Growing amount of data is collected every day in all fields of life. For the purpose of automatic analysis, prediction, denoising, classification etc. of data, a huge number of models have been created. It is natural that a specific model for a specific purpose works often the best, but still, a general method to handle any kind of data would be very useful. For instance, if an artificial brain has a large number of completely separate modules for different tasks, the interaction between the modules becomes difficult. Probabilistic modelling provides a well-grounded framework for data analysis. This paper describes a probabilistic model that can handle data with relations as well as discrete and continuous values with nonlinear dependencies.
Terminology:
Using Prolog notation, we write
![]() for stating a fact that the
for stating a fact that the
![]() relation holds between the objects
relation holds between the objects
![]() and
and
![]() , that is, Alex
knows Bob. The arity of the relation tells how many objects are
involved. The
, that is, Alex
knows Bob. The arity of the relation tells how many objects are
involved. The
![]() relation is binary, that is, between two
objects, but in general relations can be of any arity. The atom
relation is binary, that is, between two
objects, but in general relations can be of any arity. The atom
![]() matches all the instances where the variable
matches all the instances where the variable ![]() represents an object known by Alex. In this paper, the terms are
restricted to constants and variables, that is, compound terms such as
represents an object known by Alex. In this paper, the terms are
restricted to constants and variables, that is, compound terms such as
![]() are not considered.
For every relation that is logically true, there are associated
attributes
are not considered.
For every relation that is logically true, there are associated
attributes
![]() , say a class label or a vector of real numbers. The
attributes
, say a class label or a vector of real numbers. The
attributes
![]() describe how well
describe how well ![]() knows
knows ![]() and
whether
and
whether ![]() likes or dislikes
likes or dislikes ![]() . The attribute vector
. The attribute vector
![]() describes what kind of a consumer the person
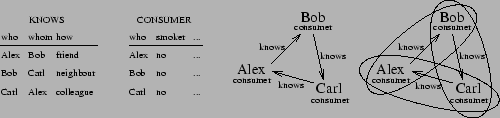
describes what kind of a consumer the person ![]() is. Given a relational database describing relationships between
people and their consuming habits, we might study the dependencies
that might be found. For instance, some people cloth like their idols,
and nonsmokers tend to be friends with nonsmokers. The modelling can
be done for instance by finding all occurrences of the template
is. Given a relational database describing relationships between
people and their consuming habits, we might study the dependencies
that might be found. For instance, some people cloth like their idols,
and nonsmokers tend to be friends with nonsmokers. The modelling can
be done for instance by finding all occurrences of the template
![]() in the data and studying
the distribution of the corresponding attributes. The situation is
depicted in Figure 1.
in the data and studying
the distribution of the corresponding attributes. The situation is
depicted in Figure 1.
 |
Bayesian networks[6] are popular statistical models based on a directed graph.
The graph has to be acyclic, which is in line with
the idea that the arrows represent causality: an occurrence cannot be its own cause.
In relational generalisations of Bayesian networks [7], the graphical structure is determined by the data. Often it can be assumed that the
data does not contain cycles, for instance in the case when the direction of the arrows is always
from the past to the future.
Sometimes the data has cycles, like in Figure 1.
Markov networks [6], on the other hand, are based on undirected graphical models.
A Markov network does not care whether ![]() caused
caused ![]() or vice versa, it is interested only whether
there is a dependency or not.
or vice versa, it is interested only whether
there is a dependency or not.