Proceedings of STeP'96. Jarmo Alander, Timo Honkela and Matti Jakobsson (eds.),
Publications of the Finnish Artificial Intelligence Society, pp. 73-78.
WEBSOM - A Status Report
Krista Lagus, Timo Honkela, Samuel Kaski, and Teuvo Kohonen
Neural Networks Research Centre
Helsinki University of Technology
Rakentajanaukio 2C, 02150 Espoo, Finland
Krista.Lagus@hut.fi
WEBSOM is a full-text information retrieval and exploration
method for large document collections.
Self-Organizing Map (SOM) is used to statistically
analyse relations between the words, and then, based
on this analysis, to create a document map.
Similar documents become positioned close to
each other on the document map.
Therefore, this document landscape provides
a good basis for search and exploration.
A demonstration of the WEBSOM system
is also available.
Searching for relevant documents from a very large
collection has traditionally been based on keywords and their Boolean
expressions. Often, however,
the search results show high recall and
low precision, or vice versa.
Considerable efforts have been made to
develop alternative methods, e.g., based on simple word statistics,
but their practical applicability has been low.
We have recently developed quite a different scheme, an explorative
full-text information retrieval method and browsing tool called the
WEBSOM. It is based on the
Self-Organizing Map (SOM) algorithm [Kohonen, 1982, Kohonen, 1995, Kohonen et al., 1996a]
The SOM is a general unsupervised learning algorithm for analyzing and
visualizing high-dimensional statistical data.
We have applied the WEBSOM method for organizing Internet
newsgroup articles.
In the following, the WEBSOM method and browsing interface are
described, as well as some recent developments.
Consider that we would attempt to describe full-text documents by
their word histograms for their statistical clustering or
classification. A drawback
in that scheme is that for sufficient resolution of the contents, the
selected vocabulary ought to be very large, say,
of the order of 10 000
words. We have found that the documents can be effectively
represented by a much smaller feature set if the words are first
clustered into meaningful categories. Such an approximate clustering
can be made automatically by a "semantic SOM"
[Ritter and Kohonen, 1989, Ritter and Kohonen, 1990, Finch and Chater, 1992, Miikkulainen, 1993, Honkela et al., 1995]
to which the text is
input as short segments, e.g., triplets of successive words.
In our experiments, a group of related words are often mapped to each
node, thus portraying a kind of category or part of one.
The nodes of this SOM can thus be used to represent a
document as a histogram of its categorized words.
A typical dimensionality of the category histogram was
315 in our experiments.
The WEBSOM method thus has a two-level information processing
architecture. On the first level, a "semantic SOM" categorizes the
words of the source text into clusters. The second level uses these
clusters of the word category map
and creates an ordered display of the documents,
a document map.
Studies of document maps that are based on the application
of the SOM without an explicit
word category map have been published since
the beginning
of 1990s [Lin et al., 1991, Scholtes, 1991, Scholtes, 1992, Scholtes, 1993, Merkl et al., 1994, Merkl and Tjoa, 1994].
In WEBSOM, each document is represented on
the document map as a point in such a
way that the mutual distance between any two representation points
reflects the similarity of the corresponding
two histograms. Therefore similar documents become mapped close to
each other on the document map, like the books on the shelves of a
well-organized library.
The WEBSOM method is readily applicable to any kind of collection of
textual documents, even if theu were not provided with keywords.
We have
organized collections of as many as 100 000 documents on maps having
of the order of 10 000 nodes. The method is especially suitable for
exploration tasks in which the users either do not know the domain
very well, or they have only a limited idea of the contents of the
full-text database being examined. With the WEBSOM, the documents are
ordered meaningfully according to their contents. Maps help the
exploration by giving an overall visual view of what the information
space looks like. The basic levels of the WEBSOM interface
are shown in Fig.1.
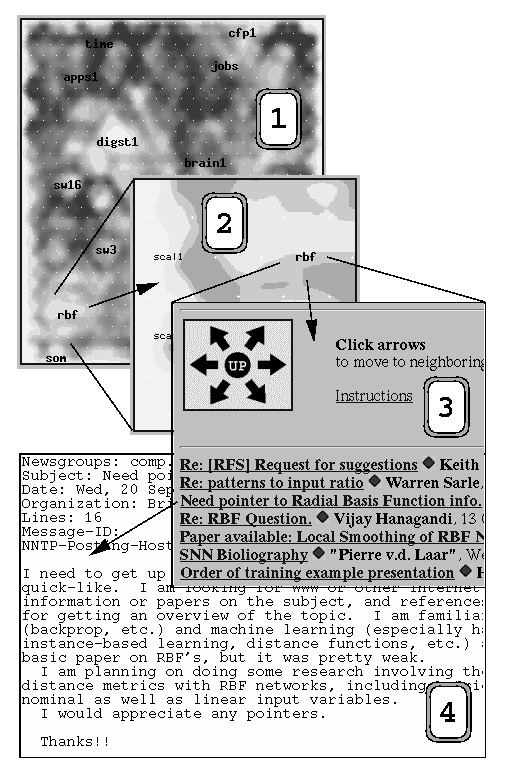
Figure 1: Basic levels of the WEBSOM interface:
(1) the whole map, (2) the
zoomed map, (3) the map node, and (4) the document view, presented in the
order of increasing detail. Moving between the levels or to
neighboring areas on the same level is done by mouse clicks on the
images or on the document links. Once an interesting area on the map
has been found, exploring the related documents in the neighboring
areas is simple.
The WEBSOM browsing interface is implemented as a set of HTML
documents that can be viewed using a graphical WWW browser at the
address http://websom.hut.fi/websom/
The Internet demonstration was made public at the 19th of January, 1996
along with a technical report that introduces
the basic method [Honkela et al., 1996b]. Various aspects of the
approach have been and will be presented in the following publications:
- The basic method for unsupervised processing of newsgroups
[Kaski et al., 1996].
- Partially supervised processing of a collection
of multiple Usenet newsgroups [Honkela et al., 1996a].
- The browsing interface implemented as World Wide Web pages
for exploration of document collections [Lagus et al., 1996b].
- The WEBSOM used as a method and a tool for data mining in
textual databases [Lagus et al., 1996a].
Recently, the basic method has been developed substantially.
The document maps presented in the first publications contained
under 1000 map nodes. The number of text files in a collection
was therefore restricted.
Methods for creating very large maps
are introduced in [Kohonen et al., 1996b]. The document map
of the reported experiments contains 49 152 map nodes.
Such large maps become computationally feasible by using
a shortcut winner search, and
estimation of
good initial values for a map that
has plenty of units on the basis
of asymptotic values
of a map with
a much smaller number of units.
A fraction of the large map is presented in Fig.2.

Figure 2: A fraction of a large map for 20 newsgroups. The total
number of the map units is 49 152. Newsgroups contained
31 000 000 words.
In addition to exploration tasks, the WEBSOM may also
be used for content-directed document search.
Any new document may be mapped onto the document map.
The map nodes
close to the position of the new document then most likely contain
related information.
The position of the new document on the document map provides
a starting point for exploring related documents.
The first version of this feature has recently been
implemented. The result of an sample query is presented
in Fig.3.
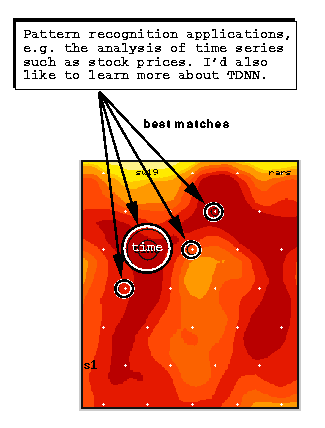
Figure 3: The result of a content-addressable search. The document
has been positioned on a map that contains discussion on artificial
neural networks. The area that was found is related to time-series prediction.
The best matching unit on the map is encircled with the largest circle. Also
the next closest matches are visualised
(some of them are not seen in this figure).
References
- Finch and Chater, 1992
-
Finch, S. and Chater, N. (1992).
Unsupervised methods for finding linguistic categories.
In Aleksander, I. and Taylor, J., editors, Artificial Neural
Networks, 2, pages II-1365-1368. North-Holland.
- Honkela et al., 1996a
-
Honkela, T., Kaski, S., Lagus, K., and Kohonen, T. (1996a).
Exploration of full-text databases with self-organizing maps.
In Proc. of International Conference on Neural Networks
(ICNN-96), volume 1, pages 56-61, Piscataway, NJ. IEEE.
- Honkela et al., 1996b
-
Honkela, T., Kaski, S., Lagus, K., and Kohonen, T. (1996b).
Newsgroup exploration with WEBSOM method and browsing interface.
Technical Report A32, Helsinki University of Technology, Laboratory
of Computer and Information Science, Espoo.
WEBSOM home page (1996) available at http://websom.hut.fi/websom/.
- Honkela et al., 1995
-
Honkela, T., Pulkki, V., and Kohonen, T. (1995).
Contextual relations of words in Grimm tales analyzed by
self-organizing map.
In Fogelman-Soulié, F. and Gallinari, P., editors,
Proceedings of the International Conference on Artificial Neural Networks,
ICANN-95, volume 2, pages 3-7, Paris. EC2 et Cie.
- Kaski et al., 1996
-
Kaski, S., Honkela, T., Lagus, K., and Kohonen, T. (1996).
Creating an order in digital libraries with self-organizing maps.
In (to appear): Proc. of World Congress on Neural Networks
(WCNN-96).
- Kohonen, 1982
-
Kohonen, T. (1982).
Self-organized formation of topologically correct feature maps.
Biological Cybernetics, 43:59-69.
- Kohonen, 1995
-
Kohonen, T. (1995).
Self-Organizing Maps.
Springer, Berlin.
- Kohonen et al., 1996a
-
Kohonen, T., Hynninen, J., Kangas, J., and Laaksonen, J. (1996a).
SOM_PAK: The self-organizing map program package.
Technical Report A31, Helsinki University of Technology, Laboratory
of Computer and Information Science, Espoo.
- Kohonen et al., 1996b
-
Kohonen, T., Kaski, S., Lagus, K., and Honkela, T. (1996b).
Very large two-level som for the browsing of newsgroups.
In (to appear): Proc. of International Conference on Artificial
Neural Networks.
- Lagus et al., 1996a
-
Lagus, K., Honkela, T., Kaski, S., and Kohonen, T. (1996a).
Self-organizing maps of document collections: A new approach to
interactive exploration.
In (to appear): Proc. of Knowledge Discovery and Data Mining
(KDD-96).
- Lagus et al., 1996b
-
Lagus, K., Kaski, S., Honkela, T., and Kohonen, T. (1996b).
Browsing digital libraries with the aid of self-organizing maps.
In Hopgood, B., editor, Proc. of Fifth International World Wide
Web Conference, volume posters, pages 71-79, Paris.
- Lin et al., 1991
-
Lin, X., Soergel, D., and Marchionini, G. (1991).
A self-organizing semantic map for information retrieval.
In Proceedings of the 14th Annual International ACM/SIGIR
Conference on Research & Development in Information Retrieval, pages
262-269.
- Merkl and Tjoa, 1994
-
Merkl, D. and Tjoa, A. M. (1994).
The representation of semantic similarity between documents by using
maps: Application of an artificial neural network to organize software
libraries.
In Proceedings of the General Assembly Conference and Congress
of the International Federation for Information and Documentation, FID'94.
- Merkl et al., 1994
-
Merkl, D., Tjoa, A. M., and Kappel, G. (1994).
A self-organizing map that learns the semantic similarity of reusable
software components.
In Proceedings of the 5th Australian Conference on Neural
Networks, ACNN'94, pages 13-16. Brisbane, Australia.
- Miikkulainen, 1993
-
Miikkulainen, R. (1993).
Subsymbolic Natural Language Processing: An Integrated Model
of Scripts, Lexicon, and Memory.
MIT Press, Cambridge, MA.
- Ritter and Kohonen, 1989
-
Ritter, H. and Kohonen, T. (1989).
Self-organizing semantic maps.
Biological Cybernetics, 61:241-254.
- Ritter and Kohonen, 1990
-
Ritter, H. and Kohonen, T. (1990).
Learning 'semantotopic maps' from context.
In Proceedings of the International Joint Conference on Neural
Networks, IJCNN-90-Washington-DC, volume I, pages 23-26, Hillsdale, NJ.
Lawrence Erlbaum.
- Scholtes, 1991
-
Scholtes, J. C. (1991).
Kohonen feature maps in full-text data bases: A case study of the
1987 Pravda.
In Proc. Informatiewetenschap 1991, Nijmegen, pages 203-220,
Nijmegen, Netherlands. STINFON.
- Scholtes, 1992
-
Scholtes, J. C. (1992).
Neural nets for free-text information filtering.
In Proceedincs of 3rd Australian Conference on Neural Nets,
Canberra, Australia, February 3-5.
- Scholtes, 1993
-
Scholtes, J. C. (1993).
Neural Networks in Natural Language Processing and Information
Retrieval.
PhD thesis, Universiteit van Amsterdam, Amsterdam, Netherlands.
This document was generated using the LaTeX2HTML
translator Version 96.1 (Feb 5, 1996) Copyright © 1993, 1994,
1995, 1996, Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Krista Lagus
Wed Jul 10 11:58:36 DST 1996