

Next: 2. Experiment 1: VQ(A+B+C).
Up: 4. Experiments
Previous: 4. Experiments
As a data set we used features from 1000 images that have been used
for content-based image retrieval in [6]![[*]](foot_motif.gif) . Each image is represented by a vector of 144
features (variables). The features fall naturally into three
categories related to their origin: FFT, RGB, and texture. It is
reasonable to assume that dependences between variables in different
categories are weak.
Thus, the data provides an ideal validation for
both the
. Each image is represented by a vector of 144
features (variables). The features fall naturally into three
categories related to their origin: FFT, RGB, and texture. It is
reasonable to assume that dependences between variables in different
categories are weak.
Thus, the data provides an ideal validation for
both the
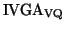 algorithm as well as the general IVGA approach. For
the experiments we chose randomly a subset of 50 features: the
variable set A consisted of 27 FFT features (numbered 1-27 below), B
of 7 RGB features (28-34) and C of 16 texture features (35-50).
algorithm as well as the general IVGA approach. For
the experiments we chose randomly a subset of 50 features: the
variable set A consisted of 27 FFT features (numbered 1-27 below), B
of 7 RGB features (28-34) and C of 16 texture features (35-50).
Krista Lagus
2001-08-28