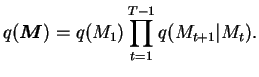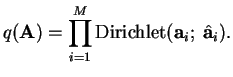The approximating posterior distribution needed in ensemble learning
is over all the possible hidden state sequences
![]() and the
parameter values
and the
parameter values
![]() . The approximation is chosen to be of a
factorial form
. The approximation is chosen to be of a
factorial form
The approximation
![]() is a discrete distribution and it factorises
as
is a discrete distribution and it factorises
as
The distribution
![]() is also formed as a product of
independent distribution for different parameters. The parameters
with Dirichlet priors have posterior approximations of a single
Dirichlet distribution like for
is also formed as a product of
independent distribution for different parameters. The parameters
with Dirichlet priors have posterior approximations of a single
Dirichlet distribution like for
![]()
These will actually be the optimal choices among all possible
distributions, assuming the factorisation
![]() .
.
The parameters with Gaussian priors have Gaussian posterior approximations of the form