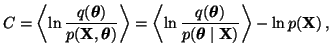This section gives a brief overview of ensemble learning with emphasis on solutions yielding linear computational complexity. Thorough introductions to ensemble learning can be found for instance in [13,14].
Ensemble learning is a method for approximating posterior probability
distributions. It enables to choose a posterior approximation ranging
from point estimates to exact posterior. The misfit of the
approximation is measured by the Kullback-Leibler divergence between
the posterior and its approximation. Let us denote the observed
variables by
![]() , the latent variables (parameters) of the
model by
, the latent variables (parameters) of the
model by
![]() and the approximation of the true posterior
and the approximation of the true posterior
![]() by
by
![]() . The cost function
. The cost function ![]() used
in ensemble learning is
used
in ensemble learning is