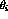 now presenting
the `codebook' vector in the node i, where
now presenting
the `codebook' vector in the node i, where 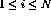 , and vector
f presents the input data. The iterative process of adapting the
self-organizing feature network consists of the following steps:
, and vector
f presents the input data. The iterative process of adapting the
self-organizing feature network consists of the following steps:
Heikki Hyötyniemi
Helsinki University of Technology
Control Engineering Laboratory
Otakaari 5A, FIN-02150 Espoo, Finland
A PostScript version of this paper is available also at
http://www.hut.fi/~hhyotyni/HH3/HH3.ps
The huge number of textual documents available in electronic form emphasizes the need of intelligent information retrieval systems. The traditional text search methods are based on more or less sophisticated keyword search strategies. The problem of finding good sets of key terms is a difficult practical task, specially if the idea of the object area is vague.
Self-organizing maps [4] offer an intuitively appealing way to model and represent complex data, and this approach has been applied also for constructing so called semantic maps (see [5]). An outstanding application of this idea is the Internet newsgroup classifier WEBSOM [2].
In WEBSOM, the words in a document are taken apart, preprocessed (the most common words being ignored), and coded in some special way (to be presented as 90 dimensional binary vectors). The three-word sequences, resulting in 270 dimensional feature vectors, are input in a self-organizing map to get some kind of a text context map. Each document will then be located in a unique node in the net. However, the texts usually have connections to various different directions. How can the two-dimensional map present all of the contextual dimensions of a text?
As presented in [3], the self-organization principle can be extended to modeling sequences of input features. The input vectors are decomposed into additive vector components, `features', that can be used as basis vectors for spanning the space of the input vectors. This GGHA algorithm can also be regarded as a sparse coding technique.
Assume that the neural network to be discussed has the structure of a
traditional self-organizing network, vector now presenting
the `codebook' vector in the node i, where , and vector
f presents the input data. The iterative process of adapting the
self-organizing feature network consists of the following steps:
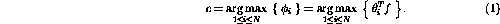
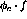 as input (here,
as input (here, 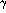 is the adaptation factor, and
is the adaptation factor, and
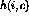 is the parameter determining the network topology, as presented
in [4]):
is the parameter determining the network topology, as presented
in [4]):
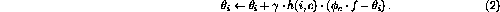


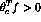 and index c has not yet been used;
etc.), go back to Step 2, otherwise, go to Step 1.
and index c has not yet been used;
etc.), go back to Step 2, otherwise, go to Step 1.
In [3], GGHA was applied to extracting features of digitized photographs. In this paper, the application area is text document coding and retrieval.
Scholtes [6] has shown how text documents can efficiently be coded in a contents-independent manner. The idea is to use `trigrams', sequences of three successive letters, as basic elements characterizing a document. The frequency of the trigrams alone is assumed to carry all the essential information! Even if the trigram distribution in a text is admittedly a crude model of the document contents, it turns out that this representation manages to capture many useful properties of a document. The nice feature about the trigrams is that very little preprocessing of the documents is needed; inflected and compound words (being characteristic to some special languages, like Finnish) are neither a problem. The number of trigrams is finite---this is a major advantage, making it possible to represent them in a compact way.
In WEBSOM, on the other hand, when whole words are used as entries, the
linguistic problems may become acute. Additionally, when the huge
number of words is to be coded in a limited number of bits, the codes
will be overlapping, so that the words will no more be `orthogonal'.
This can be difficult during the adaptation of the map. As argued
above, each document will have just one location on the WEBSOM map.
Using the new algorithm, on the other hand, many nodes contribute, each
adding a new `flavor' to the result, the contribution being determined
by the factors 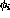 .
.
The new algorithm can be thought of as being an automated way of finding optimal keywords. These `keywords' are now not words, but collections of most frequent letter combinations. The user, letting the network adapt according to texts he/she is interested in, will have a `filter' that can be used to automatically extract the feature coordinates characterizing the new document in his/her own `interest space'!
The presented method was experimented with a collection of 40 text
documents, most of them being research reports, some in Finnish, some in
English. The trigrams were simplified by eliminating special
characters---only alphabetic letters written in lowercase,
and single `white space' characters were processed. The
characters that are characteristic to Finnish language were also included.
Each trigram, say, `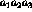 ', where
', where 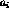 are characters,
was coded as a unique integer
are characters,
was coded as a unique integer 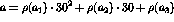 , where
, where
SPC>
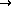
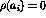
`a'
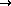
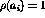

`z'
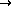
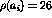
`å'
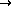
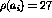
`ä'
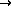
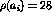
`ö'
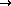
.
The `fingerprint' of a document was a 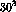 dimensional vector,
constructed by incrementing the element a in the vector each time the
corresponding trigram number a was found. Finally, the fingerprint
vector was normalized to have unit length.
dimensional vector,
constructed by incrementing the element a in the vector each time the
corresponding trigram number a was found. Finally, the fingerprint
vector was normalized to have unit length.
The network consisted of 16 nodes, and sequences of four features were extracted. To make the features better distinguishable, the input vector was normalized (divided by the vector length) after each feature extraction step, contrary to the theoretical derivations. The documents were the following:
1: "Coupling Expert Systems on Control Engineering Software"2: Song texts 1---wedding party (in Finnish)
3: Special work description 1 (in Finnish)
4: Scholarship application (in Finnish)
5: Special work description 2 (in Finnish)
6: Special work description 3 (in Finnish)
7: Song texts 2---dissertation celebration (in Finnish)
8: IEC standard description (in Finnish)
9: Project plan (in Finnish)
10: ANSI standard description
11: Program documentation
12: Bug report README file
13: Commercial correspondence
14: Astronomical article 1
15: Business report 1
16: Astronomical article 2
17: Business report 2
18: "Self-Organizing Maps for Dynamic Process Modeling"
19: "Locally Controlled Optimization of Spray-Painting Robot Trajectories"
20: "Optimal Control of Dynamic Systems Using Self-Organizing Maps"
21: "Towards Portability of Knowledge in Control Systems Design"
22: "Postponing Chaos Using a Robust Stabilizer"
23: "`Hypertechniques' in Control Engineering Education"
24: "A Universal Relation Database Interface for Knowledge Based Systems"
25: "`Mode Maps' in Process Modeling"
26: "Automating the Modeling of Dynamic Systems"
27: Description of a modeling system
28: "Constructing Non-Orthogonal Feature Bases"
29: "State-Space Modeling Using Self-Organizing Maps"
30: "Self-Organizing Maps for Engineering Applications"
31: "Recursive Parameter Estimation---`Congruent Systems' and Identifiability"
32: "Information Content Weighting of Algorithms"
33: "Applying Computers in Dynamic Systems Courses"
34: "Improving Robustness of Parameter Estimation"
35: "CES---A Tool for Modelling of Dynamical Systems"
36: "CoreWars---A Testbench for Artificial Life?"
37: "Computer-Aided Education of Control Engineers"
38: "Symbolic Calculation and Modeling Tools" (in Finnish)
39: Laboratory excercise instructions (in Finnish)
40: "Self-Organization and Causal Relations (in Finnish)
Above, quoted texts mean article titles; emphasized texts are written in LaTeX, meaning that special directives exist in the text body. The lengths of the documents varied from one page to dozens of pages.
When the GGHA algorithm was applied, with the fingerprints of the 40 documents being used repeatedly as the input, the converged 16 features spanned the space of the documents in the following way:

In the above table, the coordinates of the 40 documents are shown (the
actual values of  are multiplied by 100). The last column
presents the `error', or the length of the residual document fingerprint
vector, after the feature vectors have been extracted---this value can
be used for measuring how well a document can be presented in the
constructed feature basis.
are multiplied by 100). The last column
presents the `error', or the length of the residual document fingerprint
vector, after the feature vectors have been extracted---this value can
be used for measuring how well a document can be presented in the
constructed feature basis.
In the resulting map, some of the features were easily identifiable---for example, the languages (English represented by the node 15 and Finnish in the node 7) have clearly distinguishable fingerprints (see Fig. 1). The feature contents can be visualized by showing the sequences of trigrams that are the most frequent. For example, if the `threshold' is 0.08, meaning that the trigram entry in the feature vector has to exceed that value, the following letter combinations characterize the node 15:
the, ing, in, of, co*, to, and, be*, is. These are the most common letter sequences in the English language, so that this node can really be labeled correspondingly. On the other hand, if the threshold is only 0.03, the number of sequences grows rapidly. Because only three-letter combinations are saved, with no information about the textual environment, `pseudo English' letter sequences are generated:
the, ther, there, theres, theress*, thation,
thations, that, thater, thatere, thateres,
thateress*, thate, thated, thatem, ...
All documents![]() were first divided
in two classes according to the language.
Some keywords (`neural', for
example, presented as trigrams ` ne', `neu', `eur', etc.) could also be
spotted in the appropriate nodes. In general, however, the feature
vectors did not necessarily have any straightforward interpretation.
were first divided
in two classes according to the language.
Some keywords (`neural', for
example, presented as trigrams ` ne', `neu', `eur', etc.) could also be
spotted in the appropriate nodes. In general, however, the feature
vectors did not necessarily have any straightforward interpretation.
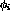
Figure 1: The prototypical `fingerprints' of the two
languages (English on the top, Finnish on the bottom). The coordinate values
on the horizontal axis are in thousands; the vertical axis represents the
normalized probabilities of the trigrams. The peaks in the English
fingerprint are located at ` th', `the', etc.
It is clear that texts differing a lot from others are separately classified: song lyrics (documents 2 and 7 in the node 5), astronomical articles (documents 14 and 16 in the node 14), and the business oriented texts (documents 13, 15, and 17 in the 16), for example, were clearly classified in their own categories. The node 8 seems to represent papers about self-organizing networks, and the node 2 contains texts about educational aspects.
As a test, a document that had not been seen by the adaptation algorithm (namely, this text) was input in the net, and the classification result was the following:
It seems that the system has classified the paper as being about self-organization (node 8) and education (node 2), written in English (node 15). The residual error value 0.48 is relatively high, revealing that this paper is original---there were no other texts on document manipulation.
Applications of the presented approach could easily be found. A network agent, browsing through the documents in the Internet, was already mentioned. But user profiling can be realized also by the provider of a network service---news, or other textual material, could be organized and prioritized by the supplier according to the needs of the customers.
The current implementation of the algorithm is straightforward but rather inefficient. The fingerprint vectors, as well as the feature vectors, are very high-dimensional, even if, in practice, they are rather sparse (at most 5 percent of the fingerprint vector elements are non-zero). A simple optimization scheme is to disgard the least significant elements, and only store the most significant ones.
The sequences of principal vectors are usually distinct---for example, texts in English and Finnish will usually have no common features after elimination of the most significant feature (even if the words `neural' and `neuraali', in English and in Finnish, respectively, do have common trigrams). That is why, storing the different feature sequences in the same network results in disturbances in the features. The generality of the one-level map should perhaps be relaxed---a tree structure, consisting of hierarchical layers of self-organizing maps for different levels of features, would perhaps be more appropriate in practical applications.
This research has been financed by the Academy of Finland, and this support is gratefully acknowledged.
Text Document Classification with Self-Organizing Maps
This document was generated using the LaTeX2HTML translator Version 95.1 (Fri Jan 20 1995) Copyright © 1993, 1994, Nikos Drakos, Computer Based Learning Unit, University of Leeds.
The command line arguments were:
latex2html -split 0 -show_section_numbers HH3.tex.
The translation was initiated by Heikki Hy|tyniemi on Mon Aug 26 13:10:41 EET DST 1996