|
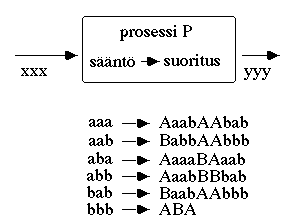
 Ohjelman muodostava sððnn—st— koostuu kðsiteltðvistð sððnt—-suoritus pareista
(kuva 4), mahdolliset sððnt—osat voidaan kuvata ne mððrittðvðn aakkoston ja
kieliopin avulla. Aakkoston lisðksi usein kðytetððn erityistð hðllðvðlið -merkkið
(don't care), esim. #, jonka avulla sððnt—jð voidaan ryhmitellð luokiksi.
Suoritusosa tuottaa uusia sððnt—jð ja pððttyvið toimintoja (A, B, kuvassa 4).
Kuvan prosessia voisi ajatella esimerkiksi jonkin Prologin tai Lispin
epðmððrðisen murteen toteuttavana tulkkina. Ohjelman muodostava sððnn—st— koostuu kðsiteltðvistð sððnt—-suoritus pareista
(kuva 4), mahdolliset sððnt—osat voidaan kuvata ne mððrittðvðn aakkoston ja
kieliopin avulla. Aakkoston lisðksi usein kðytetððn erityistð hðllðvðlið -merkkið
(don't care), esim. #, jonka avulla sððnt—jð voidaan ryhmitellð luokiksi.
Suoritusosa tuottaa uusia sððnt—jð ja pððttyvið toimintoja (A, B, kuvassa 4).
Kuvan prosessia voisi ajatella esimerkiksi jonkin Prologin tai Lispin
epðmððrðisen murteen toteuttavana tulkkina.
Jos sððnn—t kattavat kaikki mahdolliset jðrjestelmðn saamat sy—tteet,
sððnt—jen sanotaan olevan sy—tejoukon suhteen laskennallisesti tðydellisið. Saman
sy—tejoukon suhteen laskennallisesti tðydelliset jðrjestelmðt ovat yhtð
ilmaisuvoimaisia, mikð tðssð yhteydessð tarkoittaa sitð, ettð proseduraalisesti
toteutetut algoritmit voidaan ilmaista my—s sððnt—joukon avulla.
Jonkinlaisen kðsityksen sððnt—jðrjestelmien mahdollisuuksista antaa laajalti
rikollisten tunnistuksessa kðytetty tunnistusohjelma, jossa kymmenen hiusrajaa,
kymmenen silmðparia, kymmenen nenðð, kymmenen suuta ja kymmenen leukaa
yhdistetððn viidellðkymmenellð perussððnn—llð niin, ettð ne tuottavat kaikki
kuvapankin satatuhatta erilaista kasvoa.
Sððnt—jen oikean puolen suorittaminen voi laukaista uusia sððnt—jð, joiden
sivuvaikutukset suorittavat ohjelmalle mððritellyn tehtðvðn. Ohjelman suoritus
pððttyy sððnt—ihin, jotka eivðt aktivoi uusia sððnt—jð. Jos sððnt—ihin sidotaan
muistia, niiden kðyttðytymistð voidaan tarkkailla ja jopa muokata ajoaikaisesti.
Sððnt—jen muistia kðytetððn, kun halutaan liittðð sððnt—ihin niitð arvottavia
painokertoimia esim. suorituskertojen mukaan.
Kun sððnn—t toteutetaan suoritusaikaisesti toisistaan riippumattomiksi,
voidaan niitð tarvittaessa hajauttaa rinnakkaisprosessorijðrjestelmien
suoritettavaksi. Riippumattomat sððnn—t tukevat my—s geneettiseen algoritmiin
sisðltyvðð monikerroksista rinnakkaisuutta - niin yksil—n perimðð kuin sukupolvea
joukkoina kðsittelevissð operaatioissa.
|