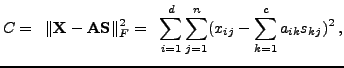Assume that we have ![]()
![]() -dimensional data vectors
-dimensional data vectors
![]() , which form the
, which form the ![]() data matrix
data matrix
![]() =
=
![]() . The matrix
. The matrix
![]() is decomposed into
is decomposed into
Without any further constraints, there exist infinitely many ways to perform
such a decomposition. However, the subspace spanned by the column vectors of
the matrix
![]() , called the principal subspace, is unique.
In PCA, these vectors are mutually orthogonal and have unit length.
Further, for each
, called the principal subspace, is unique.
In PCA, these vectors are mutually orthogonal and have unit length.
Further, for each
![]() , the first
, the first ![]() vectors form the
vectors form the ![]() -dimensional
principal subspace. This makes the solution practically
unique, see [4,2,5] for details.
-dimensional
principal subspace. This makes the solution practically
unique, see [4,2,5] for details.
There are many ways to determine the principal subspace and components [6,4,2]. We will discuss three common methods that can be adapted for the case of missing values.