Miquel Perello Nieto

Miquel Perelló Nieto
M.Sc. Student - Researcher Assistant
- Office:
-
Room B310 in Computer Science Building,
Konemiehentie 2, Otaniemi campus area, Espoo - Postal Address:
-
Aalto University School of Science,
Department of Information and Computer Science,
P.O. Box -----, FI-00076 Aalto, Finland - Telephone:
- +358 44 920 2968
- Email:
- firstname dot perellonieto at aalto dot fi
New !
(07/08/2015) Added new Section Deep Dreams:
Deep dreams
This section shows a video with all the layers of a deep nerual network and one selected frame per layer. The Convolutional Neural Network has been pretrained with ImageNet. The first input image is a picture of myself and at every step the image is zoomed with a ratio of 0.05. At every step the actual input image (frame) is forwarded to the actual hidden layer. The error is set to be the same representation in order to maximize all its activations. Then, a backward pass is computed to modify the input image. After 100 iterations of zooming in one layer, the next layer is used.
(13/11/2014) Added new section in Tutorial:
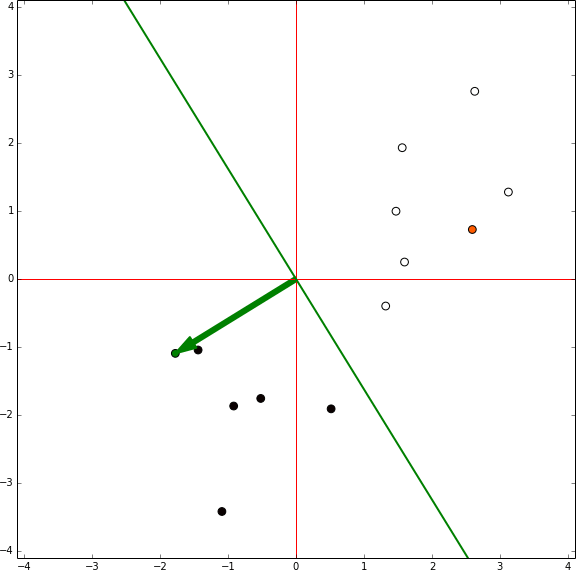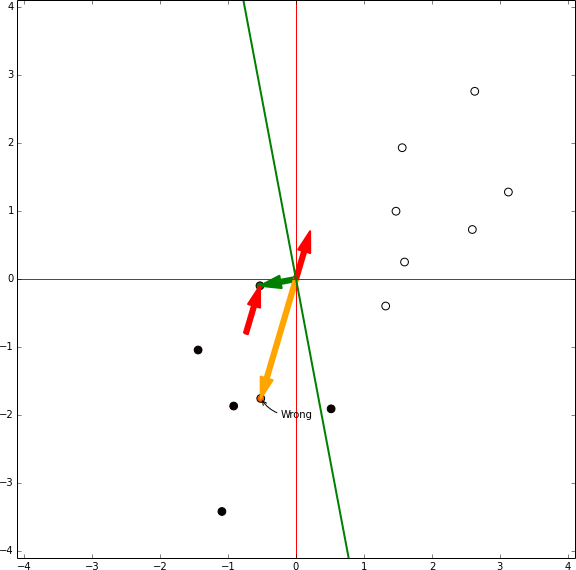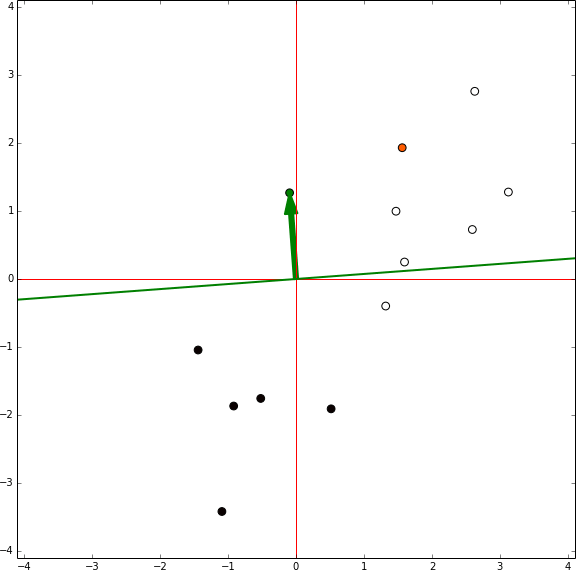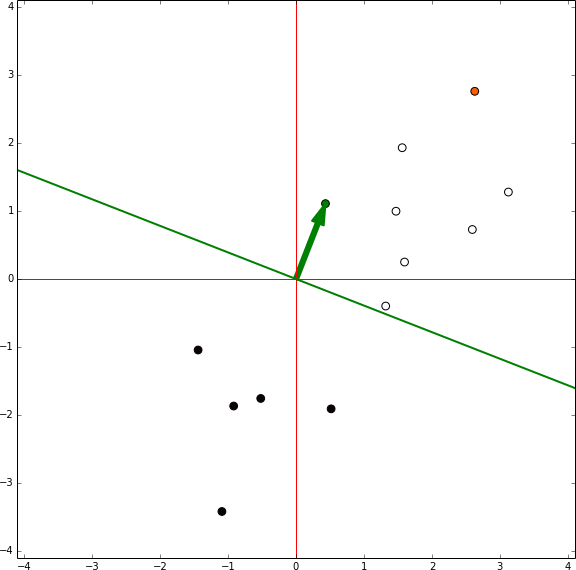
Perceptron training
In this representation there is no bias involved, the green arrow are the model weights and it defines an hyperplane orthogonal to them centred in the coordinates [0,0]. In each iteration the sample being tested is shown in orange. If the sample is in the wrong side of the hyperplane the vector representing the sample is shown, then the red vector is the same vector reescaled by the learning rate and it is summed to the weights vector. Then, the next sample is tested.