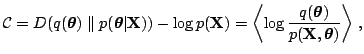Variational Bayesian (VB) learning techniques are based on approximating the true posterior probability density of the unknown variables of the model by a function with a restricted form. Currently the most common technique is ensemble learning [8] where Kullback-Leibler divergence measures the misfit between the approximation and the true posterior. It has been applied to ICA and a wide variety of other models (see [1,9] for some references).
In ensemble learning, the posterior approximation
![]() of the
unknown variables
of the
unknown variables
![]() is required to have a suitably factorial form
is required to have a suitably factorial form
![]() , where
, where
![]() are the subsets of unknown variables. The misfit
between the true posterior
are the subsets of unknown variables. The misfit
between the true posterior
![]() and its approximation
and its approximation
![]() is measured by Kullback-Leibler divergence. An additional
term
is measured by Kullback-Leibler divergence. An additional
term
![]() is included to avoid calculation of the model
evidence term
is included to avoid calculation of the model
evidence term
![]() . The cost function is
. The cost function is
The missing values in data behave like other latent variables and are
therefore handled as a part of
![]() instead of
instead of
![]() . The posterior
approximation
. The posterior
approximation
![]() is estimated during the learning and it can be
used as a reconstruction for the missing values. The fraction of
missing values in the data does not affect computational complexity
substantially.
is estimated during the learning and it can be
used as a reconstruction for the missing values. The fraction of
missing values in the data does not affect computational complexity
substantially.
Beal and Ghahramani [10] compare the VB method of handling incomplete data to annealed importance sampling (AIS). In their example, the variational method works more reliably and about 100 times faster than AIS. Chan et al. [11] used ICA with VB learning successfully to reconstruct missing values. A competing approach without VB by Welling and Weber [12] has an exponential complexity w.r.t. the data dimensionality. ICA can be seen as FA with a non-Gaussian source model. Instead of going into that direction, we choose to stick to the Gaussian source model and concentrate on extending the mapping to be nonlinear instead.