



The term
![]() is just a sum over the discrete distribution. It
can be further simplified into
is just a sum over the discrete distribution. It
can be further simplified into
The other term,
![]() can be split down to
can be split down to
The above equations give the value of the cost function for given
approximating distribution
![]() . This value is important
because it can be used to compare different models as shown in
Section 3.3. Additionally it can be used to
monitor whether the iterative optimisation procedure has converged.
. This value is important
because it can be used to compare different models as shown in
Section 3.3. Additionally it can be used to
monitor whether the iterative optimisation procedure has converged.
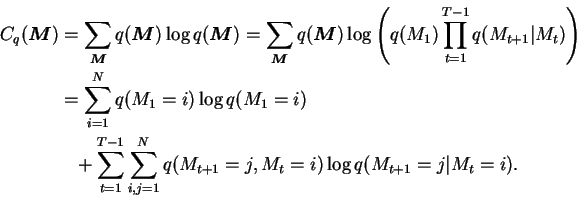
![\begin{displaymath}\begin{split}C_p(\boldsymbol{M}) &= \operatorname{E}\left[ - ...
...N q(M_{t+1}=j, M_{t}=i) E\left[ \log a_{ij} \right] \end{split}\end{displaymath}](img378.gif)