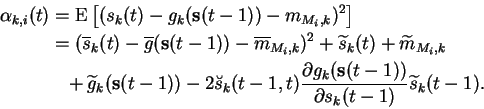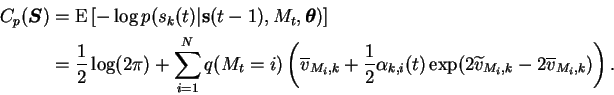The switching model is a combination of the two models as shown in
Section 5.3. Therefore most of the terms of
the cost function are exactly as they were in the individual models.
The only difference is in the term
![]() . The term
. The term
![]() in Equation (6.31)
changes to
in Equation (6.31)
changes to
![]() for the case
for the case ![]() and has the value
and has the value
With this result the expectation of Equation (6.33) involving the source prior becomes
The update rules will mostly stay the same except that the values of
the parameters of ![]() must be replaced with properly weighted
averages of the corresponding parameters of
must be replaced with properly weighted
averages of the corresponding parameters of ![]() . The HMM
prototype vectors will be taught using
. The HMM
prototype vectors will be taught using
![]() as
the data.
as
the data.