|
 Geneettist‰ algoritmia sovellettaessa ongelman ratkaiseva ohjelma sunnitellaan
moduleiksi siten ett‰ modulit ovat valinnaisia. Moduleja edustava perim‰
toteutetaan useimmiten laskennallisen hallittavuuden vuoksi bin‰‰ritaulukkona,
jossa 1 edustaa ominaisuutta ja 0 sen puutetta. Laajoissa ohjelmistoissa perim‰
voidaan kuvata tuhansien, jopa kymmenien tuhansien alkioiden taulukolla. Geneettist‰ algoritmia sovellettaessa ongelman ratkaiseva ohjelma sunnitellaan
moduleiksi siten ett‰ modulit ovat valinnaisia. Moduleja edustava perim‰
toteutetaan useimmiten laskennallisen hallittavuuden vuoksi bin‰‰ritaulukkona,
jossa 1 edustaa ominaisuutta ja 0 sen puutetta. Laajoissa ohjelmistoissa perim‰
voidaan kuvata tuhansien, jopa kymmenien tuhansien alkioiden taulukolla.
Taulukon sis‰ltˆ‰ muokkaamalla saadaan ohjelman k‰ytt‰ytyminen muuttumaan.
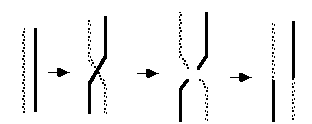
Ohjelmasta toteutetaan useita kilpailevia versioita ja versioita edustavia
taulukoita monistetaan, risteytet‰‰n ja mutatoidaan yksisoluisia j‰ljittelev‰ll‰
tavalla. Ohjelmaversioista karsitaan niiden k‰ytt‰ytymisen perusteella heikoimmat
ja risteytet‰‰n kelpuutetut uudeksi sukupolveksi. Riitt‰v‰ sukupolvien m‰‰r‰
tuottaa optimaalisen ratkaisun, mutaatioita tarvitaan vain riitt‰v‰n versioinnin
yll‰pit‰miseksi.
Olen esityksess‰ni pit‰ytynyt yksikkˆmuodossa geneettinen algoritmi, tarkoittaen
alla olevaa pseudokielist‰ yleistyst‰. Alan kirjoituksissa termill‰ tarkoitetaan
toisinaan myˆs optimoinnin kohteena olevia yksitt‰isi‰ sovellus- ja jopa
ratkaisuversioita t‰ss‰ kuvattavan yleisen mallin lis‰ksi.
- muotoile ongelma
- kehit‰ karkea ratkaisurakenteiden populaatio
- versioi ja risteyt‰ rakenteet
- evaluoi rakenteet
- karsi rakenteet
- jatka rivilt‰ 3. ellei mik‰‰n ratkaisu tyydyt‰
Ongelman muotoilu edellytt‰‰ ratkaisun erittely‰ silt‰ edellytett‰vien
ominaisuuksien mukaan, niin ett‰ ratkaisun tuottava rakenne voidaan kuvata
perim‰ll‰. Alkupopulaatio voidaan tuottaa mutatoimalla ja monistamalla
alkuratkaisua.
Yleinen malli
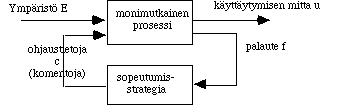
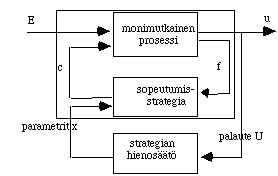
Yleisell‰ tasolla geneettisen algoritmin (GA) hakuavaruuden laajuutta voidaan
tarkastella kutsussa GA(N,C,M,G,W,S) olevien kuuden parametrin avulla (Holland).
Parametreista N edustaa populaation yksilˆiden m‰‰r‰‰ eli kokoa. C ilmaisee
risteytyksien suhteellista osuutta, kustakin sukupolvesta risteytet‰‰n C*N
yksilˆ‰. C kuten M ja G voi saada arvoja v‰lilt‰ 0.0-1.0. M m‰‰ritt‰‰
mutaatioiden esiintymistiheyden, joka saadaan tulosta M*N*L, miss‰ L edustaa
perim‰n sis‰lt‰mien geenien m‰‰r‰‰. Pieni mutaatioiden osuus varmistaa, ettei
haku juutu paikallisiin optimeihin - suurella mutaatioiden m‰‰r‰ll‰ voidaan
h‰vitt‰‰ jo lˆytynyt ratkaisu. G m‰‰ritt‰‰ seuraavaan sukupolveen selviytyvien
osuuden N*(1-G). W s‰‰telee valintafunktion skaalausta, ts. sill‰ m‰‰ritell‰‰n se
valintafunktion arvo, joka m‰‰r‰‰ karsinnan nollapisteen: Jos esimerkiksi
yksilˆihin liitetyt painokertoimet voivat saada arvoja v‰lill‰ 0 - 130, niin
ensimm‰isess‰ sukupolvessa ratkaisujen saamien painokertoimien hajonta on
laajempi kuin satojen sukupolvien j‰lkeen - kuitenkin populaatioon sovellettavan
karsinnan on tarkasteltava kutakin sukupolvea tasa-arvoisesti. S parametrill‰
s‰‰dell‰‰n sit‰ pyrit‰‰nkˆ kunkin sukupolven parhaiden ratkaisujen perim‰
kopioimaan vai voidaanko se jopa kadottaa risteytt‰m‰ll‰. Edellinen nopeuttaa
optimaalisen ratkaisun lˆytymist‰, j‰lkimm‰inen est‰‰ juuttumisen paikallisiin
optimeihin.
Strategiasta riippuen algoritmin sovellukset voidaan jakaa kahteen p‰‰luokkaan,
sen mukaan mit‰ perim‰n avulla kuvataan. P‰‰suuntauksia kutsutaan Pittin esim.
(De Jong) ja Michiganin (Holland) versioiksi sen mukaan liitet‰‰nkˆ yksitt‰iseen
geeniin kokonaisia proseduureja vai ohjelmalauseita.
Sovellusesimerkki
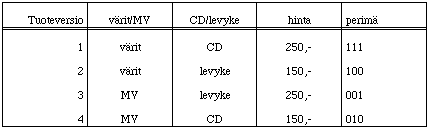
K‰yt‰n esimerkkin‰ yksinkertaistettua optimointiongelmaa - hypermediadokumentin
julkaisumuodon ja ilmiasun valintaa. Teht‰v‰n‰ on suunnitella geneettist‰
algoritmia k‰sittelev‰ vuorovaikutteinen hypermediadokumentti. Ensiksi on
p‰‰tett‰v‰ k‰ytet‰‰nkˆ dokumentissa 256 v‰ri‰ vai mustavalkoisuutta,
hinnoitellaanko/tuotetaanko nimike materiaaliltaan 150,- vai 250,- markan
hintaiseksi ja julkaistaanko se CD-ROMina vai levykkein‰. On siis lˆydett‰v‰
tasapaino tuotteen hyv‰ksytt‰vyyden/jaeltavuuden, tuotantoon panostettavien
resurssien ja arvioitavan tuoton suhteen.
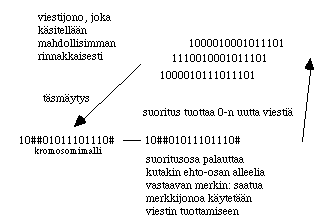
Muotoilen aluksi ratkaisulle esitysmallin (representation scheme): iImaistaan
kolmea vaihtoehtoista edell‰ kuvattua valintaa kaksiaakkosisella {0,1}
merkkijonolla, edustakoon se suunnittelustrategian perim‰‰. Aakkoston koko K on
siis 2 ja perim‰n pituus (sen geenien lukum‰‰r‰) L on 3, ja n‰in
strategiavaihtoehtoja on 8, K potenssiin L.
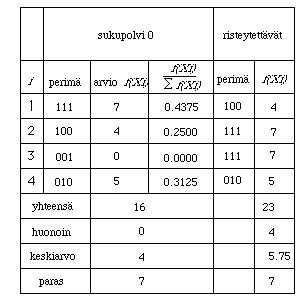
Koska tarkoituksena on perustaa yrityksen toiminta vuorovaikutteisten
tietokonedokumenttien tuotannolle ja yrityksen n‰kˆkulmasta on t‰rke‰t‰ saavuttaa
kokemusta eri versioiden toteutukseen liittyvist‰ ongelmista niin p‰‰tet‰‰n
aluksi kokeilla tuotteitten myynti‰ nelj‰n vaihtoehtoisen version avulla ja
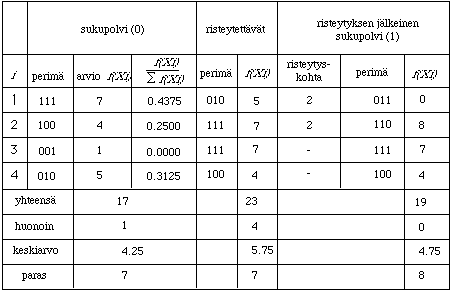
tarkkailla niiden myynti‰. Tilannetta voidaan tarkastella esimerkiksi seuraavan
mallin avulla.
|