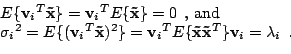Principal component analysis (PCA) is a powerful statistical method for multivariate data analysis. It is very efficient and simple to use for noise reduction, feature selection, compression, decorrelation and whitening. It is frequently used in practically all signal processing. Consider reading Jolliffe (2002), Haykin (1998) for more information on principal component analysis and algorithmic implementations.
The eigenvalues ![]() and corresponding eigenvectors
and corresponding eigenvectors
![]() of an
of an
![]() square matrix
square matrix
![]() are defined as the solutions of:
are defined as the solutions of:
The principal components of multivariate data
![]() are defined
as the orthonormal basis vectors, which contain the maximum variance of the
data. Each row of the data matrix
are defined
as the orthonormal basis vectors, which contain the maximum variance of the
data. Each row of the data matrix
![]() contains a different
observation with samples on the columns. One way of finding the principal
components is to use the EVD of the estimated covariance matrix of the data.
First of all, the covariance matrix
contains a different
observation with samples on the columns. One way of finding the principal
components is to use the EVD of the estimated covariance matrix of the data.
First of all, the covariance matrix
![]() , where
, where
![]() is
a column of
is
a column of
![]() and the expectation function
and the expectation function
![]() simply normalizes the values, is a real symmetric matrix. Therefore, the
following must hold for the EVD of a covariance matrix:
simply normalizes the values, is a real symmetric matrix. Therefore, the
following must hold for the EVD of a covariance matrix:
Clearly, this is only possible when
![]() , thus the
eigenvectors must be orthogonal. Additionally, assuming the data has zero mean
and the eigenvectors are normalized, that is,
, thus the
eigenvectors must be orthogonal. Additionally, assuming the data has zero mean
and the eigenvectors are normalized, that is,
![]() and
and
![]() , the following holds for the data projected along a
principal direction
, the following holds for the data projected along a
principal direction
![]() :
:
Thus, the eigenvalues corresponding to the orthonormal eigenvectors equal the variances of the data projected along the eigenvector directions. Therefore, decomposing the covariance matrix with EVD gives the principal components of the data. The usual convention is to make the one with the largest eigenvalue, or variance, the first principal component and so on.
Whitening observed data
![]() , that is, making the rows
uncorrelated and their variances equal to unity, often makes further
processing easier. Whitening can be expressed as a linear transformation
and one way to find such a transformation is based on the EVD of the estimated
covariance matrix of the data. Again, assuming the data has zero mean, this
equals:
, that is, making the rows
uncorrelated and their variances equal to unity, often makes further
processing easier. Whitening can be expressed as a linear transformation
and one way to find such a transformation is based on the EVD of the estimated
covariance matrix of the data. Again, assuming the data has zero mean, this
equals:
The following whitening transformation can be constructed from the eigenvalues and eigenvectors of the decomposition:
What makes this transformed model useful is that the new mixing matrix
![]() is orthonormal, which reduces the number of free parameters. This
is evident from:
is orthonormal, which reduces the number of free parameters. This
is evident from:
Additionally, using the EVD of the covariance matrix to form the whitening
transformation allows the reduction of free parameters also in another way. By
selecting only a subset ![]() of the eigenvalues, and corresponding
eigenvectors for the transformation, the dimension of the whitened data can be
lowered effectively. The dimension reduction also reduces noise, that is,
improves the signal-to-noise ratio. Additive noise, for example Gaussian,
often appears distributed along several directions with a small energy. If the
selected eigenvalues are the largest ones, which identify the directions with
the highest variances, the dimension reduction is optimal in the sense that it
retains as much of the original signal power as possible.
of the eigenvalues, and corresponding
eigenvectors for the transformation, the dimension of the whitened data can be
lowered effectively. The dimension reduction also reduces noise, that is,
improves the signal-to-noise ratio. Additive noise, for example Gaussian,
often appears distributed along several directions with a small energy. If the
selected eigenvalues are the largest ones, which identify the directions with
the highest variances, the dimension reduction is optimal in the sense that it
retains as much of the original signal power as possible.
The orthogonal principal components identified with PCA and, therefore, also the whitened data vectors are uncorrelated, which means that their covariance is zero:
Uncorrelated vectors are sometimes, confusingly, called linearly independent.
However, true statistical independence means that the joint probability
density function (pdf)
![]() is factorisable on its marginal
probability densities as:
is factorisable on its marginal
probability densities as:
This means that the marginal distributions contain no information on each
other whatsoever. It also means that statistical independence is a stronger
restriction than uncorrelation, since the following holds for arbitrary
functions
![]() and
and
![]() :
:
Additionally, as directly seen from Equations A.9 and A.11, independence implies uncorrelation. This is actually the reason why whitening the data before ICA will not alter the independent components. The following introduces the key concepts in approximating statistical independence, but for more information consider reading Cardoso (2003), Hyvärinen and Oja (2000).
Since a closed form solution would require exact determination of the pdfs,
which is generally not possible, the independence has to be approximated. A
good starting point is the entropy ![]() of a discrete random variable
of a discrete random variable
![]() , defined as:
, defined as:
Mutual information measures how much information is shared among random
variables. The mutual information ![]() between
between ![]() random variables is defined
using entropy as:
random variables is defined
using entropy as:
Clearly, mutual information between independent variables should be 0. Thus, estimating the independent components is possible by minimizing the mutual information between them. However, doing this in practice can be computationally very heavy.
Gaussian variables have the largest entropy among all random variables of
equal variance. Negentropy ![]() is defined as:
is defined as:
Therefore, maximizing negentropy equals minimizing mutual information when estimating independence. Although negentropy is computationally simpler than mutual information, it is also based on the exact pdfs. To make the estimation feasible in practice, the requirement of knowing the exact pdfs should be eliminated. Fortunately, it turns out that negentropy can be approximated without knowing the exact pdfs.
Since negentropy is essentially measuring the difference between the Gaussian
distribution and that of the independent variables, it can be approximated by
estimating the non-Gaussianity of the random variables directly. Classical
measures of non-Gaussianity are skewness and kurtosis, or the third and fourth
order cumulants. The kurtosis of ![]() is defined as:
is defined as:
Actually, as ![]() is assumed to have unit variance, this simplifies to
is assumed to have unit variance, this simplifies to
![]() . Kurtosis is zero for a Gaussian random variable, negative for
sub-Gaussian and positive for super-Gaussian. Thus, the absolute value of
kurtosis can be used as a measure of non-Gaussianity. Maximizing the norm of
kurtosis, which is roughly equivalent to maximizing independence, is
computationally very efficient, making ICA feasible in practice.
. Kurtosis is zero for a Gaussian random variable, negative for
sub-Gaussian and positive for super-Gaussian. Thus, the absolute value of
kurtosis can be used as a measure of non-Gaussianity. Maximizing the norm of
kurtosis, which is roughly equivalent to maximizing independence, is
computationally very efficient, making ICA feasible in practice.
A very precise estimation of non-Gaussianity can be constructed as a weighted sum of both skewness and kurtosis, but it is often decided to use only one of them in practice. The possibility of using non-Gaussianity as a measure of independence is not so surprising when considering the central limit theorem. Basically, it states that the distribution of a mixture of i.i.d. random variables tends to be more Gaussian than the original ones. Therefore, the more non-Gaussian a variable is the more independent it has to be. Incidentally, this link between independence and non-Gaussianity is the reason why only one of the components in ICA can originally be Gaussian.
One of the most widely used implementations of ICA is called FastICA. It uses a Newton-iteration based fixed-point optimization scheme and an objective function based on negentropy. FastICA can search for the independent components one at a time, in deflation mode, or symmetrically, all at once. Its performance can also be tuned somewhat by choosing the nonlinearity used in the estimation, for example between the cubic or the tanh. For more information on the FastICA algorithm, and its derivation, consider reading Hyvärinen and Oja (1997,2000). For the actual implementation see FastICA, (1998).
The independent components are estimated one by one and the iteration simply
prevents the estimation of the ![]() th component from converging to the same
solution as any of the previous
th component from converging to the same
solution as any of the previous
![]() components. The basic FastICA
iteration takes the following form in deflation mode:
components. The basic FastICA
iteration takes the following form in deflation mode:
Since the signs of the independent components are not fixed, convergence means
that the old and new values of
![]() are parallel. The function
are parallel. The function
![]() , and its derivative
, and its derivative ![]() , in step 2. is the selectable
nonlinearity and using the cubic actually corresponds to estimating the
kurtosis.
, in step 2. is the selectable
nonlinearity and using the cubic actually corresponds to estimating the
kurtosis.
In deflation mode, the previously estimated components are priviledged in step
3., that is, only the currently estimated weight vector is affected, and the
estimation order matters. For example, estimation error accumulates into the
last components. In symmetric mode, the order in which the components are
estimated has no effect. This is archieved by estimating all the
![]() ,
that is, the whole matrix
,
that is, the whole matrix
![]() , first and orthogonalizing the matrix
only after that as an additional step.
, first and orthogonalizing the matrix
only after that as an additional step.