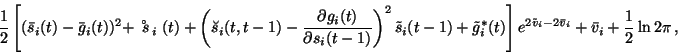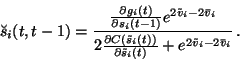The feedforward computations start with the parameters of the
posterior approximation of the unknown variables of the model. For
the factors, the parameters of the posterior approximation are the
posterior mean
![]() ,
the posterior variance
,
the posterior variance
![]() and the dependence
and the dependence
![]() .
The end result of the
feedforward computations is the value of the cost function C.
.
The end result of the
feedforward computations is the value of the cost function C.
The first stage of the computations is the iteration of
(8) to obtain the marginalised posterior mean
![]() and variance
and variance
![]() of the factors. Thereafter
the computations proceed like in the NLFA algorithm: the means and
variances are propagated through the MLP networks. The final stage,
the computation of the cost function, differs only in the terms
of the factors. Thereafter
the computations proceed like in the NLFA algorithm: the means and
variances are propagated through the MLP networks. The final stage,
the computation of the cost function, differs only in the terms
![]() and
and
![]() .
In the NLFA algorithm, the former
had the form
.
In the NLFA algorithm, the former
had the form
| (9) |
In the feedbackward phase, the gradient of the cost function Cw.r.t. the parameters of the posterior approximation is computed by the back-propagation algorithm, that is, the steps of the feedforward computations are reversed and the gradient of the cost function is propagated backwards to the parameters of the posterior approximation. Since the essential modification to the feedforward phase of NLFA algorithm is (8), this is also the essential modification in the backward computations.
The cost function is a function of parameters of the posterior
approximation. In the computation of the cost function, the
marginalised posterior variances
![]() of the factors are used
as intermediate variables and hence the gradient is also computed
through these variables. Let us use the notation
of the factors are used
as intermediate variables and hence the gradient is also computed
through these variables. Let us use the notation
![]() to
mean that C is considered to be a function of the intermediate
variables
to
mean that C is considered to be a function of the intermediate
variables
![]() ,
,
![]() ,
,
![]() in addition to the
parameters of the posterior approximation. The gradient computations
resulting from (8) by the chain rule are then as
follows:
in addition to the
parameters of the posterior approximation. The gradient computations
resulting from (8) by the chain rule are then as
follows:
| (12) |
| (13) |
In the adaptation, the posterior means
![]() of the factors
are treated as in the NLFA algorithm except for the correction in the
step size which is discussed in section 3.3. The
variances
of the factors
are treated as in the NLFA algorithm except for the correction in the
step size which is discussed in section 3.3. The
variances
![]() are adapted like
are adapted like
![]() in the NLFA.
The posterior dependence
in the NLFA.
The posterior dependence
![]() is adapted by solving
is adapted by solving
![]() which yields
which yields