A traditional way is to estimate a parametric density function (often a Gaussian) for each state [Baker, 1975,Jelinek, 1976]. Because a simple function is clearly insufficient to represent the density of, for example, a phoneme, the model has been extended to a linear combination of PDFs for (16) [Liporace, 1982,Juang, 1985]
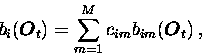 |
(19) |
Another traditional way is to use vector quantization (VQ) [Makhoul et al., 1985] to transform the features into a set of output symbols and then estimate their discrete probability distribution in each state [Rabiner et al., 1983].
By combining the gains of the continuous and discrete models, good results have been obtained by a class of methods called semi-continuous HMMs (SCHMMs) [Huang and Jack, 1989,Paul, 1989,Bellegarda and Nahamoo, 1990] and multi-codebook vector quantization HMMs [Segura et al., 1994,Peinado et al., 1994]. In SCHMMs a single set of Gaussians is shared between all states of all HMMs so that it is not necessary to train individual sets of Gaussians for each state. By forming a large set of Gaussians, which can be regarded actually as a codebook of Gaussian densities, the number of the mixtures used for each state can be much larger without increasing the total number of parameters to be estimated. Also the covariance matrices are often shared between the Gaussians as a trade-off to be able to increase the size of the codebook. In practice, SCHMMs are easier to train than CDHMMs, because the training of the codebook can be separated from the segmentation and even be trained mostly with unlabeled data (e.g., see Publication 1).
The SCHMMs offer an extension to the discrete observation HMMs, since it enhances the VQ performance by smoothing the quantization effects with weighted average of the probabilities given by several nearest units instead of only the BMU. The weights are inversely proportional to the distance of the units. This weighting leads actually to density model family known as the kernel density estimators or Parzen estimators [Parzen, 1962] with suitably chosen kernel functions. In the broad sense, as applied in this work, all the SCHMMs and CDHMMs, where the density model consists of a finite set of weighted multivariate unimodal kernel functions, belong to the mixture density HMMs (MDHMMs).
An illustration of a MDHMM and its parameters is shown in Figure 1. The temporal structure for this phoneme model is a typical simple uni-directional chain without skips.
![\begin{figure}
\centerline{
\renewcommand {
\setlength
}[2]{ ...](img68.gif) |
Publication 3 as several other recent studies, e.g. [Young and Woodland, 1994,Digalakis et al., 1996], suggest to improve the performance of SCHMMs by tying some parameters for several similar states. The problem in practice is that the finite training data cannot provide reliable weights for the whole Gaussian codebook for every HMM state. For large vocabulary recognition tasks the tying of parameters is often crucial for developing a required amount of context dependent phoneme models. A common choice for tying mixtures is to have a separate Gaussian codebook for each HMM, which can then be called as a phoneme-wise tied MDHMMs. In Publication 3 there is a brief comparison of different HMM classes.