cm]{images/bootstrap_d.eps}](thesis_img94.gif) (d) |
The solutions of multiple runs are reached along different paths on the error-surface, based on the initial conditions and the resampled data. In theory, when the same solution is reached in more than one run, the estimates would match perfectly. This is often not the case, but the estimates should still form consistent groups with high similarity. Thus, one may expect that the true solution can be found as a mean of the consistent group and that the spread of the group can be used to analyze the reliability of that solution. On the other hand, if the spread is too high, one expects the solution not to be reliable. The mean representatives of the groups can also depart somewhat from the strict assumption of independence, which may actually lead to a more natural decomposition of the data.
Early proposed bootstrapping of ICA use a standard initial run. Then, consecutive runs are made by resampling the estimated independent components from the initial run. The reason for this is that the solutions of the consecutive runs become only slightly altered versions of the already independent solution and comparing the solutions is easier, due to mixings being close to unity and permutations easier to handle. The biggest drawback, however, is that the initial run defines the set of independent components to be analyzed. Also, the variability is more restricted so the error-surface may not be spanned sufficiently and a poor solution on the initial run would render the consecutive runs useless.
On the other hand, when the resampling is done without an initial run (c.f., Duann et al., 2003) the total number of runs is often very small and comparing the solutions is done by hand. Furthermore, randomizing the initial conditions is sometimes neglected in bootstrapping approaches since some ICA implementations are not very sensitive to them.
The presented method does not use an initial run, allowing any permutation, and indeed, any combination of independent components to be found on each run. The benefits are that ICA has more freedom to find the optimal solution on each run and the solutions can include components that are very difficult to find with just a single run or other bootstrapping methods.
After multiple runs, the easiest way to describe the results of ICA, and maybe the only way due to memory constraints, is to use a concatenated version of the mixing matrixes:
Additionally, the size of the data matrix can be reduced by taking only a given percentage of samples during the resampling. This makes ICA considerably faster, allowing a clear increase in the number of runs used to analyze the consistency. The reduction of samples may eventually increase the variability somewhat, but with a properly selected amount of samples the overall quality of the method should increase due to the multiple runs. On the other hand, the reduction of samples also lowers the possibility of overfitting.
The reduction of samples is justified by the experiment shown in Figure 4.2. It shows how the variability is increased when the amount of samples is lowered. The amount of variability is measured as the mean difference of independent components between estimates using only a percentage of the samples and estimates using all of the samples. This is accomplished by running ICA 50 times with each percentage value and calculating a set of mean component estimates for each percentage. Then, the difference of the mean sets compared to the set using all of the samples is calculated using the Frobenius norm.
The horizontal axis shows the amount of samples used and the curves show the cumulative differences of 5 independent components, that is, the bottom curve is the mean difference of the first component, the second curve the cumulative difference of the two first components, and so on. Clearly, the amount of variability is very stable at higher percentages and starts to increase only at very low values. Therefore, the fraction of samples used can be quite small, for example, 20 percent, without significantly increasing the amount of variability.
![\includegraphics[width=\textwidth]{images/bootstrap_sample.eps}](thesis_img100.gif) |
Before the estimates from Equation 4.1 can be clustered and
the consistency of the solutions analyzed, the similarity of the estimates
must be measured. First the estimates are normalized to account for the
scaling ambiguities of ICA. One good way of doing this is to make the
estimates have zero mean and unit variance. If the normalized solutions are
defined as
![]() , with columns
, with columns
![]() , the
normalization equals:
, the
normalization equals:
Furthermore, if the binary correlation matrix
![]() shows that
estimate
shows that
estimate
![]() is related to
is related to
![]() , and that
, and that
![]() is to
is to
![]() , this is a strong
suggestion that
, this is a strong
suggestion that
![]() is also related to
is also related to
![]() through a longer path, even if
through a longer path, even if
![]() and
and
![]() exhibit a somewhat lower correlation. This allows
somewhat weaker and discontinuous paths also to be taken as estimates of a
common underlying source. To archive this, the binary correlation matrix can
be raised to a suitable power, whose value
exhibit a somewhat lower correlation. This allows
somewhat weaker and discontinuous paths also to be taken as estimates of a
common underlying source. To archive this, the binary correlation matrix can
be raised to a suitable power, whose value ![]() relates to the length of the
longest acceptable path:
relates to the length of the
longest acceptable path:
See Figure 4.3 for illustration of the different phases
of the correlation calculations. It shows the succession from absolute
correlation values
![]() through thresholded binary correlations
through thresholded binary correlations
![]() to relations
to relations
![]() after raising to a power.
Finally, the relations are shown in an order that makes the groups more
compact and easier to evaluate. The values are shown as grayscale images with
white being 0
and black
after raising to a power.
Finally, the relations are shown in an order that makes the groups more
compact and easier to evaluate. The values are shown as grayscale images with
white being 0
and black ![]() . In particular, note how raising the binary
correlations to a power makes the subsets in the data more visible.
. In particular, note how raising the binary
correlations to a power makes the subsets in the data more visible.
![\includegraphics[width=0.24\textwidth]{images/correlation_a.eps}](thesis_img115.gif) (a) |
![\includegraphics[width=0.24\textwidth]{images/correlation_b.eps}](thesis_img116.gif) (b) |
![\includegraphics[width=0.24\textwidth]{images/correlation_c.eps}](thesis_img117.gif) (c) |
![\includegraphics[width=0.24\textwidth]{images/correlation_d.eps}](thesis_img118.gif) (d) |
When the estimated components
![]() , their correlations
, their correlations
![]() , and their binary relations
, and their binary relations
![]() are available, the
components can be clustered into consistent groups. However, unlike other
methods (c.f., Himberg et al., 2004, Icasso, 2003) this is not
done using a general clustering method, such as hierarchical clustering or
k-means.
are available, the
components can be clustered into consistent groups. However, unlike other
methods (c.f., Himberg et al., 2004, Icasso, 2003) this is not
done using a general clustering method, such as hierarchical clustering or
k-means.
The problem with general clustering methods is that they are very time consuming and, in a way, overcomplete. The complete hierarchy, often shown as a dendrogram, may actually confuse more than help interpret the results. General methods may not perform well when using correlation as the distance measure. They are also often too discriminative against clusters, which do not form compact groups, such as subspaces or the longer paths of correlation. Additionally, they may require some parameters that are unknown and would need to be estimated, like the correct number of clusters needed in k-means.
Thus, the clustering is done with a method that is simpler and more suitable
for the situation. It does not need any additional parameters and is based on
the fact that each element ![]() of matrix
of matrix
![]() , and
, and ![]() of
of
![]() respectively, links two estimated components
respectively, links two estimated components
![]() and
and
![]() . The method works in two phases:
. The method works in two phases:
As explained before, when the estimated components have been grouped, the consistent components can be identified using the variability within the groups. The mean of each group can be calculated as the best estimate of the true decomposition. The spread of the grouped estimates around the mean reveals the magnitude and shape of the variability. Moreover, additional properties of the groups can be calculated to help human interpretation. For example, measures of compactness and discrimination of the groups can be very helpful, since they can provide clues to the nature of the variability. Some of the properties can be used to rank the components and sort them accordingly. With a good ranking, the human interpretation becomes faster, since the most interesting components appear first, and similar phenomena can be shown close to each other.
Naturally, the difficulty is how to define a ranking that favors the
interesting components. In discriminant analysis, the ratio between the
distance to other groups and the size of a group, in the Euclidean sense, is
often used. However, the number of estimates in each group can be very
different, offering evidence of the relevance of the group. Therefore, such a
rank should be weighted with the number of estimates in each group. For
example, when two groups are equally well discriminated, the one containing
more estimates should be considered more consistent. Additionally, as the rank
is a simple value, it should be made more robust to outliers by using the
geometric mean when calculating the Euclidean distance ratios. One way of
ranking that performs sufficiently well, can be defined, for group ![]() as:
as:
The most reliable, that is, the most consistent and well discriminated, components are often the most interesting. However, there may be some exceptions, for example, components that are very difficult to find. Being able to more truly define what makes a component interesting would allow a very useful ranking indeed. Recently, in the field of biomedical signal processing, some quantitative methods to analyze the nature of signals have been developed. Some of them (c.f., Gautama et al., 2004) try to classify the nature of a signal based on how linear the signal is or whether it is deterministic or stochastic. Others (c.f., Formisano et al., 2002) use entropy to measure how structured and, therefore, interesting the signal is. It may be possible to construct a ranking by using such methods also on the temporal activation patterns of the components.
After the estimates have been grouped, and the additional properties calculated, the components can be interpreted reliably. Since the information is multi-modal and its amount can be quite overwhelming, human interpretation requires it to be shown in a clear and easy to understand form. This is, by all means, not trivial and the visualization is explained separately in Chapter 5.
As shown in previous work (Ylipaavalniemi and Vigário, 2004), the nature of the variability can be very different in each component and provides important additional information. The spread of a group around the mean time-course can be almost constant at all time points or it be very structured. For example, it can follow the time-course very closely or be related to the time-course of another component or the stimulation pattern. Additionally, there can be single time points with very high variability, even when the main portion would be consistent. The nature of the variability, combined with the measures of discrimination, can be used to easily detect artifacts or characterize other phenomena. Many examples are shown in Chapter 7.
Considering the whole independent volumes can also be beneficial, although more time consuming, since similar interpretations can be based on the spatial variability. In particular, localized features may be easier to interpret in the spatial sense. Moreover, the regions with strong variability could be masked out of the data relatively easily by leaving those voxels out of the analysis. This should improve the estimation of the independent components based of the remaining data.
Instead of completely discarding, as in masking out, the regions with high variability, those areas could be analyzed using different methods. For example, methods not based on statistical independence may be able to reveal properties that ICA is not able to decompose. The recently introduced framework of denoising source separation (DSS) (Särelä and Valpola, 2005) uses denoising functions to identify the signal decomposition. Such functions can be defined as weighting masks and the spatial maps of strong variability could be used to build them. Additionally, the DSS estimation does not have to be based strictly on statistical independence.